
서론
현재 내가 담당 해서 운영 중인 이커머스 플랫폼에서 갑자기 응답이 느려졌다. 상품 조회 페이지가 특히 심했고, 사용자들로부터 "페이지가 안 열린다"는 문의가 들어오기 시작했다.
바로 쿠버네티스 대시보드를 열어 파드 상태를 확인 했는데, 대시보드 화면에는 모든 파드가 Running이다. Restart도 없고 정상인데 왜 느리지?
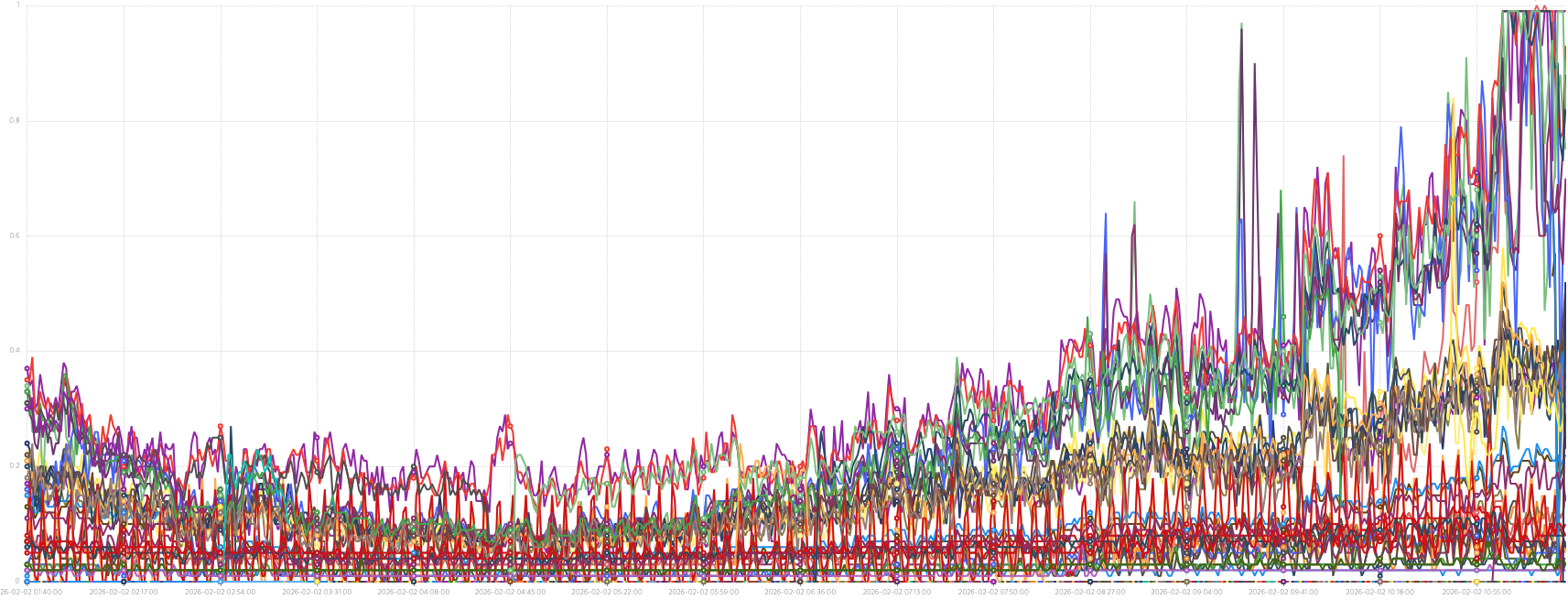
현재 문제가 있는 서비스의 네임스페이스 CPU 사용량을 보니 100%에 달하고 있었다.
파드는 멀쩡하게 돌아가고 있었지만, 내부적으로는 CPU가 한계에 부딪혀 요청을 제때 처리하지 못하고 있었다.
이번 글에서는 해당 문제 처리 과정과 문제 발생 원인에 대해서 다뤄보고자 한다.
본론
CPU Throttling
서론에서 언급했던 “파드는 멀쩡하게 돌아가고 있었지만, 내부적으로는 CPU가 한계에 부딪혀 요청을 제때 처리하지 못하고 있었다.” 라는 현상은 CPU Throttling으로 인해 발생한 문제였다.
CPU Throttling은 컨테이너가 설정된 CPU Limit에 도달했을 때, Linux CFS(Completely Fair Scheduler)에 의해 CPU 사용이 강제로 제한되는 현상이다.
이를 비유하자면 고속도로에서 속도 제한에 걸린 자동차와 같다.
엔진(노드)에는 여유가 있지만, 속도 제한(CPU Limit)이 걸려 있어 더 빠르게 달릴 수 없는 상황이다.
차(파드)는 정상적으로 주행하고 있기 때문에 겉으로 보기에는 문제가 없어 보인다.
다만 속도가 현저히 느려질 뿐이다.
CPU Throttling의 가장 큰 문제는 이러한 특성 때문에 문제 인지가 어렵다는 점이다.
파드 상태는 Running으로 정상이며, OOMKill처럼 파드가 재시작되지도 않는다.
로그에도 명확한 에러가 남지 않고, 결과적으로 서비스 응답만 느려진다.
실제로 대시보드에서 파드 목록만 확인했을 때는 해당 문제가 원인이라고 전혀 인지하지 못했다.
이후 CPU 사용량 메트릭을 직접 확인하면서 CPU Throttling이 발생하고 있음을 확인할 수 있었다.
장애 원인
이번 장애의 시작은 코드 버그도, 인프라 결함도 아니었다.
외부 커뮤니티(뽐뿌)에 우리 플랫폼 링크가 포함된 게시글이 게시되었고, 이를 통해 단시간에 대량의 사용자가 유입되었다.
해당 사용자들이 상품 조회 API를 집중적으로 호출하면서, 상품 관련 파드들에 부하가 집중되었고 이로 인해 CPU Throttling이 발생했다.
해결 과정
가장 먼저 Horizontal Pod Autoscaler(HPA)의 최소 파드 수를 늘리는 조치를 진행했다.
상시 운영되는 파드 수를 증가시켜, 갑작스러운 트래픽이 유입되더라도 요청이 더 많은 파드로 분산되도록 하기 위함이었다.
변경 전
# git-ops/apps/overlays/prod/hpa/my-service.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-service-prd
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-service-prd
minReplicas: 5
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70변경 후
# git-ops/apps/overlays/prod/hpa/my-service.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-service-prd
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-service-prd
minReplicas: 10
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70minReplicas를 5에서 10으로 늘렸다.
동일한 트래픽이 유입되더라도 요청이 10개의 파드로 분산되면서, 개별 파드의 CPU 사용률이 크게 낮아졌다.
이 조치만으로도 서비스 응답 속도는 정상 수준으로 회복되었다.
다만, 이번 문제를 근본적으로 해결하기 위해 파드당 CPU Limit 설정 역시 재검토했다.
HPA로 파드를 확장하더라도, 파드 하나당 할당된 CPU Limit 자체가 낮다면 동일한 문제가 반복될 수 있기 때문이다.
변경 전
# git-ops/apps/base/my-service/deployment.yaml
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: "1"
memory: 2Gi변경 후
# git-ops/apps/base/my-service/deployment.yaml
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: "2"
memory: 2GiCPU Limit을 1 Core에서 2 Core로 상향 조정했다.
Base 설정이 3 Core였던 점을 고려하면, 2 Core 역시 비교적 보수적인 수치다.
다만 무작정 Limit을 높일 경우 노드 리소스를 과도하게 점유할 수 있으므로, 이후에도 모니터링을 통해 적정 수준을 지속적으로 조정할 계획이다.
결론
이번 장애를 통해 대규모 트래픽 상황에 대한 사전 대비 경험이 아직 충분하지 않다는 점을 다시 한 번 느끼게 되었다.
이벤트성 트래픽 증가 자체는 어느 정도 예측 가능한 범위였고, 해당 수준까지는 수용 가능하도록 설정해 두었다고 생각했다.
하지만 외부 커뮤니티에 게시된 단 하나의 게시글이 트래픽을 폭증시켰고, 그동안 문제없이 동작하던 리소스 설정이 순식간에 병목으로 변했다.
장애가 발생하지 않도록 하는 것이 운영자의 역할이지만, 실제로 발생한 장애를 통해 얻는 학습 역시 매우 크다고 느꼈다.
이번 경험을 계기로, 트래픽 패턴 변화에 대한 대비와 리소스 설정에 대해 더 깊이 고민해보게 되었다.
