
10장 인덱스 사용
SQL 레벨업이라는 도서를 정리한 내용입니다.
인덱스와 B-tree
RDB에서 사용하는 인덱스는 구조에 따라 세 가지로 분류된다.
- B-tree 인덱스
- 비트맵 인덱스
- 해시 인덱스
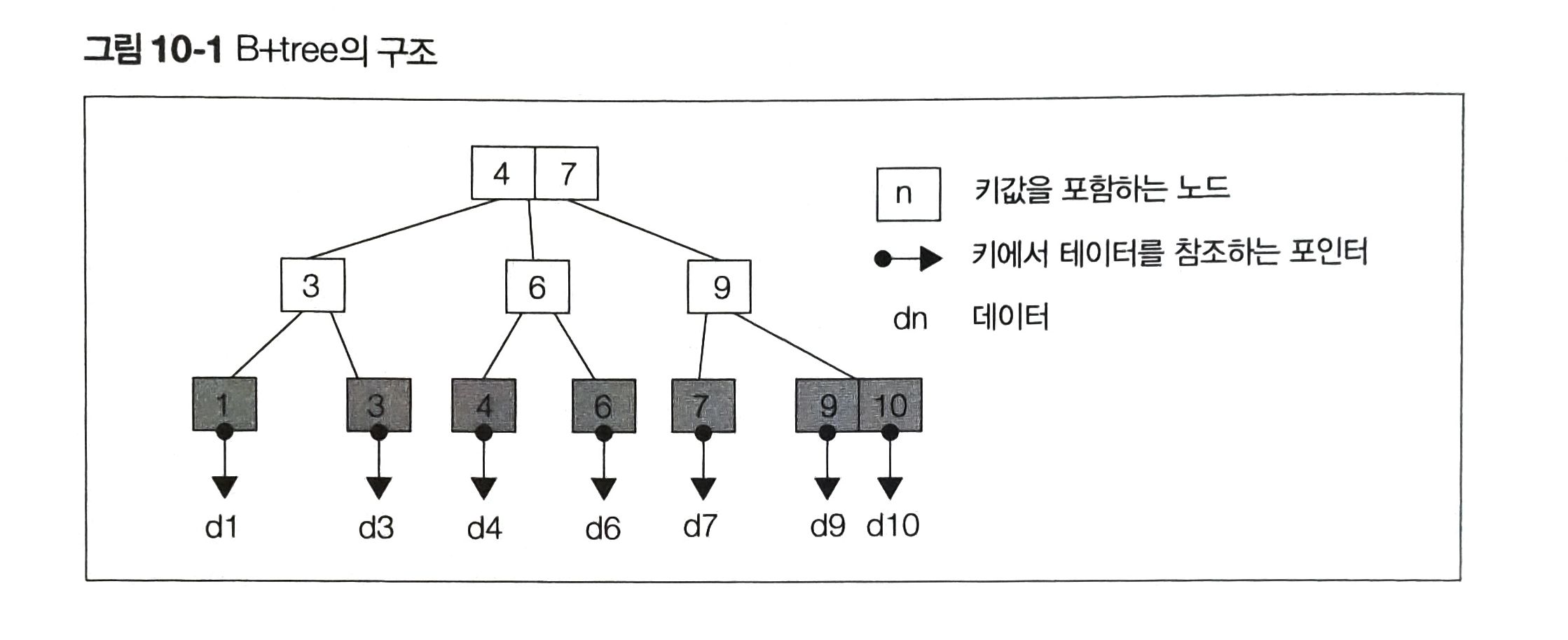
B-tree
데이터를 트리 구조로 저장하는 인덱스로, 뛰어난 범용성을 가지고 있다. 아무런 수식 없는 '인덱스'는 B-tree인덱스를 지칭하는 것이다.
사실 대부분의 DBMS는 트리의 리프 노드에만 키값을 저장하는 B+tree라는 B-tree의 수정 버전을 채택하고 있다.
기타 인덱스
비트맵 인덱스는 데이터를 비트 플래그로 반환해서 저장하는 형태의 인덱스로 카디널리티가 낮은 필드에 높은 효과를 가진다. 하지만 갱신할 때 오버헤드가 너무 크기 떄문에 빈번한 갱신이 일어나지 않는 BI/DWH 용도로 쓰인다.
해시 인덱스는 키를 해시 분산해서 등가 검색을 고속으로 질행하고자 만들어졌다. 하지만 등가 검색 외에는 효과가 거의 없고 범위 검색이 불가능 하기 때문에 자주 사용되지 않는다. 또한 지원하는 DBMS도 많지 않다.
인덱스를 잘 활용하려면
카디널리티와 선택률
카디널리티가 높고 선택률이 낮을수록 좋은 성능을 가진다.
최근 DBMS는 대체로 5~10% 이하의 선택률을 가지는 경우 인덱스를 사용하는 것을 권장하고 있다. 이 선택률을 저장소 성능 향상과 반비례 한다.
따라서 데이터의 선택률이 5~10%를 넘어가면 테이블 풀 스캔이 빠를 가능성이 커진다.
클러스터링 팩터
저장소애 같은 값이 어느 정도 물리적으로 뭉쳐 존재하는 지를 나타내는 지표이다. 높을수록 분산되어 있고, 낮을수록 뭉쳐있다는 뜻이다. 인덱스로 접근할 때는 보통 특정 값에만 접근하는 경우가 많으므로 클러스터링 팩터가 낮을수록 효율이 좋다.
인덱스로 성능 향상이 어려운 경우
압축 조건이 존재하지 않는 경우
SQL 구문이 간단해서 WHERE 구 같이 레코드를 압축하는 조건이 없는 경우 인덱스를 사용할 수 없다. 사실 실무에서 이와 같은 상황은 매우 드물다.
레코드를 제대로 압축하지 못하는 경우
레코드를 제대로 압축하지 못하는 경우는 대표적으로 아래와 같은 경우가 있다.
- 레코드를 압축 하더라도 충분히 압축되지 않는 경우
- 매게변수에 따라 선택률이 변동하는 경우
- 이는 제약을 둬서 해결할 수 있다.
인덱스를 사용하지 않는 검색 조건
- LIKE 연산자에서 중간 일치(%내용%) 이나 후방 일치(%내용)를 사용하는 경우
- 색인 필드로 연산하는 경우 (ex:
WHERE col_1 * 1.1 > 100)WHERE col_1 > 100 * 1.1이처럼 작성하면 인덱스를 사용할 수 있다.
- IS NULL을 사용하는 경우
- 부정형을 사용하는 경우
- <>, !=, NOT IN 모두 인덱스를 사용할 수 없다.
인덱스를 사용할 수 없는 경우 대처법
외부 설정으로 처리
특정 기간의 무언가를 조회하고 싶을 때 기간 검색의 최대치를 정해 두는 식으로 제한을 둘 수 있다.
이러한 입력 제한을 만들 때는 사용자 혹은 엔지니어와 충분한 소통이 필요하다.
외부 설정을 사용한 대처 방법의 주의점
이러한 제한이 많고, 과도한 경우 협업을 진행하는 다른 직원을 피로하게 하거나 사용자의 만족도를 감소시킬 수 있다.
성능과 사용성의 트레이드오프를 통해 타협점을 찾아야 한다.
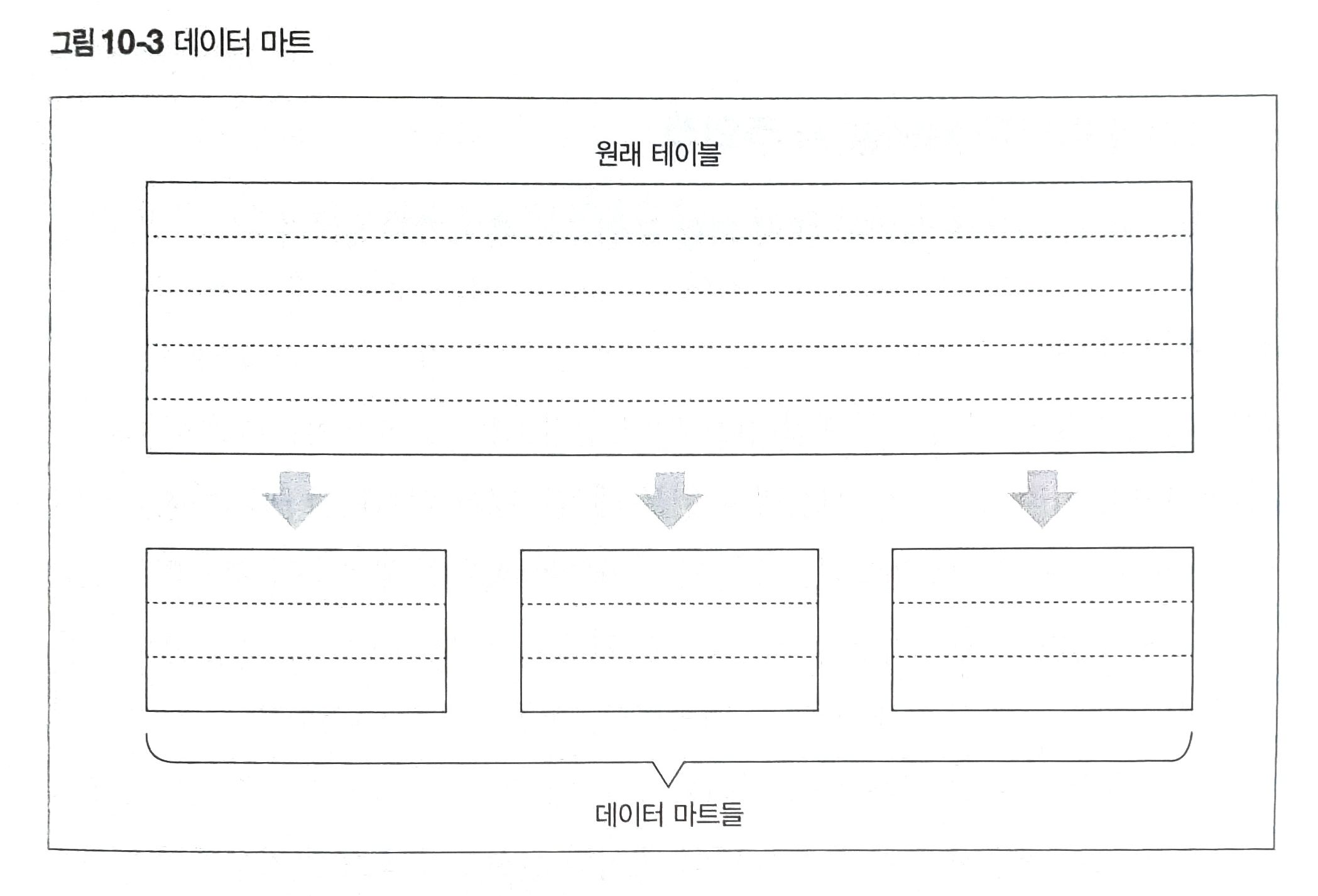
대이터 마트로 대처
데이터 마트 혹은 개요 테이블(Summary Table)이라고도 한다. 특정한 쿼리(군)에서 필요한 데이터만을 저장하는 상대적으로 작은 테이블을 의미한다.
이는 필요한 필드의 정보만 불러오기 때문에 I/O 비용을 줄일 수 있다.
대이터 마트로 대처 시 주의점
- 데이터 신선도
- 주기적으로 원래 테이블과 동기화를 해야한다. 적절한 성능과 신선도의 트레이드오프가 필요하다.
- 이 시점이 짧으면 데이터의 신선도가 높지만 성능이 감소한다.
- 이 시점이 길면 데이터의 신선도가 낮지만 성능이 상대적으로 증가한다.
- 데이터 마트 크기
- 검색 조건이 압축되지 못하는 경우 성능적인 개선이 불가능하다.
- GROUP BY 절을 미리 사용하여 집계를 마치고 데이터 마트를 만들면 필드 수와 레코드 수를 크게 줄일 수 있다.
- GROUP BY에 필요한 정렬 혹은 해시 처리도 사전에 끝내므로 굉장히 효과적이다.
- 데이터 마트 수
- 데이터 마트는 ER에도 존재하지 않으며 제대로 관리하기가 어렵다.
- 데이터 마트 수가 많아질수록 쓸데없이 리소스를 낭비하는 '좀비 마트'가 생길 확률이 높아진다.
- 배치 윈도우
- 데이터 마트를 만드는 데도 시간이 걸리므로 배치 윈도우를 압박한다.
- 이러한 처리를 수행하기 위한 배치 윈도우와 JoB Net도 고려해야 한다.
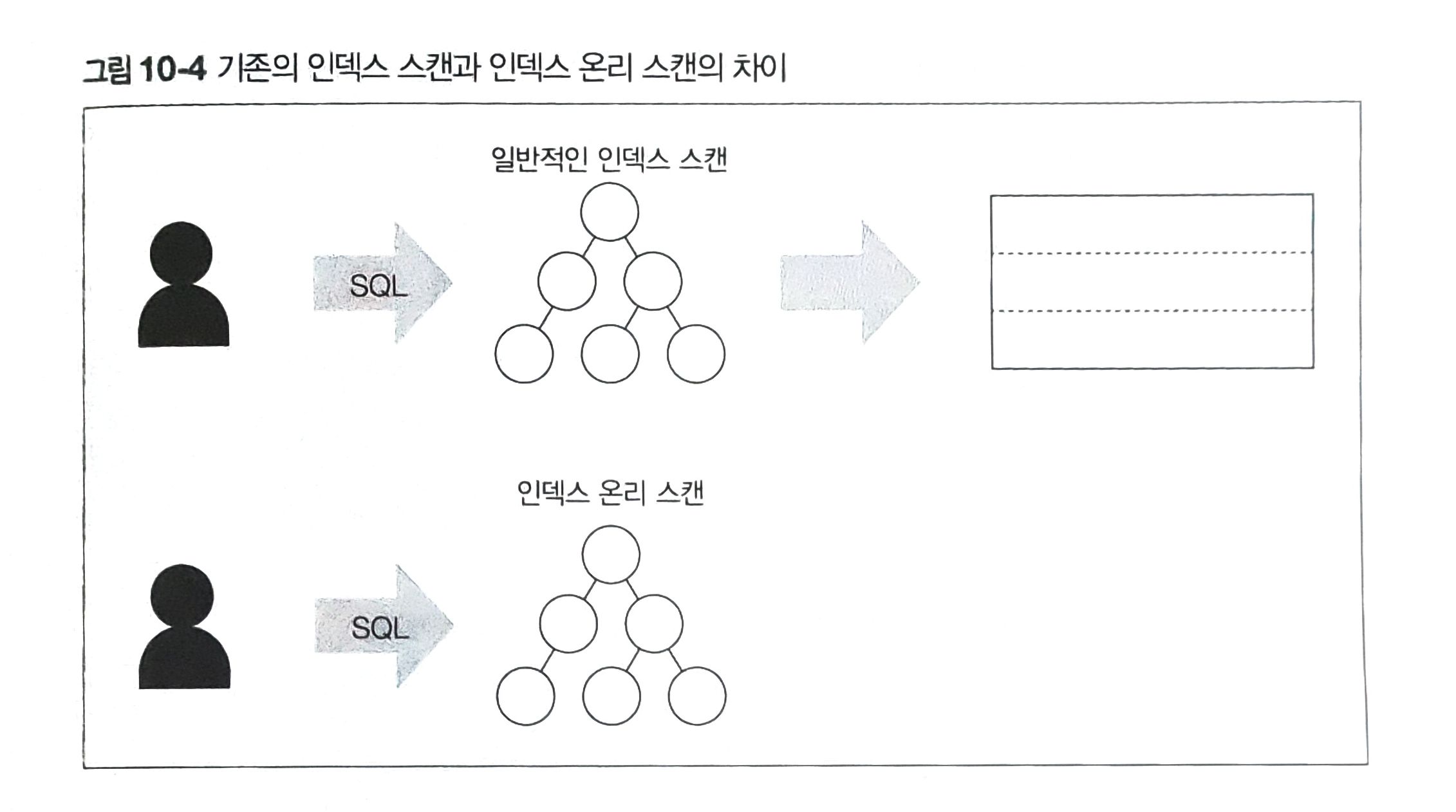
인덱스 온리 스캔으로 대처
인덱스 온리 스캔은 SQL 구문에서 필요한 필드를 인덱스로 커버할 수 있는 경우에 테이블 접근을 생략하는 기술이다.
이는 필요한 필드의 정보만 불러오기 때문에 I/O 비용을 줄일 수 있다.
데이터 마트와 달리 애플리케이션의 수정이 필요 없다.
인덱스 온리 스캔으로 대처 시 주의사항
- DBMS에 따라 사용할 수 없는 경우도 있다.
- Oracle, SQL Server, PostgreSQL, MySQL 모두 지원하지만 오래된 버전인 경우 지원하지 않을 수도 있다.
- 한 개의 인덱스에 포함할 수 있는 필드 수에 제한이 있다.
- 애초에 인덱스가 너무 커지면 인덱스 온리 스캔을 사용할 이유가 희미해진다.
- 갱신 오버 헤드가 커진다.
- 검색 속도와 갱신 성능의 트레이드오프
- 정기적인 인덱스 리빌드
- 인덱스에만 접근한다는 것은 검색 성능 자체가 인덱스의 크기에 의존한다는 것이다.
- 따라서 인덱스의 크기에 민감하게 반응하므로 정기적인 모니터링과 리빌드의 대상이 된다.
- SQL 구문에 새로운 필드가 추가된다면 사용할 수 없다.
- 이러한 점에서 일반적인 인덱스보다 더 유지 보수에 약한 튜닝이다.
