
8장 SQL의 순서
SQL 레벨업이라는 도서를 정리한 내용입니다.
8장에서는 SQL에 순서나 순번을 다루는 법을 설명한다.
현대의 SQL에서는 전통적인 집합 지형적 성향에 절차 지향적 생각이 섞인 언어로 발전하고 있다. 윈도우 함수가 대표적인 기능이다.
레코드에 순번 붙이기
이 부분에서는 여러 경우에 윈도우 함수와 상관 서브쿼리를 이용해 순번을 붙인다.
이전 장에서 설명했듯이 서브쿼리 보다는 윈도우 함수를 사용하는 것이 더 좋은 성능을 가진다.
- 기본키가 한 개의 필드일 경우
- 기본키가 여러 개의 필드일 경우
상관 서브쿼리의 경우 다중 필드 비교를 사용한다. - 그룹마다 순번을 붙이는 경우
- 순번과 갱신
기존 테이블에 순번 필드를 추가하여 순번을 갱신하는 구문을 설명한다.
레코드에 순번 붙이기 응용
테이블의 중앙값을 구하는 법
테이블의 중앙값을 구하는 방법을 알아보자.
집합 지향적인 방법
테이블을 상위 집합과 하위 집합으로 나누어서 계산하고 결합하여 구한다.
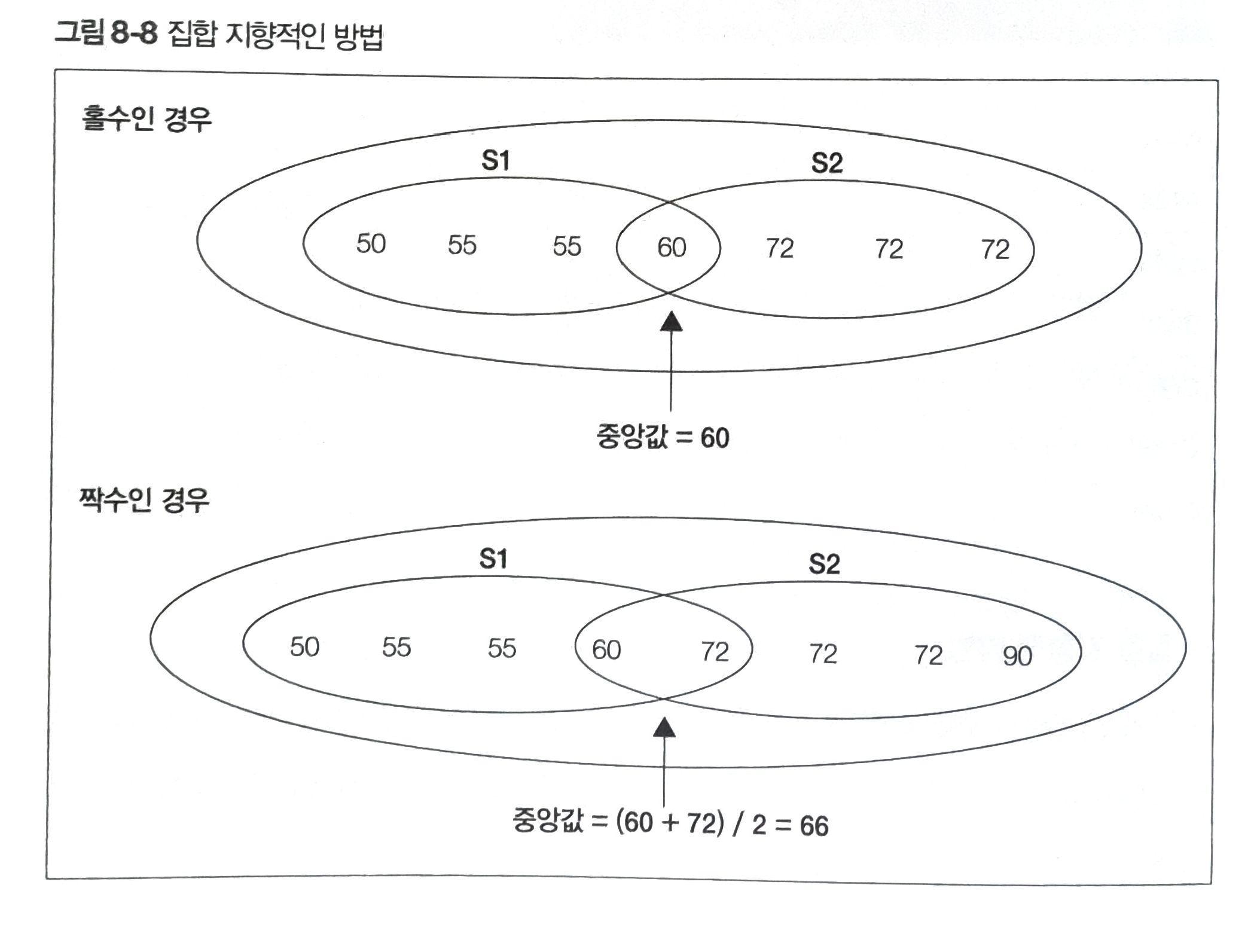
하지만 두 집합으로 나누어 결합하므로 자기 결합을 수행한다. 이는 성능 비용과 리스크가 높다는 것을 알 수 있다.
절차 지향적인 방법 - 1
SQL에서 ROW_NUMBER()를 사용하면 '양쪽 끝부터 숫자 세기'를 할 수 있다.

이러한 방법이 가장 좋은 방법을 아니다.
이 이후 코드는 생략하도록 하겠다.
절차 지향적인 방법 - 2
더 효율적인 쿼리에 대해 다룬다.
순번을 사용한 테이블 분할
테이블을 여러 개의 그룹으로 분할하는 집합 지향적인 방법과 절차 지향적인 방법을 다룬다.
시퀀스 객체, IDENTITY 필드, 채번 테이블
표쥰 SQL에는 순번을 다루는 기능으로 시퀀셜 객체와 IDENTITY 필드가 존재한다. 하지만 모두 최대한 사용하지 않는 것을 권장한다. 꼭 필요한 경우에는 시퀀스 객체를 사용하는 것을 추천한다.
시퀀스 객체
시퀀스 객체는 '객체'라는 용어에서 알 수 있듯이 테이블 또는 뷰처럼 스크마 내부에 존재하는 객체 중 하나이다. 따라서 CREATE 구문으로 정의한다.

이렇게 만들어진 겍체를 SQL 구문 내부에서 접근해 수열을 생성한다.
시퀀스 객체의 문제점
- 표준화가 늦어서, 구현에 따라 구문이 달라 이식성이 없고, 사용할 수 없는 구현도 있다.
- 시스템이서 자동으로 생성되는 값이므로 실제 엔티티 속성이 아니다.
- 성능적인 문제를 일으킨다.
경우에 따라 실무에서 1과 2는 무시되는 경우가 많지만 3은 절대로 무시할 수 없는 문제다.
기퀀스 객체로 인한 성능 문제
시퀀스 객체는 다음과 같은 특성을 가진다.
- 유일성
- 연속성
- 순서성
위 특성을 지키기 위해 시퀀스 객체가 사용되고 있다면 락이 걸려 다른 곳에서 접근할 수 없다. 또한 락을 걸고 처리하고 해제하는 과정을 매번 반복하므로 오버헤드가 발생한다.
시퀀스 객체로 인한 성능 문제의 대처
CACHE 와 NOORDER 객체로 성능 문제를 대처할 수 있다.
CACHE는 새로운 값이 필요할 때마다 메모리에 읽어들일 값의 수를 설정하는 옵션이다. 이 값을 크게하면 접근 비용을 줄일 수 있다. 대신 연속성을 담보할 수 없다. 따라서 장애가 발생하면 비어있는 숫자가 생긴다.
NOORDER 옵션은 순서성을 담보하지 않아서 오버헤드를 줄이는 효과가 있다. 다만 순서성이 보장되어야 하는 경우 사용할 수 없다.
시퀀스 객체의 성능을 튜닝할 수 있는 건 이정도 밖에 없다.
순번을 키로 사용할 때의 성능 문제
시퀀스 객체가 성능 문제를 일으키는 두 번째 경우는 핫 스팟(Hot Spot)과 관련된 문제이다.
순번, 시간처럼 연속된 데이터를 다루는 경우 역시 발생하지만 시퀀스를 다룰 때에는 거의 확실하게 발생한다.
이는 DBMS의 물리적인 저장방식 때문인데 순번 같은 연속된 데이터를 저장하는 경우 저장소의 특정 물리적 블록에만 I/O 부하가 커지므로 성능 악화가 발생한다. 이런 I/O 부하가 몰리는 부분을 핫 스팟, 핫 블록이라고 부른다.
하지만 이런 문제가 까다로운 이유는 대처가 거의 불가능하단 점이다.
순번을 키로 사용할 때의 성능 문제의 대처
Oracle의 역 키 인덱스와 처럼, DBMS 내부에서 변화를 주어 제대로 분산할 수 있는 구조를 사용하는 것이다.
또는 인덱스에 복잡한 필드를 추가해 데이터의 분산도를 높이는 방법이 있다.
하지만 둘 다 트레이드 오프가 있는 방법이다. 역 키 인덱스는 범위 검색 등에서 I/O의 범위가 늘어나고, 구현 의존적이다. 인덱스에 불필요한 키를 추가하는 방법 역시 논리적으로 필요 없는 부분을 추가하는 것이기에 좋은 설계가 아니다.
IDENTITY 필드
IDENTITY 필드는 테이블의 필드로 정의하고, 테이블에 INSERT가 발생할 때마다 자동으로 순번을 붙여주는 기능이다.
하지만 특정 테이블과 연결되어 의존적이고, 구현에 따라 시퀀스 객체처럼 튜닝도 불가능하기 때문에 IDENTITY 필드를 사용했을때 성능적 이점은 거의 없다고 봐야한다.
채번 테이블
시퀀스 객체나 IDENTITY 필드가 나오기 전 자체적으로 구현한 것을 채번 테이블 이라고 한다. 다만 요즘에는 이미 시퀀스나 IDENTITY가 있고, 사용했을 때의 성능적 이점도 거의 없어 사용하지 않는다.
