
문자열 매칭
: 문자열에 해싱 기법을 사용하여, 해시 값으로 비교하는 문자열 알고리즘이다
Naive 알고리즘
패턴 검색 알고리즘 중에서 가장 간단한 알고리즘으로, 단순히 문자를 처음부터 끝까지 차례로 비교하며 문자열을 찾는다
내가 찾고자 하는 문자열의 길이만큼, 기존의 긴 문자 배열안의 값과 비교해나가는 방식
-
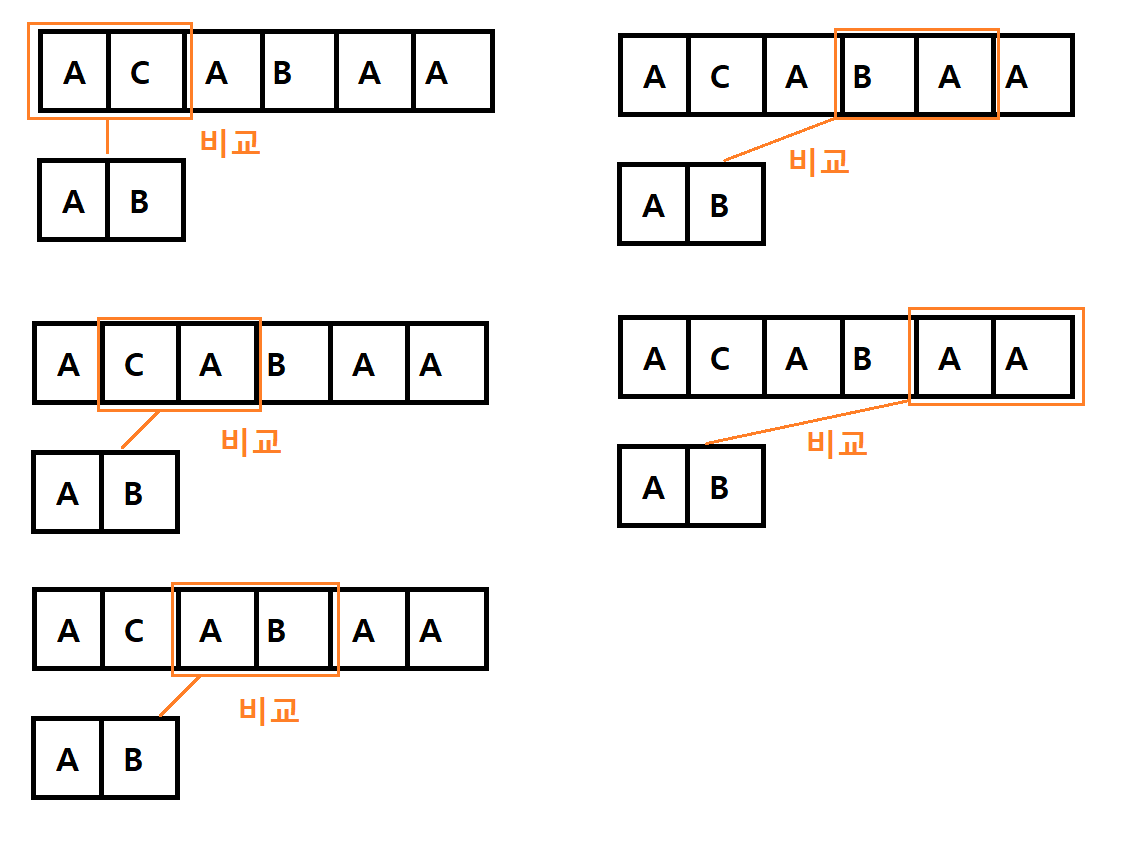
찾고자 하는 값이 하나라도 다르면 바로 중지하고 다음 문자열을 확인한다
(하나라도 다르면 더 반복문을 돌릴 이유가 없음) -
끝까지 다 비교를 했다면 같은 문자열을 찾은 것이다
(하나라도 틀리면 바로 break 되었을 것)
Naive 전체코드
문자열 key안에서 other과 같은 문자열을 찾아내보자
-
문자열의 길이를 반환하는
strlen<- null문자를 제외한 값을 반환함 -
바깥쪽 반복문은 비교를 몇번 할 것인지, n - m + 1번 비교를 해야한다
i = 0부터 시작하기 때문에i <= n - m까지 반복
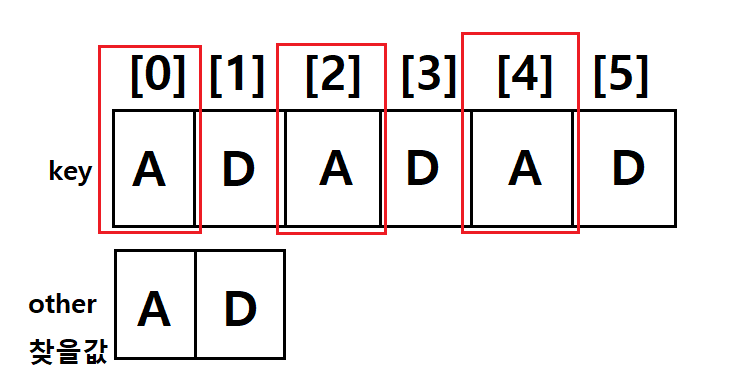
ex) key의 문자열 길이 6, other의 문자열 길이 2
-> 총 비교 횟수는 5번 ! (위의 그림에서 other길이 만큼 비교하는 게 5번 행해짐) -
안쪽 반복문은 other의 문자열 값과 key의 문자열 값을 비교하는 반복
-> 찾고자 하는 other문자열 길이만큼 비교한다
-
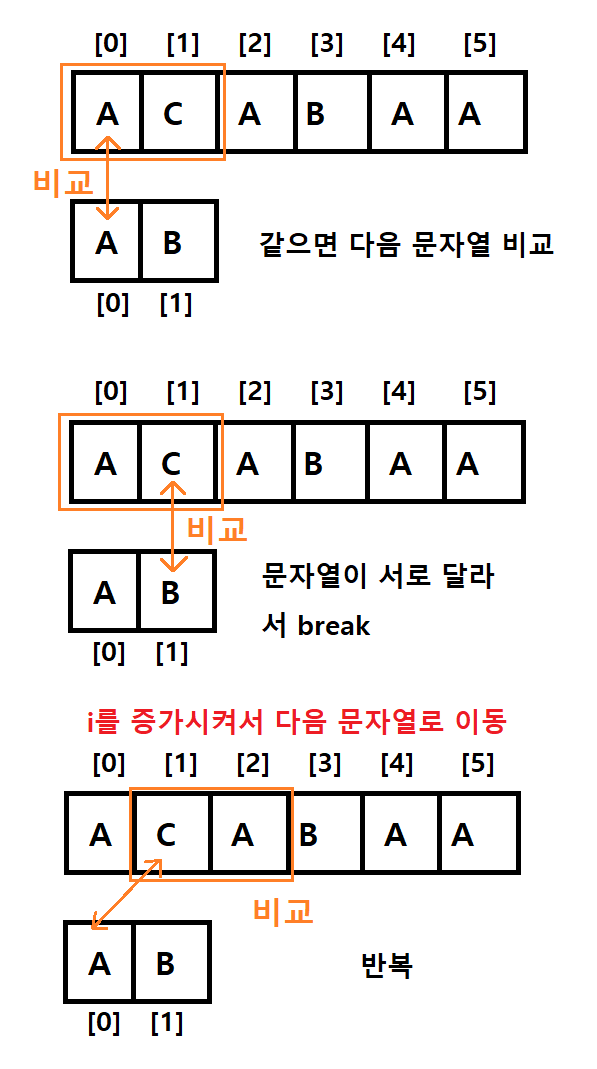
j == m이 되었다는 뜻은, 문자열을 끝까지 비교했다는 것
즉, 찾고자 하는 문자열과 값이 같다! 찾았다!
-> 하나라도 문자열이 다르면 바로 break로 빠져나왔기 때문에, 끝까지 비교했다는 건 그 문자열이 서로 같다는 것이다 -
일치하는 곳의 시작 인덱스 값을 반환하면 끝
void Naive(const char* key, const char* other)
{
// 시간 복잡도 n * m
// 문자열 길이 (null문자한 제외)
int n = strlen(key);
int m = strlen(other);
int j = 0;
// 등호를 중요시 하자
for (int i = 0; i <= n - m; i++)
{
for (j = 0; j < m; j++)
{
if (key[i + j] != other[j])
{
break;
}
}
if (j == m)
{
cout << "Pattern Found at Index" << i << endl;
}
}
}
int main()
{
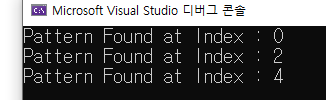
Naive("ADADAD" , "AD"); // n = 6 m = 2 결과값: 0 2 4 인덱스 번호
return 0;
}출력값 :
Naive 시간복잡도
바깥쪽 반복문은 긴 문자열(key)을 순차적으로 탐색하고, 안쪽 반복문은 작은 문자열(other)을 하나씩 비교하는 구조
n = key의 문자열 길이
m = other의 문자열 길이
시간복잡도 O(n * m)
Rabin-Karp 알고리즘
해시 기법을 사용하는 문자열 매칭 알고리즘이다
해시 : 긴 데이터를, 그것을 상징하는 짧은 데이터로 바꾸어주는 기법
라빈카프에서 사용하는 해시 값은 아스키 코드값 * 2의 제곱수들을 모두 더한 값으로 나타낸다
아래의 그림을 보면 쉽게 이해할 수 있다
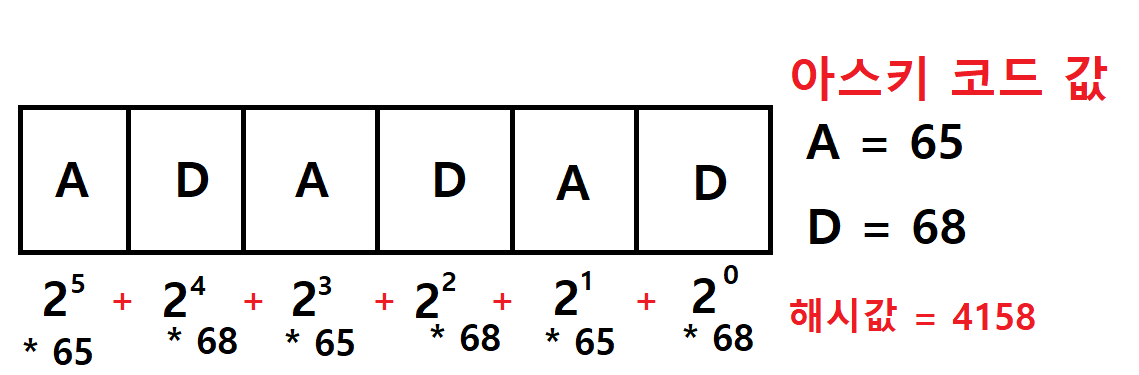
라빈카프 과정
간단하게 과정을 살펴보면
-
각 문자열의 해시값을 비교한다.
-> 이 방식에서, 반복문을 진행할때마다 해시값을 다시 다 구하는 건 비효율적이다.
-> rolling Hash 기법을 사용하여 해시값을 구한다
-> rolling Hash : 한 번의 전체 계산이 아니라 이전에 계산한 해시 값을 상수 시간에 갱신하는 방식 (슬라이딩 윈도우 방식)

-
해시값이 같은 문자열을 찾는다.
-
문자열 매칭을 사용하여 각각의 문자열을 비교한다.
-
같다면 출력하고, 다르다면 문자열을 한칸 이동하여 다시 1번부터 반복한다.
라빈카프 코드 자세히 보기
-
인자로 문자열 2개를 받는다
const char * pattern-> 기존 긴 문자열
const char * text-> 내가 찾고자 하는 문자열 -
2의 제곱수를 지정하기 위한
power변수 -
인자로 받은 문자열의 길이를 저장하기 위한 변수 선언 (
strlen은 null문자를 포함하지 않은 길이)
patternSize-> pattern 문자열의 길이
textSize-> text 문자열의 길이
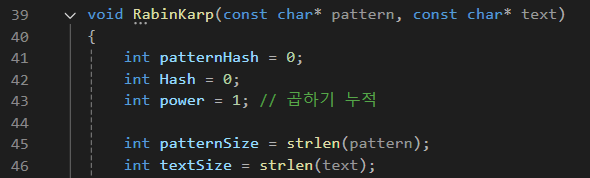
-
바깥쪽 for문 -> 나이브와 동일하게 pattern - text 길이 만큼 반복
- 만약
i == 0일 경우, 맨 앞의 문자열을 비교하기 전, 해시 값을 지정해야한다
누적된 값이 바로 각각의 해시 값
-
patternHash += pattern[textSize - 1 - j] * power -
Hash += text[textSize - 1 - j] * power -
power의 값이 2의 제곱수가 되는 이유는 j가 textsize만큼 반복하면서 해시값을 지정하는데, 그 범위 내에서 아직 해시값 지정중이라면 power 2배
->j < textSize - 1범위인 이유는, textSize는 인덱스기 때문에 j는 0부터 시작함.
-> 아래의 그림에서는 j는 0, 1까지 하고 power값이 4가 되어있는 상태에서 마지막 A의 해시값까지 계산하고 종료되는 것
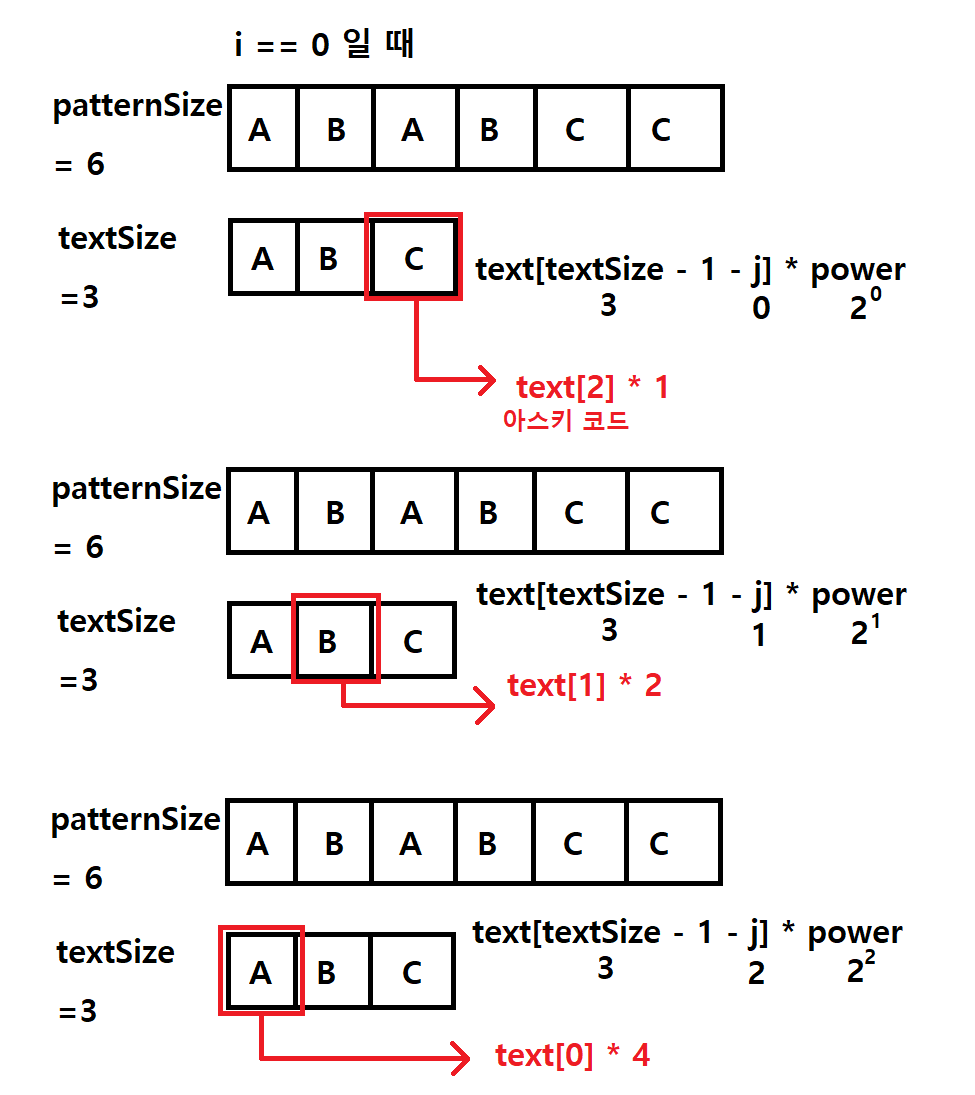
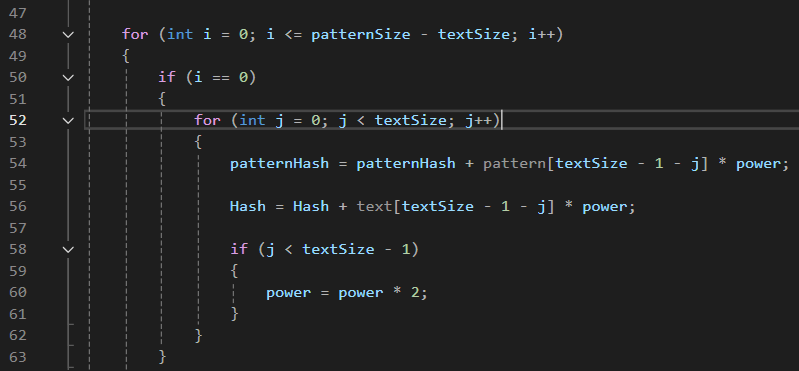
- 만약, i == 0이 아니라면?
-> 맨 처음 문자열이 아닌 비교하고 문자열을 뒤로 옮긴 상태라는 의미이다
-> 해시값을 다시 지정해야한다
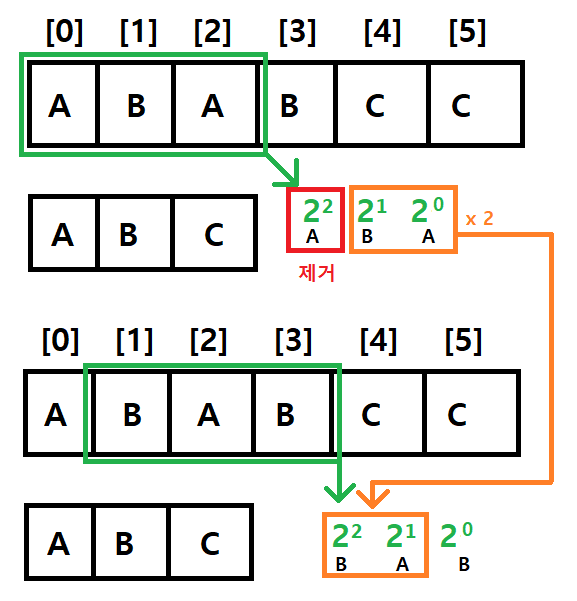
- 기존의 계산했던 해시값에서 가장 앞의 해시값을 빼고, 해시값 x 2 (제일 지수가 컷던 값)
-> 문자열이 3개 였다고 하면[0]값 * 2²이 해시값에서 빠지는 것
-> 그런 뒤에 나머지 해시값에 x 2
(나머지 해시값은[1]값 * 2¹과[2]값 * 2^0) 여기에 x 2를 해준다 - 이제 기존의 문자열 1개는 비교가 끝났고 새 문자열의 해시값을 구해야 할 차례
-> [0]번째 값이 빠졌고, 다시 문자열을 이동하여 새 문자열은[textSize - 1 + i]번째 인덱스다
->+ i를 해주는 이유!!!
-> 새 문자열을 비교한다는 의미는 pattern 문자열에서 i번째를 뒤로 이동한다는 의미
즉, 다음 문자열을 비교한다는 건 다음 반복문을 수행한다는 것 (i++)

- 해시값을 구하고 그 해시값이 같으면 아래의 조건문으로 이동한다
-> bool 변수를 지정하고 해시값이 서로 같으면 true
-> 안의 문자열을 하나씩 비교해서 만약 하나라도 다른 게 있다면 false하고 탈출
-> 만약 끝까지 false가 되지 않고 비교를 마쳤을 경우, 해당 문자열은 서로 같다는 것!
-> 같은 문자열의 시작 인덱스 값을 출력한다
7. 메인함수에서 매개변수를 넣고 문자열을 매칭한다
라빈카프 전체코드
#include <iostream>
using namespace std;
// 문자열 매칭
// 1. Naive방식
// 2. Rabin - Karp 알고리즘
// 3. 오토 마타
// 4. 보이어 무어
// 5. KMP
void Naive(const char* key, const char* other)
{
// 시간 복잡도 n * m
int n = strlen(key);
int m = strlen(other);
int j = 0;
for (int i = 0; i < n - m; i++)
{
for (j = 0; j < m; j++)
{
if (key[i + j] != other[j])
{
break;
}
}
if (j == m)
{
cout << "Pattern Found at Index" << i << endl;
}
}
}
// 65 66 67
// A B C
void RabinKarp(const char* pattern, const char* text)
{
int patternHash = 0;
int Hash = 0;
int power = 1; // 곱하기 누적
int patternSize = strlen(pattern);
int textSize = strlen(text);
for (int i = 0; i <= patternSize - textSize; i++)
{
// 가장 처음의 해시값
if (i == 0)
{
for (int j = 0; j < textSize; j++)
{
// 뒤의 인덱스부터 계산
patternHash = patternHash + pattern[textSize - 1 - j] * power;
Hash = Hash + text[textSize - 1 - j] * power;
// 문자열의 해시값을 설정하는 동안 2의 제곱수 만들기
if (j < textSize - 1)
{
power = power * 2;
}
}
}
// 문자열을 이동할때, 새 해시값으로 갱신하는 과정
else
{
patternHash = 2 * (patternHash - pattern[i - 1] * power) + pattern[textSize - 1 + i];
}
if (patternHash == Hash)
{
bool flag = true;
for (int j = 0; j < textSize; j++)
{
if (pattern[i + j] != text[j])
{
flag = false;
break;
}
}
if (flag == true)
{
cout << i << "번째에서 발견하였습니다." << endl;
}
}
}
}
int main()
{
#pragma region 문자열 매칭
// 문자열에 해싱 기법을 사용하여 해시 값으로
// 비교하는 문자열 알고리즘입니다.
//Naive("AABAAAB", "AA");
// 0, 3, 4
RabinKarp("ADADAD", "AD");
#pragma endregion
return 0;
}출력값 :

라빈카프 시간복잡도
맨 처음 해시값을 구할때 (i == 0), 짧은 문자열의 길이(text)만큼의 시간복잡도가 걸린다 O(M)
그 뒤로는 슬라이딩 윈도우 방식을 사용하여 기존의 해시값에서 하나씩만 변동이 생기게 구하기 때문에 한번 비교할때마다 해시값 찾는 게 상수시간 O(1)이 걸린다
-> 새 문자열을 비교하는 건 i값이 증가할때마다 문자열도 이동하여 비교하기 때문에 총 상수시간O(1)이 N번 비교
즉, 시간복잡도 O(M + N)
