개요
자바에는 컬렉션(Collection Framework)가 다양하고 각각의 자료 저장 방식과 연산 성능 특성이 다르다.
이는 성능과 코딩테스트에서 정답 여부에 직결되기 때문에 컬렉션의 종류에 대해 정리를 하려고 한다.
자료 구조(Data Structure)
- 데이터에 효율적으로 접근하기 위해 선택되는 데이터의 조직 및 저장 형식
- 데이터 값들의 모음, 이들 간의 관계, 데이터에 적용될 수 있는 연산의 모음
자료 구조의 분류
- 정적 자료구조(Static Data Structure) : 크기가 고정된 자료 구조(예 : 배열)
- 동적 자료구조(Dynamic Data Structure) : 크기가 변할 수 있는 자료구조 (예 : 리스트, 스택, 큐)
자료 구조의 선택 기준
- 데이터 접근 속도
- 메모리 사용 효율성
- 삽입 및 삭제의 효율성
- 순서 유지 여부
- 중복 데이터 허용 여부
Array
int[], int[][]
특징
- 크기 고정이며, 인덱스로 즉시 접근이 가능하다.
- 성능 예측이 쉽다.
장점
- 임의 접근이 O(1)로 빠르다.
- 메모리 오버헤드가 작다.
- 방문 배열, DP 테이블에서 안정적이다.
단점
- 크기 변경이 불가능하다.
- 중간 삽입/삭제가 어렵다. (새 배열 생성 후 복사)
언제 쓰는가
- DP, 누적합, 방문 체크, 격자, 정적 크기 입력 처리
주요 메서드
Arrays.sort(a);
Arrays.fill(a, value);
Arrays.copyOf(a, newLen);
Arrays.toString(a);
Arrays.deepToString(grid);
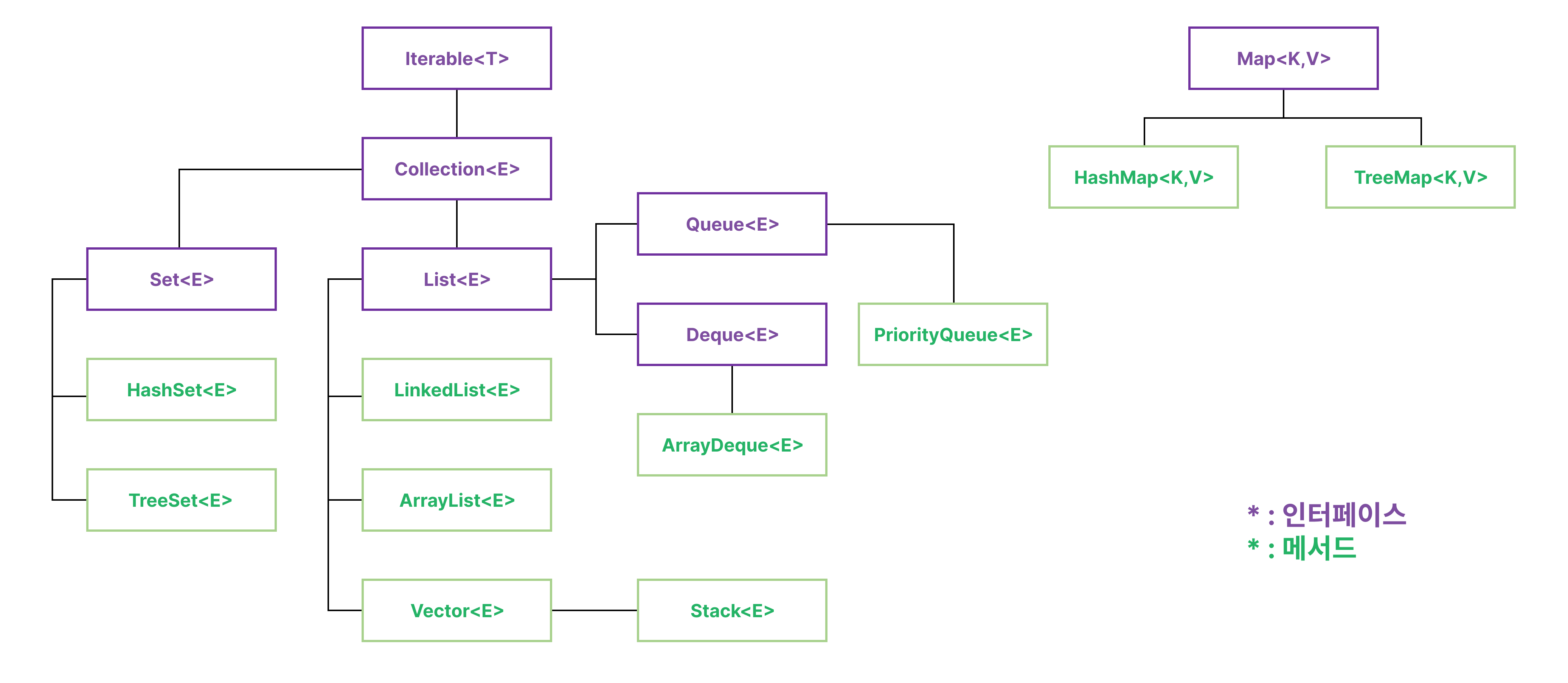
컬렉션 프레임워크(Collection Framework)
- 표준화된 데이터 구조와 이를 처리하기 위한 클래스 및 인터페이스의 집합
- 데이터를 동적 크기로 관리하고, 삽입, 삭제, 검색, 정렬 등을 효율적으로 처리할 수 있음
- 제네릭을 지원하여 타입 안전성 보장
- 표준화된 메서드 제공
컬렉션 주요 인터페이스 및 구현 클래스
ArrayList
List<int[]>[] g = new ArrayList[N+1];
특징
- 내부적으로 배열을 사용하며, 크기를 자동 확장한다.
- 인덱스 기반 접근이 빠르다.
장점
get(i)가 O(1)로 빠르다.- 정렬 및 순회가 편리하다.
- 인접 리스트 그래프 구성에 적합하다.
단점
- 중간 삽입/삭제는 요소 이동 때문에 O(n)이다.
contains가 O(n)이므로 빠른 존재 확인이 목적이면 부적합하다. (대신 Set/Map)
언제 쓰는가
- 그래프 인접 리스트, 정렬 대상 목록, 가변 길이 입력
주요 메서드
list.add(x); // 추가
list.add(index, x); // 특정 위치에 삽입
list.remove(index); // 인덱스로 삭제
list.remove(Integer.valueOf(5)); // 값으로 삭제
list.sort((x,y) -> Integer.compare(x[0], y[0]));
Collections.sort(list);Queue/Deque: ArrayDeque
Queue<int[]> q = new ArrayDeque<>();
특징
- 배열 기반 원형 버퍼로 구현된 덱(Deque)이다.
- 큐/덱 연산이 빠르다.
장점
- offer/poll/peek, addFirst/removeLast 등이 O(1)이다.
- BFS에서 표준 선택에 가깝다.
단점
- 인덱스 접근이 불가능하다.
- 중간 삽입/삭제에는 적합하지 않다.
언제 쓰는가
- BFS, 최단거리, 레벨 탐색, 슬라이딩 윈도우 덱
주요 메서드
q.offer(x); // 추가
q.poll(); // 삭제
q.peek(); // 확인PriorityQueue
PriorityQueue<int[]> pq = new PriorityQueue<>(
// a[1] 오름차순
(a, b) -> Integer.compare(a[1], b[1]);
);특징
- 힙 기반으로 가장 작은(또는 큰) 원소를 빠르게 꺼낸다.
- 전체 정렬이 아니라 Top 원소만 보장한다.
장점
poll()로 최솟값(또는 최댓값)을 O(log n)에 얻는다.- 다익스트라/스케줄링에 필수적이다.
단점
- 삽입/삭제가 O(log n)이라 큐보다 느리다.
- 전체 정렬 결과가 필요하면 별도 정렬이 필요하다.
언제 쓰는가
- 다익스트라, 최소 비용 추출 반복, K번째 원소, 병합 비용 최소화
주요 메서드
pq.offer(x); // 추가
pq.poll(); // 삭제
HashSet
특징
- 중복을 허용하지 않는 집합이며, 평균 O(1)로 원소 존재 확인이 가능하다.
장점
contains가 평균 O(1)이다.- 중복 제거/방문 체크에 매우 유용하다.
단점
- 순서/정렬이 없다.
언제 쓰는가
- 문자열/좌표 방문 체크, 중복 제거, 빠른 membership 테스트
주요 메서드
set.add(x); // 추가
set.remove(x); // 삭제
set.contains(x); // 조회
set.clear(); // 비우기
set.size(); // 크기HashMap
특징
- Key-value 매핑이며, 평균 O(1)로 조회/삽입이 가능하다.
장점
- 빈도수 카운팅이 매우 편리하다.
- 좌표 압축, 인덱스 매핑 등에 유용하다.
단점
- 메모리 사용량이 큰 편이다.
- 정렬된 순서를 제공하지 않는다.
언제 쓰는가
- 빈도수, 그룹핑, 문자열 처리, 인덱스 매핑
주요 메서드
map.put(k, v); // 추가
map.get(k); // 조회
map.remove(k); // 삭제
map.remove(k, value); // key-value가 둘 다 일치할 때만 삭제TreeSet / TreeMap
특징
- Red-Black Tree 기반으로 원소/키가 항상 정렬된 상태를 유지한다.
- ceiling/lower/floor/higher 등 근접 원소 탐색이 가능하다.
장점
- 정렬 유지 + 탐색이 O(log n)으로 가능하다.
- 범위 기반 질의에 유리하다.
단점
HashSet/HashMap대비 느리다(log n)- 구현이 무겁고 상수항이 커서, 정렬 유지가 필요 없으면 비효율적이다.
언제 쓰는가
- 이 값 이상 중 최소값(ceiling)같은 질의가 반복되는 문제
- 정렬된 상태 유지가 필수인 문제
주요 메서드
// TreeSet
ts.add(x); // 추가
ts.remove(x); // 삭제
ts.contains(x); // 조회
ts.lower(x); // x보다 작은 최대
ts.floor(x); // x 이하 최대
ts.ceiling(x); // x 이상 최소
ts.higher(x); // x보다 큰 최소
ts.first(); // 최솟값
ts.last(); // 최댓값
// TreeMap
tm.put(k, v); // 추가
tm.get(k); // 조회
tm.remove(k); // 삭제
tm.lowerKey(x); // x보다 작은 최대
tm.floorKey(x); // x 이하 최대
tm.ceilingKey(x); // x 이상 최소
tm.higherKey(x); // x보다 큰 최소
tm.firstKey(); // 최솟값
tm.lastKey(); // 최댓값요약
BFS -> ArrayDeque
다익스트라 -> PriorityQueue
방문/중복 -> HashSet
빈도수/매핑 -> HashMap
정렬 유지 + 근접 탐색 -> TreeSet / TreeMap
LinkedList를 안 적은 이유
코테에서는 LinkedList를 잘 안 쓴다.
LinkedList를 잘 사용하지 않는 이유는 다음과 같다.
조회 속도 차이: LinkedList는 노드가 메모리에 흩어져 있어 다음 노드를 따라가며 접근해야 한다.
CPU 캐시 효율이 떨어져서 같은 O(1)이라도 조회 속도 차이가 난다.
메모리 오버헤드: LinkedList는 각 요소마다 이전/다음 노드의 주소값을 저장해야 하므로 메모리를 더 많이 사용한다.
