시간복잡도
O(N) 빅오 표기법
-> 최고차항을 제외한 값 제거, 상수계수 무시

브루트 포스
무식한 방법임
그냥 처음부터 끝까지 다 확인하는 방법 for문
Inplace정렬
제자리 알고리즘이라고도 한다. 그냥 메모리 더 쓰지 않고 그 안에서 이루어지는 정렬
거품정렬
서로 인접한 요소끼리 비교해서 값을 swap하는 방식
맨 마지막 값은 알아서 정렬된 상태기 때문에 안쪽j값이 (SIZE - i) -1까지만 반복
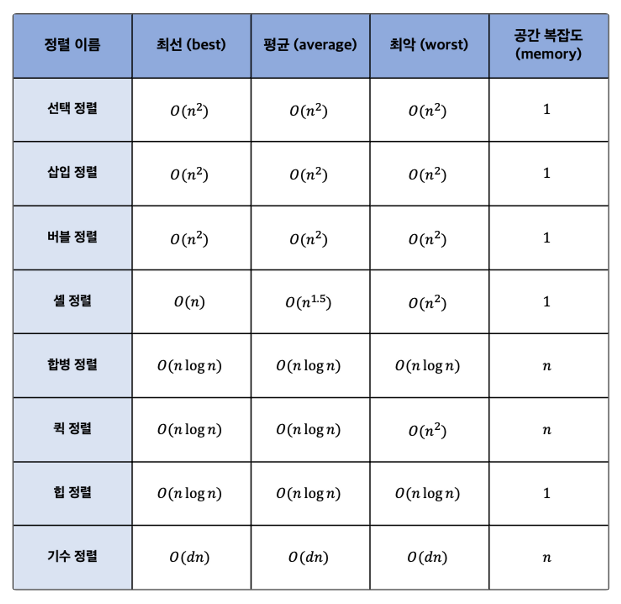
시간복잡도 O(N²)
선택정렬
주어진 리스트 중에 최소값을 찾아서 맨 앞에 위치한 결과를 교체하는 방식
최소값을 찾은 뒤 맨 앞에 값과 스왑, 다음 반복에서 가장 앞에꺼 제외하고 다시 반복
시간복잡도 O(N²)
삽입정렬
이미 정렬된 부분과 비교하여 자신의 위치를 찾아 삽입하는 방식으로 정렬
정렬된 부분을 확인 하는 부분이 뒤에서부터 앞으로 확인한다
시간복잡도 O(N²)
에라토스테네스의 체
소수 판별에 사용되는 알고리즘
소수들의 배수를 차례로 지워나가면서 남은 소수를 얻어내는 것
예를 들면, 소수는 2,3,5,7 등 1과 자기자신만을 가진 소수인데, 이 방법을 사용하면 2,4,6,8 등 2의 배수를 제거하고, 3,6,9,12 등 3의 배수를 제거하는 이러한 과정을 반복한다
시간복잡도는 O(N log(log N))으로 N이 커질수록 빠르게 작동한다
제곱근을 사용한다
제곱은 이후로는 지울 수 있는 새로운 배수가 나오지 않기 때문이다
예를 들면, 2x6 이 뒤에서는 6x2로 나오기 때문
계수정렬
비교연산을 사용하지 않고 정렬하는 알고리즘
배열 내의 특정한 값이 몇번 나왔는지에 따라 정렬이 수행
시간복잡도 O(N + k)
-> N은 배열의 크기, k는 배열에 있는 최대값
공간복잡도 O(k)
-> 최대값크기로 count배열의 크기를 정하기 때문에, 값이 크면 비효율적
투 포인터
두 개의 포인터를 활용해서 배열의 요소를 효과적으로 탐색
end와 start를 이동시키면서 내가 찾고자 하는 값과 비교하여 해당 값이 몇개 있는지 찾는 것
조건문을 탈출하는 break문은 무조건 end를 연산시키는 코드위에 있어야한다
두개의 포인터 start와 end 는 배열의 처음에 위치하고 배열의 끝까지 한번씩만 이동하기 때문에 배열의 크기만큼 탐색하는 것이다
따라서 시간복잡도는 O(N)
이진 탐색
탐색 범위를 반으로 나누어서 찾는 값을 포함하는 범위를 좁혀나가는 방식
pivot과 left right의 값을 비교하여 left 와 right를 이동시켜나감
깊이가 logN이 되는 것(연산도 logN이 되는 것)
시간복잡도 O(logN)
분할 정복
큰 문제를 작은 문제로 분할하여 문제를 해결하는 방법
그냥 분할 정복 자체는 깊이가 logN인 것
병합정렬에서 자세한 시간복잡도가 나온다
병합정렬
하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 정렬
각각의 임시배열들은 재귀함수가 호출될때마다 동적으로 생성되고 해제되는 것. 그렇기 때문에 바로 정렬해서 기존 배열에 값을 복사해야한다
배열을 재귀함수를 이용하여 반으로 쪼개고, 배열의 크기가 가장 작은 사이즈가 될때까지 분할한다
연산은 logN깊이로 각 단계마다 N번씩 다 비교하고 수행하기 때문에 N * logN 으로 시간복잡도는 O(NlogN)이다
퀵 정렬
기준점을 얻은 다음, 기준점을 기준으로 부분 배열로 나누고, 한쪽은 기준점보다 작은 값들이 위치하고 다른 한 쪽은 기준점보다 큰 값들이 위치하도록 정렬
재귀를 사용한다
평균, 최선O(NlogN)
속 쪼개져 나가기 때문에 깊이는 logN, 각 단계별로 연산을 N번 수행하기 때문에
최악O(N²)
기준점(pivot)이 항상 가장 작은 값이나 항상 가장 큰 값으로 선택되어 균등하게 나누어 지지 않을경우, logN으로 깊이가 발생하지 않고 N이 된다
유클리드 호제법
최대공약수 구하는 알고리즘
GCD(a, b) = GCD(b, a % b)
두 수 x와 y중 더 작은값을 따라 로그에 비례한다 = (O(min(a,b))
즉, N = min(x, y)에서 x값이 더 작다면 시간복잡도는 O(logN)이다
계속 모듈러 연산을 사용하면서 더 작은 값이 0이 될때까지 반복되기 때문
탐욕법
최적의 해를 구하는 데에 사용
탐욕선택속성 : 현재 단계에서 최적이라고 생각되는 선택이 결국 전체 문제의 최적 해로 이어지는 속성
최적 부분 구조 : 전체 문제의 최적 해결 방법이 부분 문제의 최적 해결 방법으로 구성된 문제구조
(분할정복, DP)
탐욕법은 각 단계에서 최적이라고 생각하는 해를 결정하니까, 각 단계의 최적의 해가 전체 문제의 최적의 해가 되는 문제에 사용하면 좋다!
시간복잡도는 상황마다 다름
사용되는 곳 : 다익스트라
동적계획법 (DP) & 메모이제이션
특정 범위까지의 값을 구하기 위해서 작은 범위의 값을 이용하여 효율적으로 값을 구하는 알고리즘
메모이제이션 : 이미 계산된 결과(작은 문제)는 별도의 메모리 공간에 저장해두어 다시 계산하지 않도록 한다
피보나치 수열을 구할때 효과적이다 (앞의 연산 결과가 계속 필요한 경우다)
시간복잡도는 O(N)
백트레킹
해를 찾아가는 도중에 지금의 경로가 해가 될 것 같지 않으면, 더 이상 깊이 들어가지 않고, 이전 단계로 다시 돌아가는 알고리즘
깊이우선탐색 DFS
스택 자료구조나 재귀를 사용하여 구현
무방향 그래프에서 사용
root노드부터 시작해서 출력하고 방문체크를 하는 과정을 한다.
현재 노드의 인접한 노드들 중 방문되지 않은 노드가 있다면 그 노드쪽으로 들어가는 것
시간복잡도 : O(V + E) -> 모든 간선과 정점을 한번씩만 처리
공간복잡도 : O(V) -> 각 정점에 대한 정보를 저장 (인접리스트 사용)
너비우선탐색 BFS
Queue 자료구조를 사용
시작 정점을 방문한 후 시작 정점에 인접한 모든 정점들을 우선 방문하는 탐색 방법
시간복잡도 : O(V + E) -> 모든 간선과 정점을 한번씩만 처리
공간복잡도 : O(V) -> 각 정점에 대한 정보를 저장 (인접리스트 사용)
위상정렬
순서가 정해져있는 작업을 순서대로 수행해야 할 때, 그 순서를 결정해주는 알고리즘
간선의 방향 순서를 지키면서 순서대로 정렬
비순환 단방향 그래프에서 사용된다(사이클이 없는)
진입차수를 사용하여 간선을 제거해나가면서 모든 정점을 다 탐색
O(V + E)
유니온 파인드
서로소 집합을 관리하는 자료구조
어떤 노드가 다른 노드와 연결되어있는지 즉, 같은 집합에 속하는지 확인할 때 사용
Find : 해당 노드의 최상위 root 노드를 찾는 것 (집합의 대표 찾기)
Union : 두 집합을 합치는 것 (root노드 통합)
O(M log N)
M : 연산의 개수
N : 노드의 개수
Find와 Union의 시간복잡도는 트리구조로 이루어져있기 때문에, logn의 시간복잡도
유니온 파인드의 연산의 수(M) x 유니온 파인드 (logN)
-> 유니온 파인드의 연산의 수 (M) : Find와 Union을 몇번 수행했는지, (호출)
최소 신장 트리
신장 트리 : 그래프의 모든 정점을 포함하면서 사이클이 존재하지 않는 부분 그래프
최소신장트리: 그래프의 모든 정점을 최소 비용으로 연결하는 트리
정점 N개를 연결하려면 N - 1개의 간선이 필요
sort알고리즘을 사용하여 오름차순 정렬함 (간선길이별로) 시간복잡도가 NlogN
유니온 파인드는 상수시간
결론, 크루스칼 알고리즘 O(ElogE) (E 간선의 수)
간선을 가중치를 기준으로 정렬한 뒤 사이클이 생기지 않으면 간선을 추가하는 방식
크루스칼 알고리즘에선 가중치가 가장 작은 간선부터 차례대로 선택한다
-> 최소 가중치 간선만 선택하다보면 (부분 문제 해)
-> 최종적으로 최소 신장트리가 된다 (전체 문제 해)
즉, 탐욕법을 사용하기 알맞다
다익스트라 (최단경로)
시작점으로부터 모든 노드까지의 최소 거리를 구해주는 알고리즘
"한 노드에서 다른 노드로 가는 경로의 최소 비용"
-> 최단 경로의 기준은 무조건 시작노드이다
-> 음수 가중치를 가지지 않는다
->사이클 포함x
즉, 한 정점을 고를때마다 그 정점과 인접한 간선들을 다 갱신한 뒤, 그 배열 안에서 짧은 간선을 찾는 과정 (Find)를 V번 수행하고, 모든 정점을 다 확인하기 때문에 V번 반복하는 것
각 간선을 한번씩만 확인하기 때문에 간선 수 만큼 E
배열로 저장했을 때 시간복잡도 O(V² + E)