
서론
데이터를 그룹화하는 것, 즉 데이터를 집계하는 것인 데이터베이스 상에서 상당히 중요한 개념이다.
GROUP BY = SQL에서 데이터를 그룹화하는 방식
왜 데이터(행)를 그룹화 해야 할까?
→ !!다양한 계산을 하기 위해서!!(== 집계 함수를 사용하기 위해서) 그룹화한다.
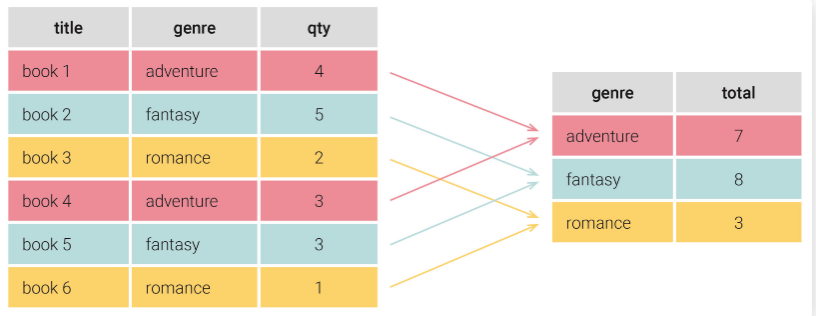
GROUP BY는 같은 값을 가진 행끼리 하나의 그룹으로 뭉쳐준다.
위 예시에서 “나는 장르가 adventure인 책들의 총 재고 숫자를 보고 싶어” 라는 요구 사항이 있을 때 장르 별로 그룹을 나눈 후, 각 그룹에 해당하는 값을 계산하면 된다.
이 때 GROUP BY가 사용된다는 것이다.
또 다른 예시들을 통해서 더 자세히 알아보자.
아래 테이블은 우리 식당에 방문하는 고객의 데이터를 분석하는 VISIT 테이블이다.
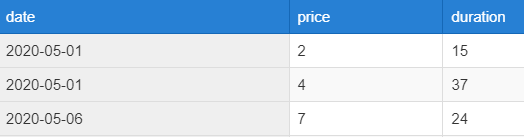
date는 한 고객이 식당에 방문한 날짜를 의미한다.
price는 고객이 식당에 와서 지불한 금액을 나타낸다.
duration은 고객이 식당에 머물렀던 시간을 나타낸다.
1. GROUP BY + 1개의 열
요구 사항 : 날짜별로 얼마나 많은 사람들이 방문했는지를 살펴보고자 한다.
그러면 날짜별로 그룹을 만들고, 해당 그룹의 총 사람 수를 체크하면 되겠네?
SELECT date, count(*)
FROM VISIT
GROUP BY date;이 때 로 집계함수를 사용하면 NULL 값이 포함된 행까지 계산하고, 열 이름으로 집계함수를 사용하면 NULL 값을 제외한 행까지 계산한다.*
→ 그래서 count()를 쓰는구나*
2. GROUP BY + N개의 열
요구 사항 : 월별 지불 금액의 평균 금액을 살펴보고자 한다.
그러면 date에서 연도와 월을 추출한다음에 이를 그룹화하고, AVG(price) 하면 되겠네
SELECT AVG(price) as avg_price
FROM VISIT
GROUP BY EXTRACT(year FROM date), EXTRACT(month FROM date);이렇게 2개(N개)의 열을 기준으로 데이터를 그룹 짓는다면 아래와 같은 과정을 거친다.
- 첫 번째로 그룹화한 연도별로 먼저 그룹을 짓는다.
- ex) 2020년도에만 해당하는 행들로 그룹 짓는다.
- 1번으로 그룹화된 데이터를 또 한번더 그룹 짓는다.
- ex) 2020년 그룹 중 5월에 해당하는 행들만 그룹 짓는다.
위 SQL문은 길이가 기니 아래와 같이 Select 열의 순서로만 그룹화할 수 있다.
SELECT EXTRACT(year FROM date) as year, EXTRACT(month FROM date) as month, AVG(price) as avg_price
FROM VISIT
GROUP BY 1, 2;*SELECT 문에 있는 모든 열은 집계 함수가 되거나 GROUP BY 절에 반드시 나타나야 한다. 만약 SELECT 문에 집계 함수를 사용하지 않거나, GROUP BY 절에 언급되지 않은 열이 존재하면 오류가 발생한다.*
3. GROUP BY + 조건(HAVING and WHERE)
요구 사항 : 일별 평균 머무른 시간을 알고 싶다. 단 일별 방문 고객 수가 3명보다 많고, 해당 방문의 머무른 시간이 5분보다 길었으면 한다.
내가 내린 답 : 일별 평균 머무른 시간은 date별로 그룹화를 해서 AVG(duration)을 하면 된다 조건은 2가지인데, 일별 방문 고객 수가 3명보다 많은 것은 그룹화가 먼저 진행되어야 할 수 있는 조건이고(=GROUP BY), 해당 방문의 머무른 시간이 5분보다 긴 데이터들은 그룹화 전에 진행되어야 할 조건이다.(=WHERE)
SELECT date, AVG(avg_duration) as avg_duration
FROM VISIT
WHERE duration > 5
GROUP BY date
HAVING count(*) > 3;아니 그러면 Having 절 말고, 그냥 Where 절 쓰면 되는거 아닌가?
where은 기본적인 조건절로서 우선적으로 그룹화 하기 전 모든 필드를 조건에 둘 수 있다.
하지만 having은 group by 된 이후 특정한 필드로 그룹화 되어진 새로운 테이블에 조건을 줄 수 있다.
그렇기에 having 절은 GROUP BY 절 뒤에 적혀있다.
즉, 전체 테이블 자체에서 쿼리를 수행하고 싶다면 where를, 전체 테이블을 그룹화 한뒤, 그 해당 그룹에서 어떠한 조건을 걸어 가져오고 싶다면 having을 사용한다.
추가 정보
- WHERE 절에는 집계 함수가 올 수 없다.
- WHERE 절은 전체 데이터를 GROUP으로 나누기 전에 행들을 미리 제거하기 때문에 성능상 효과적이다.
- HAVING 절에는 GROUP BY 절의 기존 항목이나 소그룹의 집계 함수를 사용해서 조건을 표시해야한다.
- GROUP과 HAVING은 ORDER BY 없이는 정렬할 수 없다.
레퍼런스
