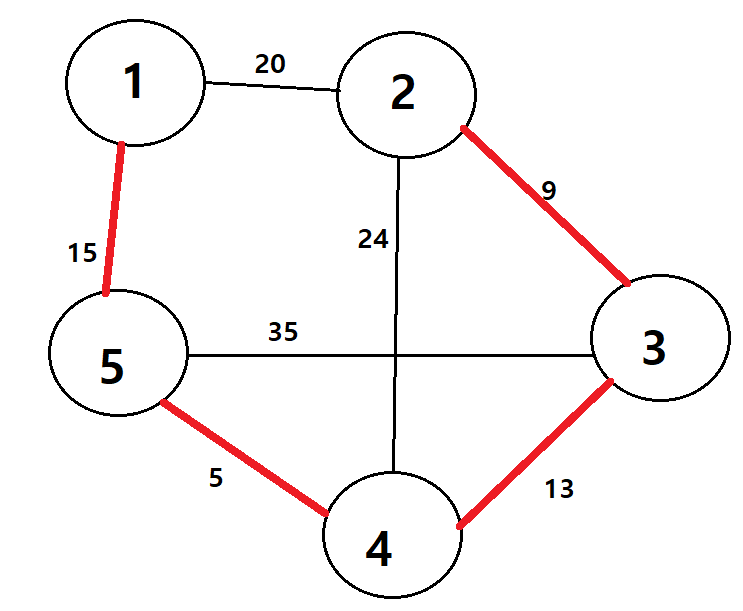
최소 신장트리에 대해 알기전에, 우선 신장트리의 개념에 대해 알아보자
🔹 신장트리 (Spanning Tree)
- 그래프의 모든 정점을 포함하면서 사이클이 존재하지 않는 부분 그래프를 의미한다
- 형태와 관계없이 모든 정점을 사이클 없이 이을 수 있으면 그것이 바로 신장트리이다
-> 아래의 그림을 보면 A B C D E 모든 정점을 포함하고 있으며 사이클이 발생하지 않는다신장트리 이전의 원래 그래프 내에서는 사이클이 존재할 수 있다
신장 트리는 부분 그래프이기 때문에. 실제 그래프 내에서 간선을 연결하여 만든 부분이다
-> 아래의 초기 그래프는 무방향 그래프이고 사이클을 갖고있다
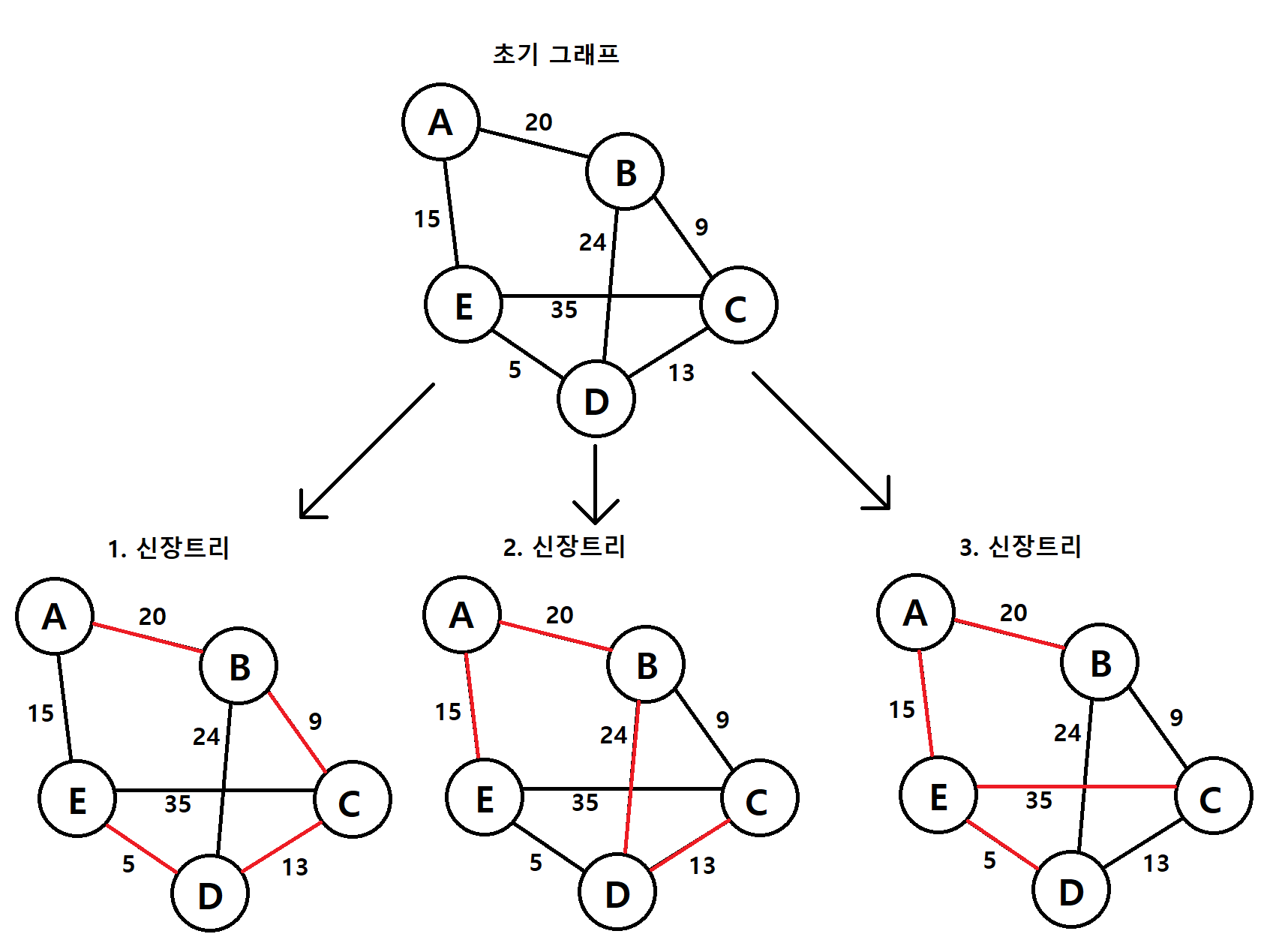
🔹 최소 신장 트리
- 그래프의 모든 정점을 최소 비용으로 연결하는 트리이다
(모든 정점 포함, 사이클이 존재하지 않게) - 간선마다 가중치를 가지고 있고, 이 가중치의 합이 최소가 되게 하는 트리이다
- 정점 N개를 연결하려면 N - 1개의 간선이 필요하다
-> 간선의 갯수가 N - 1개가 넘어가버리면 바로 사이클이 생긴다간선의 갯수가 N - 1개가 넘어가버리면 바로 사이클이 생긴다
최소 신장 트리 방법 2가지
-
크루스칼 알고리즘
간선을 가중치를 기준으로 정렬한 뒤 사이클이 생기지 않으면 간선을 추가하는 방식 -
프림 알고리즘
크루스칼 알고리즘
구현 순서
- 간선을 가중치를 기준으로 오름차순 정렬한다
- 최소 신장트리에 사이클이 생기지 않으면 간선을 추가한다
이 방법에서 탐욕법을 사용한다
- 탐욕법은 부분 선택이 전체의 최적의 해를 만드는 방법으로 진행되는 곳에서 사용하는 것이 좋은데(탐욕 선택 속성),
크루스칼 알고리즘에선 가중치가 가장 작은 간선부터 차례대로 선택한다
-> 최소 가중치 간선만 선택하다보면 (부분 문제 해)
-> 최종적으로 최소 신장트리가 된다 (전체 문제 해)
유니온 파인드를 사용하여 구현
(부모배열로 root노드를 파악하기 위함)
-
초기 그래프에서 정점과 간선의 정보를 벡터배열에 저장한 뒤, 가중치를 기준으로 정렬한다
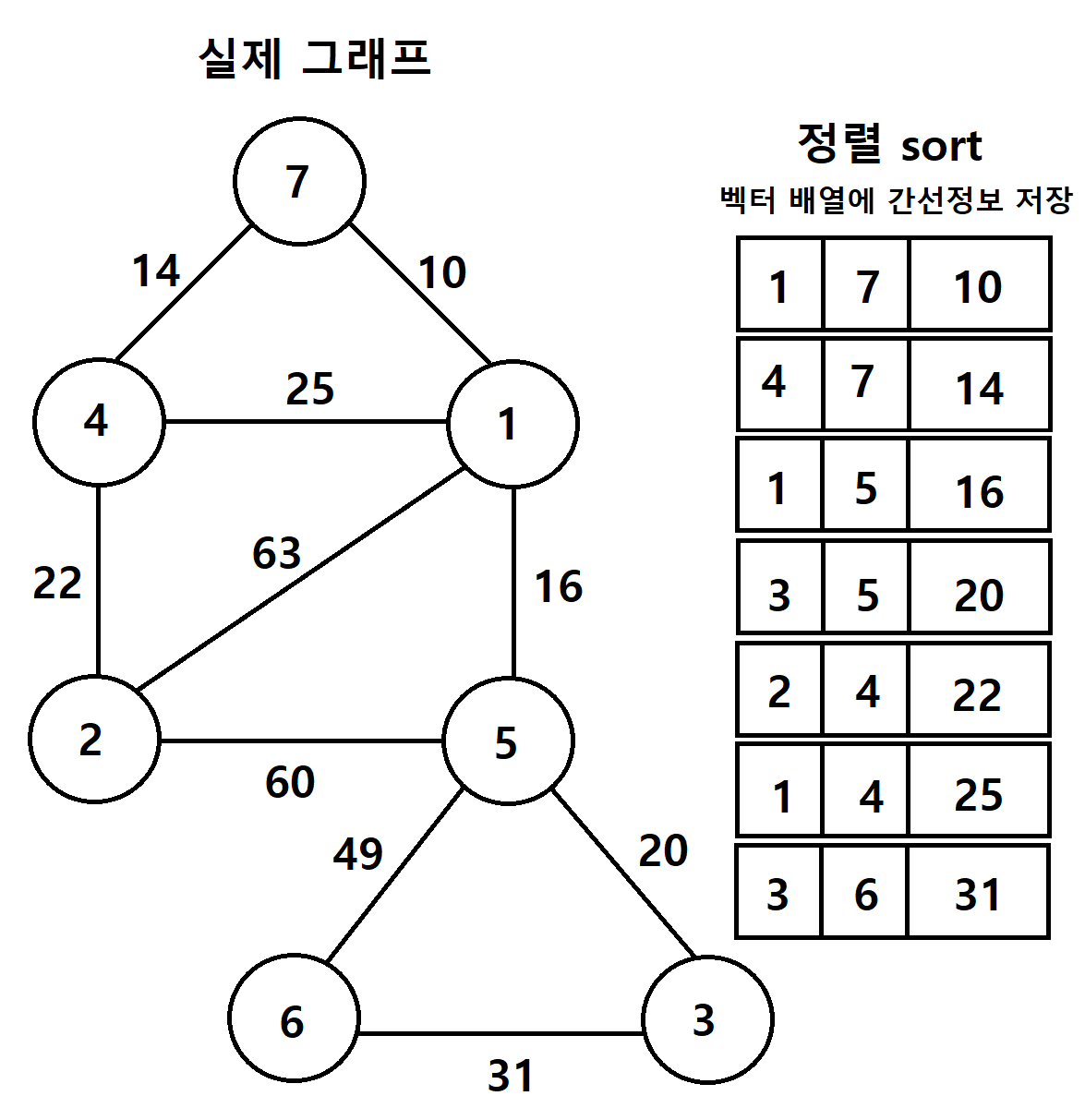
-
Union함수를 사용하여 두 정점을 연결한다
-> 부모배열을 같은 root노드로 갱신하는 작업이다
-> 앞에서 배운 유니온 파인드를 사용하여 두 정점을 연결하고, 부모노드를 갱신시킨다
https://velog.io/@yangju058/알고리즘-Union-FInd
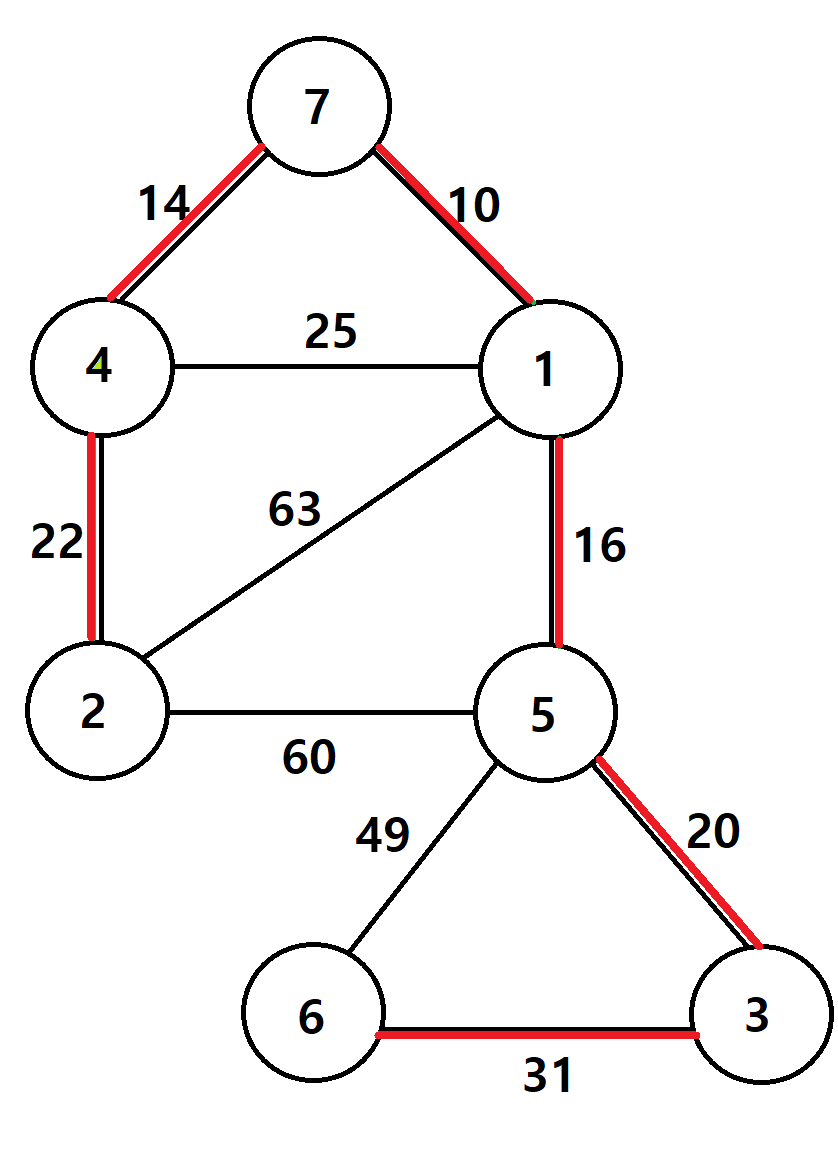
2-1. 최소 간선부터 두 정점을 비교한 뒤, 서로 다른 집합에 속하면 바로 Union함수를 이용해 연결한다
-> 과정이 길어서 생략하였다
-> 현재 6을 제외한 나머지가 모두 같은 집합상태임
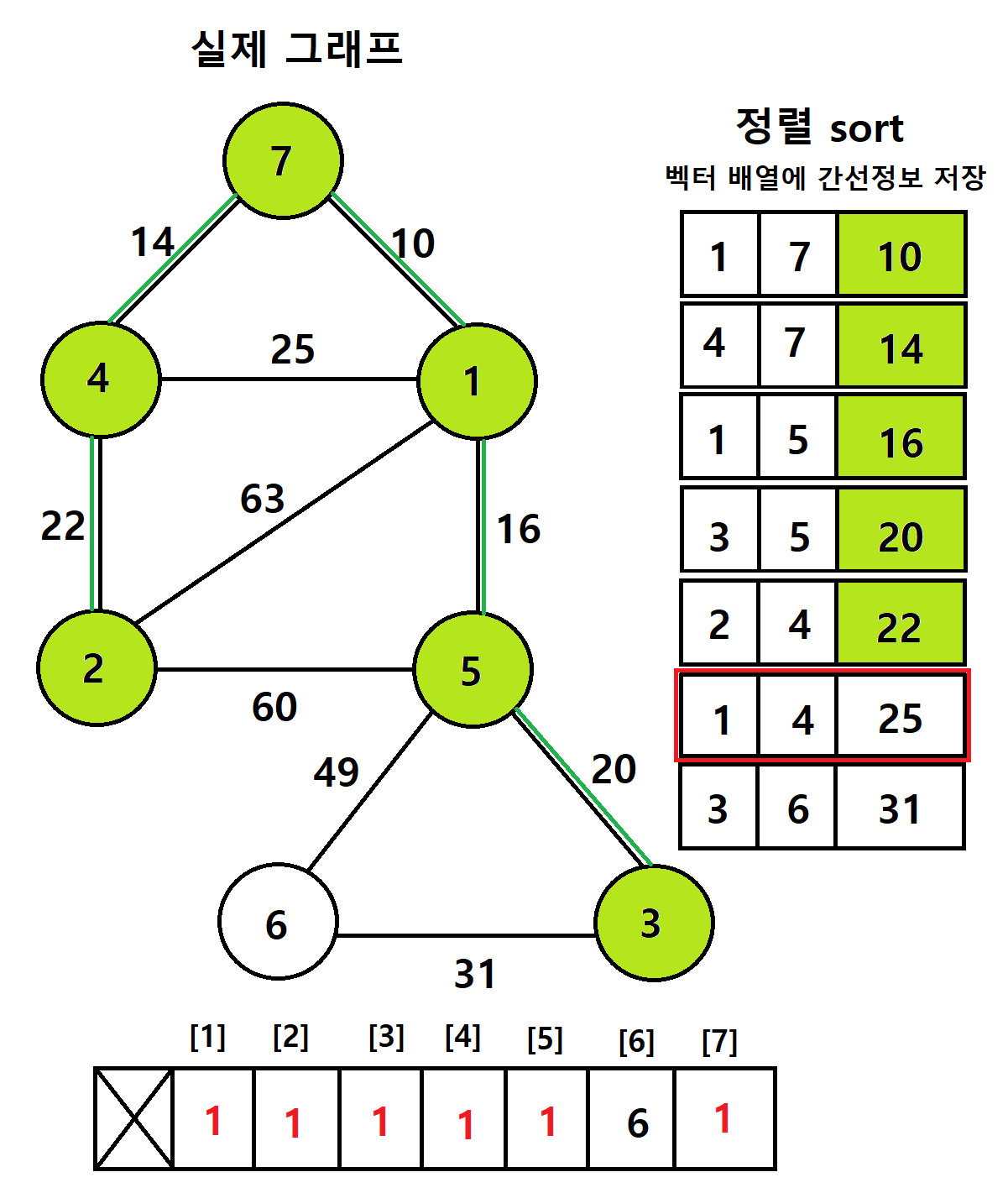
- 다음으로 연결할 간선의 가중치는 25이다
-> 정점 1과 4를 연결해야하는데, 두 정점의 부모배열이 서로 같다
-> 두 정점은 서로 같은 집합 상태이다
-> 부모노드가 서로 같은 상태에서 연결하면 사이클이 발생하기 때문에 이 간선은 건너뛰기즉, 부모노드가 서로 다르다는 것은 사이클이 발생하지 않는 것 (서로 다른 집합이기 때문에)
-> 정점 4는 7을 통해 간접적으로 1과 연결되어있다
-> 1과 직접적으로 연결되어 부모배열이 같아진 것이 아니지만, 7을 통해서 부모배열이 1이 된 것
-> 같은 집합이 된 것
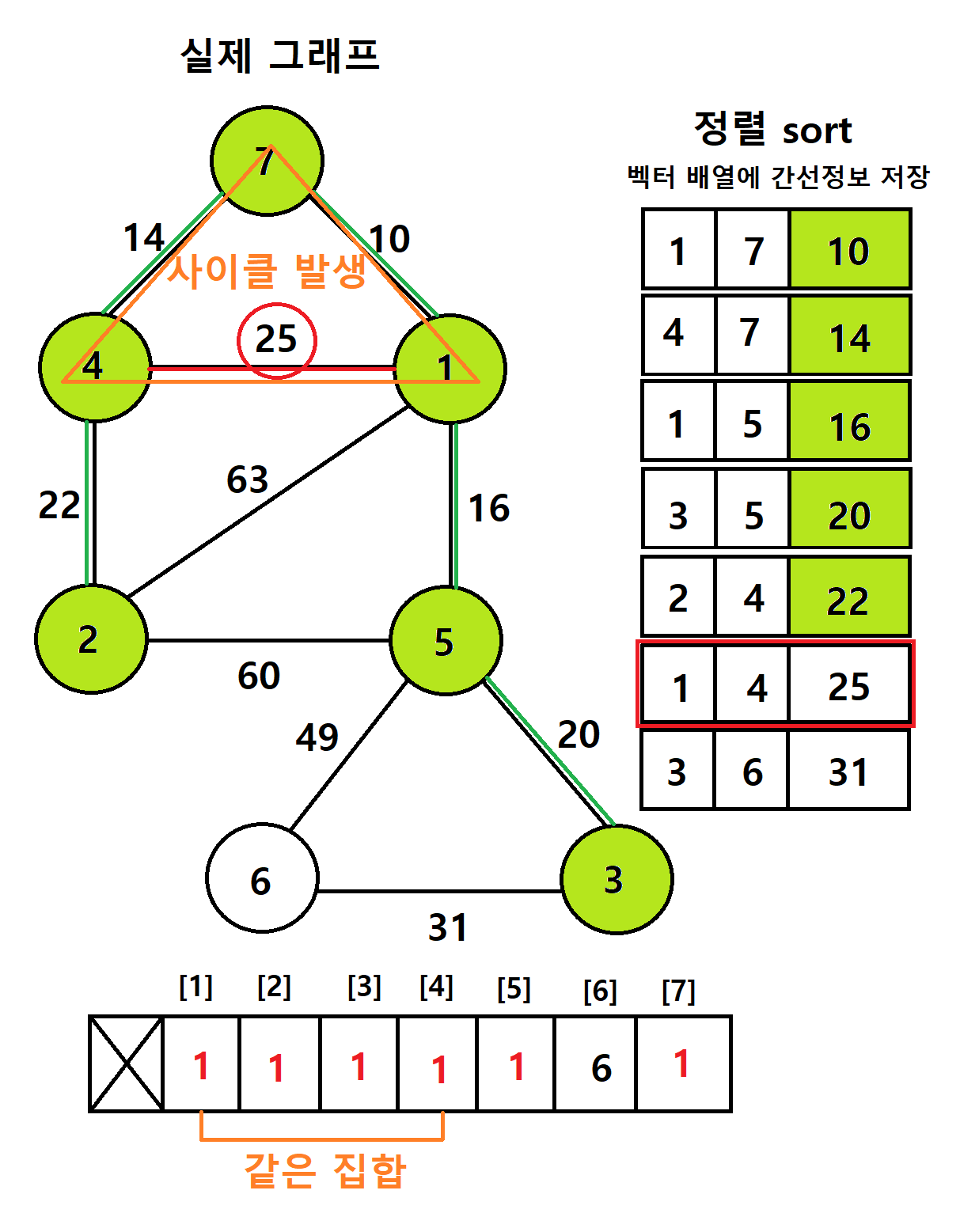
- 사이클이 발생하는 간선(부모노드가 같은)만 건너뛰고 사이클이 발생하지 않을 거 같으면 Union함수로 연결한다
-> 따라서 아래의 그림은 모든 정점이 다 포함되어있고 최소 가중치들로만 구성된 최소 신장 트리다
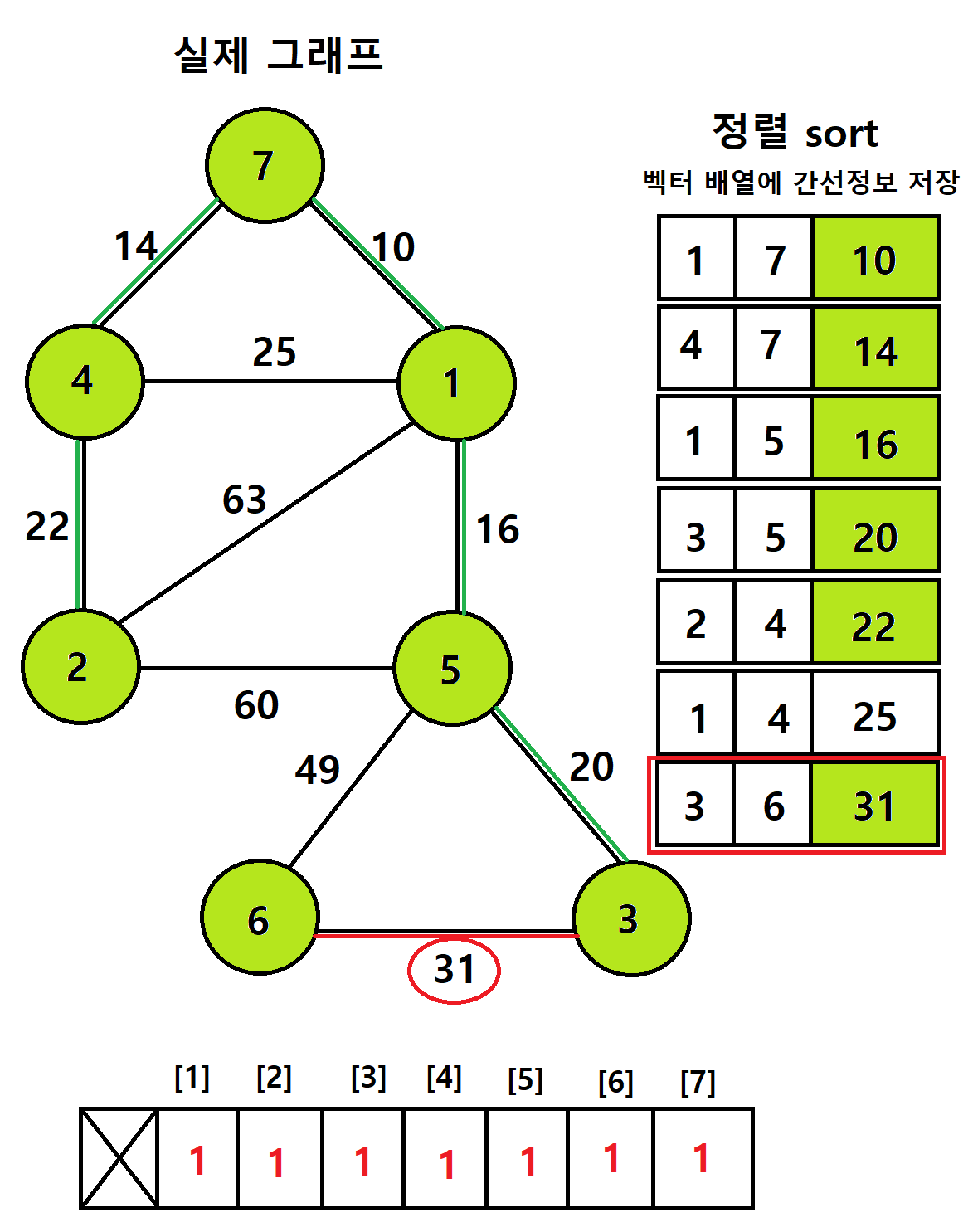
최소 신장 트리 코드 살펴보기
- Sort를 사용하기 위해
#include <algorithm>선언
Graph클래스 내부에 간선 정보를 저장 할 Edge클래스를 생성
-> Edge클래스 안에 정점x와y, 정점 두개를 연결하는 가중치 distance를 선언
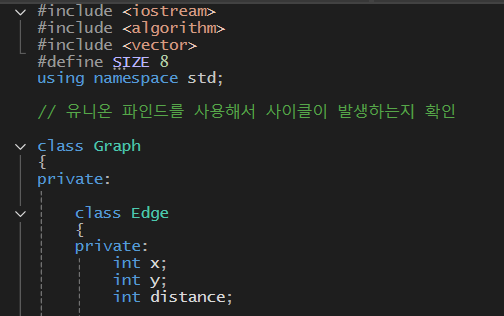
- 객체를 생성하고 Edge생성자로 인자값 x, y, distance를 받아서 그 값으로 변경한다
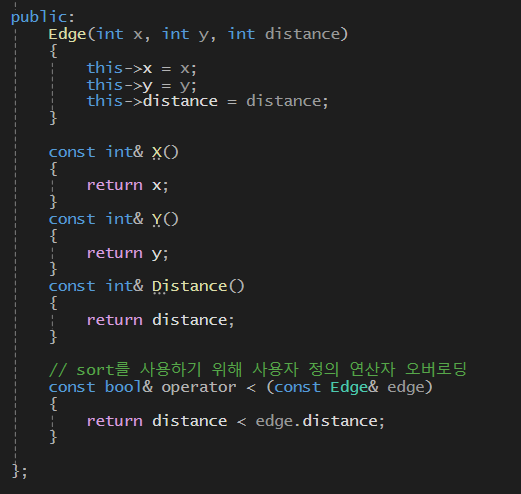
2-1. 상수 타입으로 값을 반환하는 const int & 타입의 함수들
2-2. 최소 신장트리에서 간선의 가중치를 오름차순으로 정렬하기 위해서는 연산자 오버로딩이 필요하다
-> 간선은 Edge타입으로 저장되어있기 때문에 클래스 타입이다(사용자 정의)
-> 사용자 정의 연산자 오버로딩이 꼭 필요하다
-> Edge타입 객체들끼리 일반적인 비교 연산이 불가능하다 (클래스기 때문)
-> 현재 가중치의 값과 인자로 들어온 가중치의 값을 비교하고 반환
가중치를 기준으로 값을 비교하는 연산자 오버로딩이다
3. * 부모노드를 저장할 부모배열
- 간선의 가중치를 누적해서 저장할 cost변수
- Edge타입의 정보를 저장할 벡터배열 객체 생성

- Edge타입의 정보를 저장할 벡터배열 객체 생성
- Graph 생성자에서 부모배열의 값을 모두 자신의 값으로 초기화한다
-> 각각의 집합들이 독립적인 상태로 초기 셋팅해두기
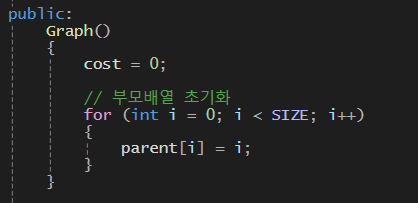
- UnionFind를 사용할 것이기 때문에 앞에서 배운 함수를 가져왔다
-> Union 함수 : 정점을 서로 연결 (부모 노드를 통일시키기)
-> Find 함수 : 해당 정점의 root노드를 재귀적으로 찾기
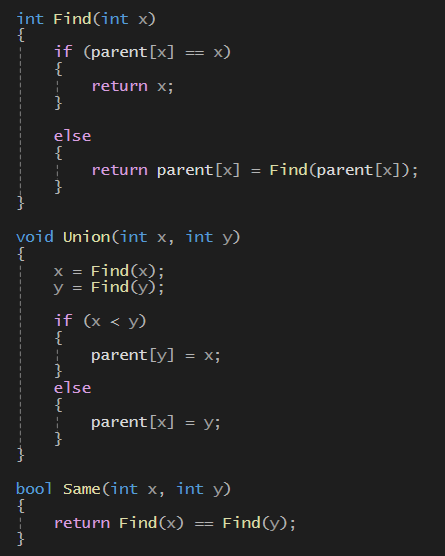
- 벡터 배열에 Edge타입의 정보를 저장한다
-> Edge클래스는 생성자에 매개변수를 x,y,distance를 받아서 저장한다
-> 벡터 배열안에 이 정보를 삽입한다
-> 벡터는 동적으로 크기가 변하는 동적배열이다
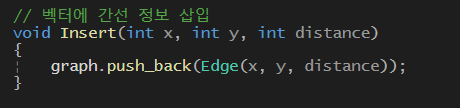
- 크루스칼 알고리즘
-
위에서 정의한 연산자 오버로딩을 통해 벡터배열 내부에 저장되어있는 Edge타입 데이터 중 가중치끼리 비교하여 오름차순으로 정렬한다 (begin( ) ~ end( ))
-
정보가 저장된 벡터의 크기만큼 반복
-
만약 벡터에 저장된 정점 x와 y의 root노드가 같다면 같은 집합이기 때문에 연결하지 않는다
->Same(graph[i].X(), graph[i].Y());의 의미는 매개변수값으로 보내지는 것이 벡터배열안에 저장되어있는 정점의 값이다. 이 정점의 값이 Same함수로 들어가게되어 Find함수를 통해 해당 정점의 root값 끼리 비교하게 된다 -
만약 정점의 root노드가 서로 다르다면
-> 서로 다른 집합에 속해있다는 것 (부모노드가 다르다)
-> 간선을 연결해도 사이클이 생기지 않는다는 의미
-> Union함수를 사용하여 서로 연결 -
벡터의 크기만큼 반복을 다 돌리면 정점을 모두 다 탐색했다는 의미 (간선 다 탐색함)
-> 누적한 최소비용 출력
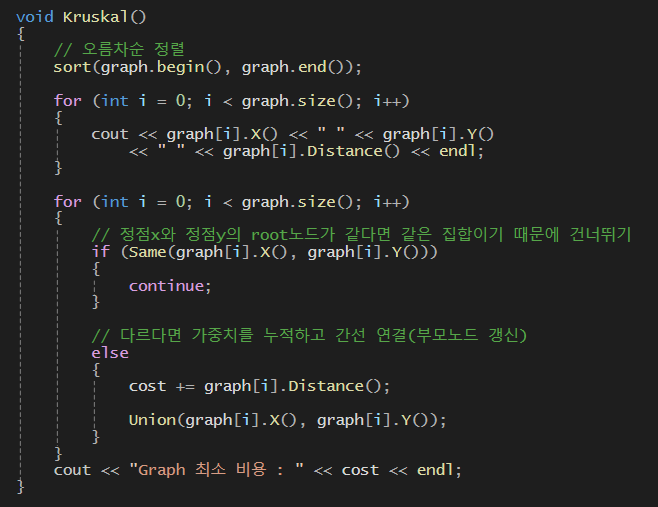
전체코드
#include <iostream>
#include <algorithm>
#include <vector>
#define SIZE 8
using namespace std;
// 유니온 파인드를 사용해서 사이클이 발생하는지 확인
class Graph
{
private:
class Edge
{
private:
int x;
int y;
int distance;
public:
Edge(int x, int y, int distance)
{
this->x = x;
this->y = y;
this->distance = distance;
}
const int& X()
{
return x;
}
const int& Y()
{
return y;
}
const int& Distance()
{
return distance;
}
// sort를 사용하기 위해 사용자 정의 연산자 오버로딩
const bool& operator < (const Edge& edge)
{
return distance < edge.distance;
}
};
int parent[SIZE]; // 부모배열
int cost; // 최소비용 = 가중치의 합이 최소
vector <Edge> graph; // 간선 정보를 저장할 벡터배열
public:
Graph()
{
cost = 0;
// 부모배열 초기화
for (int i = 0; i < SIZE; i++)
{
parent[i] = i;
}
}
int Find(int x)
{
if (parent[x] == x)
{
return x;
}
else
{
return parent[x] = Find(parent[x]);
}
}
void Union(int x, int y)
{
x = Find(x);
y = Find(y);
if (x < y)
{
parent[y] = x;
}
else
{
parent[x] = y;
}
}
bool Same(int x, int y)
{
return Find(x) == Find(y);
}
// 벡터에 간선 정보 삽입
void Insert(int x, int y, int distance)
{
graph.push_back(Edge(x, y, distance));
}
void Kruskal()
{
// 오름차순 정렬
sort(graph.begin(), graph.end());
for (int i = 0; i < graph.size(); i++)
{
cout << graph[i].X() << " " << graph[i].Y()
<< " " << graph[i].Distance() << endl;
}
for (int i = 0; i < graph.size(); i++)
{
// 정점x와 정점y의 root노드가 같다면 같은 집합이기 때문에 건너뛰기
if (Same(graph[i].X(), graph[i].Y()))
{
continue;
}
// 다르다면 가중치를 누적하고 간선 연결(부모노드 갱신)
else
{
cost += graph[i].Distance();
Union(graph[i].X(), graph[i].Y());
}
}
cout << "Graph 최소 비용 : " << cost << endl;
}
};
int main()
{
#pragma region 신장 트리
// 그래프의 모든 정점을 포함하면서 사이클이 존재하지 않는
// 부분 그래프로, 그래프의 모든 정점을 최소 비용으로
// 연결하는 트리입니다.
// 그래프의 정점의 수가 n개일 때, 간선의 수는 n - 1개 입니다.
// 최소 비용 신장 트리
// 그래프의 간선들의 가중치 합이 최소인 신장 트리
Graph graph;
graph.Insert(1, 7, 10);
graph.Insert(4, 7, 14);
graph.Insert(1, 4, 25);
graph.Insert(2, 4, 22);
graph.Insert(1, 2, 63);
graph.Insert(1, 5, 16);
graph.Insert(2, 5, 60);
graph.Insert(3, 5, 20);
graph.Insert(3, 6, 31);
graph.Insert(5, 6, 49);
graph.Kruskal();
#pragma endregion
return 0;
}결과값:
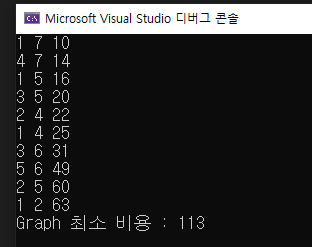
시간복잡도
- 크루스칼 알고리즘 -> O(ElogE)
-
가중치를 오름차순으로 정렬하기 위한 정렬 알고리즘 NlogN
-> 간선의 수가 E라면 ElogE우리는 sort알고리즘을 사용하여 정렬하였다
C++에서 제공하는 sort는 혼합정렬 방식을 사용한다
혼합정렬 : 퀵정렬, 힙정렬, 삽입정렬
여기서는 퀵정렬 방식이 사용되어 시간복잡도가 NlogN -
유니온 파인드를 사용하여 최소 간선부터 연결 -> 상수시간
-> 유니온 파인드 시간복잡도에서 배웠던 것 처럼 O(a(n))으로 거의 상수시간에 가깝다
https://velog.io/@yangju058/알고리즘-Union-FInd
최소 신장트리 코드 다시보기
#include <iostream>
#include <vector>
#include <algorithm>
#define SIZE 6
using namespace std;
class Graph
{
private:
int parent[SIZE]; // 0번째 인덱스 사용x
int cost; // 가중치를 담을 변수
class Edge
{
private:
int x;
int y;
int distance;
public:
Edge(int x, int y, int distance)
{
// 생성자의 매개변수로 받은 값을 현재 값으로 설정
this->x = x;
this->y = y;
this->distance = distance;
}
// 상수 참조 타입으로 반환
const int & X()
{
return x;
}
const int& Y()
{
return y;
}
const int & Distance()
{
return distance;
}
// 가중치 정렬을 사용하기 위한 사용자 정의 연산자 오버로딩
bool operator < (const Edge & other)
{
return (distance < other.distance);
}
};
vector <Edge> graph; // Edge타입을 담을 벡터 배열
public:
Graph()
{
for (int i = 0; i < SIZE; i++)
{
parent[i] = i;
}
cost = 0;
}
int Find(int x)
{
if (parent[x] == x)
{
return x;
}
else
{
parent[x] = Find(parent[x]);
}
}
void Union(int x, int y)
{
x = Find(x);
y = Find(y);
if (x < y)
{
parent[y] = x;
}
else
{
parent[x] = y;
}
}
// 벡터 배열에 간선 정보 저장 (Edge타입)
void Insert(int x, int y, int distance)
{
graph.push_back(Edge(x, y, distance));
}
void kruskal()
{
// 가중치를 기준으로 오름차순 정렬
sort(graph.begin(), graph.end());
for (int i = 0; i < graph.size(); i++)
{
// Same 함수를 써도 괜찮을듯
if (Find(graph[i].X()) == Find(graph[i].Y()))
{
continue;
}
else
{
cost += graph[i].Distance();
Union(graph[i].X(), graph[i].Y());
}
}
cout << "최소 신장 트리의 값 : " << cost << endl;
}
};
int main()
{
Graph graph;
graph.Insert(1, 2, 20);
graph.Insert(2, 3, 9);
graph.Insert(2, 4, 24);
graph.Insert(3, 4, 13);
graph.Insert(3, 5, 35);
graph.Insert(4, 5, 5);
graph.Insert(5, 1, 15);
graph.kruskal();
return 0;
}-
반복 횟수를 SIZE로 정했지만 실행했을때 오류자체는 나지 않고 잘 실행된다
-> 정점 갯수와 저장된 갯수가 같기 때문이다
-> SIZE만큼 반복이 되기도 전에 그냥 최소신장트리가 완성되었기 때문인듯수가 안맞는 경우도 있을 수 있기 때문에 백터 배열안에 들어있는 갯수만큼 반복하게 하자
->i < graph.size()로 교체 -
유니온 파인드에서 사용했던 Same함수를 사용해도 괜찮을 거 같다
-> 아래의 코드도 맞지만, 더 간결하게 하기위해 T/F를 판단해줄 bool함수를 따로 만들어두자
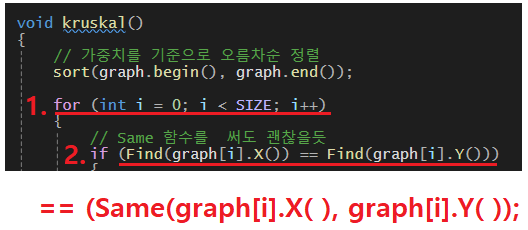
-
const &상수참조
- const (상수) : 반환하는 x값을 상수 타입으로 반환한다 (값 변경 불가)
- & (참조) : 반환하는 x값을 값 복사가 아닌 참조로 반환한다 (실제 x의 메모리를 가리킴) 복사비용이 발생하지 않는다
즉, const와 &를 함께 쓰는 이유
값 변경을 방지하면서(상수), 복사 비용 없이 원본을 읽기 위해서(참조) 사용한다

결과값 :