
시간복잡도와 공간복잡도에 대해 알아보고, 모든 알고리즘에 가장 기초가 되는 브루트 포스 알고리즘에 대해서도 알아보겠다
시간복잡도
- 특정 크기의 입력을 기준으로 할 때 필요한 연산 횟수를 의미한다
- 계산 시간이 얼마나 걸릴지 어림짐작할 수 있는 '척도'의 역할
시간복잡도 표기법
- 란다우 빅오(O) 표기법
- 오메가(Ω) 표기법
- 세타(Θ) 표기법
주로 1번 빅오(O) 표기법을 많이 사용한다
-> 빅오(O) 표기법은 점근적 상한선이다
-> 점근적 상한선에 대해 알려면 점근적 표기법 부터 알아야한다
점근적 표기법이란?
알고리즘의 수행 시간을 표기하기 위해 상수 계수와 중요하지 않은 항목을 제거하고 표시하는 표기법이다
- 최고차항 이외에 제거
-> 3N² + 5N + 100 에서 최고차항인 N²를 제외하고 나머지 제거
-> N크기가 커질수록 N²는 압도적으로 커지기 때문에 나머지 제거해도 괜찮다- 상수계수는 무시
-> 3N²에서 상수계수인 3을 무시하고 N²라고 한다
-> 차수보다 계수가 훨씬 중요하기 때문이다
-> ex) N³보다는 10N²가 더 빠르다
1. 빅오(O) 표기법 : 상한
2. 오메가 표기법 : 하한
3. 세타 표기법 : 상한과 하한의 교집합
빅오(O) 표기법의 점근적 상한선
- 아무리 느려도 O(f(n)) 정도라는 뜻
- f(n)보다 같거나 빠르다, 최악의 경우에도 이 기준을 넘지 않는다
- 즉, 알고리즘 최악의 실행 시간을 표기한 것
---
빅오(O) 표기법
아래의 사진의 x축은 데이터 입력한 양을 뜻하고 y축은 연산시간을 의미함
어떤 한 로직을 수행한다고 예를 들었을때, 해당 데이터의 양이 100이면 로직에 따라 걸리는 시간은 다 다르다
-> 아래의 사진 속 그래프 상 가장 아래에 있는 복잡도가 가장 빠른 것 (상수시간)
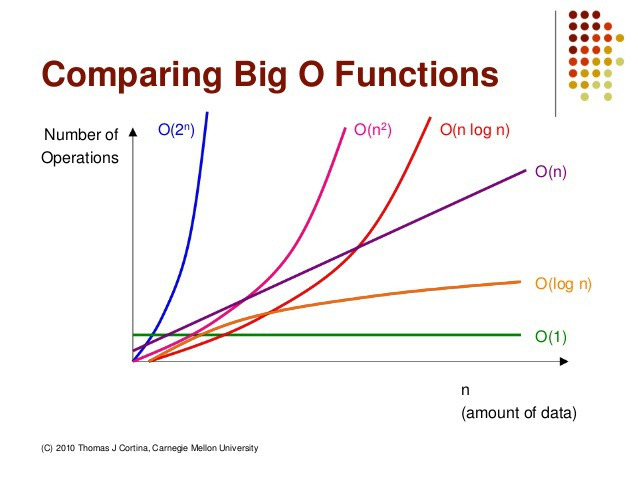
시간복잡도 빠른 순서

시간복잡도를 표기할때는 O(입력)으로 나타낸다
알고리즘 A의 계산 시간 T(N)이 대략 f(N)에 비례하면 T(N) = O(f(N))이라고 표현
-> ex) P(N) = N² T(N) = O(N²)
상수 시간 O(1)
- 입력한 크기와 상관 없이 일정한 시간복잡도를 가진다
- 예를 들면, 배열의 요소에 접근할때는 상수시간이 걸린다
- 선형 시간이 걸리는 로직을 상수 시간이 걸리도록 바꿀 수도 있다
-> for문을 사용하지 않고 값을 넣으면 바로 해당 값이 나오게 해주면 된다- 배열의 요소에 접근할때는 인덱스로 바로 접근할 수 있기 때문
ex) cout << array[1] << endl;
- for문을 사용하여 선형시간이 걸리던 로직을 상수시간이 걸리게 수정
-> 1부터 N까지의 수를 모두 합하는 방법
가우스의 덧셈공식 사용
일정한 간격으로 정수가 나열되어 있을때 1부터 n까지의 합을 구할때 사용되는 공식으로, 맨 앞의 정수와 맨 뒤의 정수를 더해나가는 방식
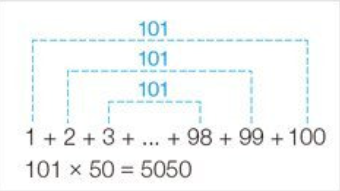
n을 입력받고 전체합을 저장해둘 result변수에 코드 작성
짝수일 경우로 작성하였다
(맨처음 값 + 맨 마지막 값) * (총 쌍의 갯수)
-> 총 쌍의 갯수는 N개를 반으로 나눈 것(한쌍에 2개의 값이니까)// 가우스의 덧셈공식 int N = 0; cin >> N; int result = 0; result = (1 + N) * (N / 2); cout << result << endl; - 배열의 요소에 접근할때는 인덱스로 바로 접근할 수 있기 때문
로그 시간 O(log n)
- 데이터 크기에 따라 실행 시간이 로그 함수의 형태로 증가한다
- 예를 들면, 자료구조에서 배웠던 이진탐색트리 구조에서 트리 안의 요소를 탐색할때, 이진탐색트리 특성상 반씩 탐색을 하기 때문에 로그시간이 걸린다
선형 시간 O(n)
- 입력에 따라 걸리는 시간이 선형적으로 증가된다
- 예를 들면, 가장 기본이 되면 for문
1부터 N까지의 수를 모두 합하는 방법
for문을 사용해서 1~N까지의 수를 모두 더할 수 있다
-> O(n) 시간복잡도가 걸린다int sum = 0; int N = 10; for(int i = 1; i <= N; i++) { sum += i; } cout << sum << endl;
제곱 시간 O(n²)
- 입력되는 데이터를 기준으로 n²만큼 증가한다
- 예를 들면, 2중 for문
2중for문을 사용해서 count를 증가시키게 되면 i에서도 count++이 발생하고 j에서도 count++이 발생하기 때문에 count++은 N²번 발생한다
-> O(n²) 시간복잡도 가 걸린다int N = 5; int count = 0; for(int i = 0; i < N; i++) { for(int j = 0; j < N; j++) { count++; } }
복잡도 좀 더 자세히!! (선형시간 & 제곱시간 사용)
- 복잡도가 점근적 상한선을 따르는 빅오 표기법으로 했기때문에 다 생략하고 정도를 파악했다
- 그래도 실제 복잡도는 그것보다 복잡하기 때문에 한번 예시를 보기로 했다
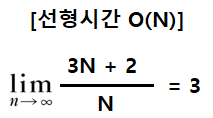
선형시간의 경우
- N을 입력받고 N까지 반복하여 count값을 증가시키는 코드이다 (시간복잡도 선형시간)
- 하지만 자세히 보면 count가 증가되는 횟수는 총 N번으로 계산 시간이 대략 N에 비례하긴 하지만 실제로는 다음과 같은 처리 발생 횟수도 포함된다
- i = 0 초기화: 1회
- i < N 판정: N + 1회
- i++ : N회
- 변수 count 증가: N회
- 총 합계는 3N + 2입니다 (대략 N에 비례)
-> N이 커지면 커질수록 뒤에 상수는 의미가 없어지는 수치임
#include <iostream>
using namespace std;
int main()
{
int N;
cin >> N;
int count = 0;
for(int i = 0; i < N; i++)
{
count++;
}
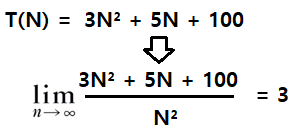
}- 실제 다른 알고리즘의 계산시간 T(N)을 복잡도로 나타내려면 점근적 표기법을 사용해야 한다
- 해당 알고리즘 계산시간T(N)을 복잡도로 표기하려면 정수배나 차수의 항의 영향을 받지 않게 해야한다
-> 대입이나 초기화 같은 작업 실행시간은 컴퓨터 환경, 프로그래밍 언어, 컴파일러 종류에 따라 실제로 걸리는 시간이 다르기 때문이다
-> 점근적 표기법을 사용해서 최고차항 이외에는 다 제거하고, 상수계수도 무시하여 O(N²)시간복잡도로 작성할 수 있다
시간복잡도 구하기 예시)
1. 짝수 나열
- for문 반복 횟수는 N/2회
-> 차수는 무시하므로 1/2는 무시되고 N만 남게된다 (시간복잡도O(N))
#include <iostream>
using namespace std;
int main()
{
int N;
cin >> N;
for(int i = 2; i <= N; i+= 2)
{
cout << i << endl;
}
}2. 최근접 점쌍 문제
-
양의 정수 N을 입력받고 N개의 좌표가 주어졌을 때, 가장 가까운 두 점 사이의 거리를 구하는 문제
-
두 점사이의 거리 구하는 공식
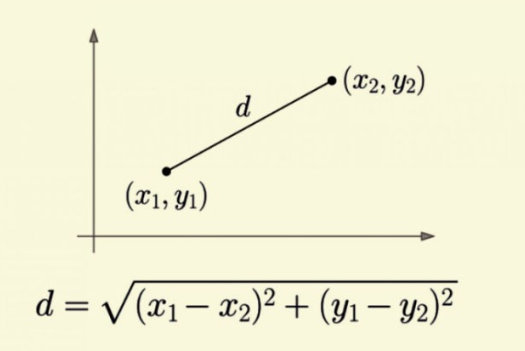
-
j의 범위가 i + 1부터 시작하는 이유!!!
-> j는 i보다 항상 인덱스가 커야하기 때문이다
-> 두 점 i와 j가 서로 다른 점이어야하기 때문이다
-> i == j면 두 점은 동일한 점으로 서로의 거리가 0이다
#include <iostream>
#include <vector>
#include <cmath>
using namespace std;
// 두 점(x1, y1)과 (x2, y2) 사이의 거리를 구하는 함수
double calc_dist(double x1, double y1, double x2, double y2)
{
return sqrt((x1 - x2) * (x1 - x2) + (y1 - y1) * (y1 - y2));
}
int main()
{
// 데이터를 입력받음
int N;
cin >> N;
// N개의 좌표 입력받기
vector <double> x(N), y(N);
for(int i = 0; i < N; i++)
{
cin >> x[i] >> y[i];
}
// 결과 값이 들어갈 변수를 초기화(결과 값 후보보다 훨씬 큰 값)
double minimum_dist = 100000000.0;
// 탐색 시작
for(int i = 0; i < N; i++)
{
for(int j = i + 1; j < N; j++)
{
//(x[i],y[i]) 와 (x[j],y[j]) 사이 거리
double dist_i_j = calc_dist(x[i],y[i],x[j],y[j]);
// 잠정 최솟값 minimum_dist를 dist_i_j와 비교
if(dist_i_j < minimum_dist)
{
minimum_dist = dist_i_j;
}
}
}
cout << minimum_dist << endl;
}
코드를 다 보고 해석해보면 바깥쪽 i가 증가하면 할수록 j의 반복횟수는 줄어든다
따라서 for문 반복 횟수 T(N)는 아래와 같다
등차수열 합공식을 사용하여 T(N)의 값을 구했다


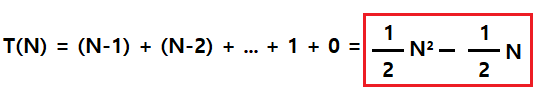
점근적 상한선을 따라서 최고차항을 제외한 값은 모두 제거하고, 상수 계수도 무시하면
알고리즘 복잡도는 O(N²)가 된다
공간복잡도
- 프로그램 실행과 완료에 얼마나 많은 공간이 필요한 지 나타내는 '척도'
- 메모리 사용량을 가리키는 것
가변 공간
- 문제를 해결하기 위해 알고리즘이 필요한 공간
- 순환 프로그램일 경우 순환 스택을 의미한다
- 예를 들면 재귀함수
고정 공간
- 코드가 저장되는 공간
- 알고리즘 실행을 위해 시스템이 필요로 하는 공간이다
브루트 포스
브루트 포스(Brute Force) 알고리즘이란,
가능한 모든 경우의 수를 탐색하면서 결과를 도출해내는 알고리즘이다
-
예시로 비밀번호 3자리를 맞추는 코드
-> 모든 경우의 수를 다 탐색해야하기 때문에 비밀번호 000 부터 999까지 다 탐색해야한다
-> 3중 for문을 작성 -
브루트 포스는 시간복잡도가 많이 크다
#include <iostream>
using namespace std;
int main()
{
#pragma region 브루트 포스
/// 비밀번호 000 ~ 999
int password[3] = { 1, 2, 3 };
for (int i = 0; i <= 9; i++)
{
for (int j = 0; j <= 9; j++)
{
for (int k = 0; k <= 9; k++)
{
if (password[0] == i && password[1] == j && password[2] == k)
{
cout << i << " " << j << " " << k << endl;
cout << "비밀번호 해제" << endl;
break;
}
}
}
}
#pragma endregion
return 0;
}