1. 정의 - Array(List)
- JavaScript 에서는 Array, Python에서는 List
- Array(List)는 가장 기초적이고 단순하면서도 가장 자주 사용 되는 자료 구조입니다.
일반적으로 Python 에서는 Array 보다 일반 List 가 더 많이 사용 되고 대부분의 경우 큰 차이가 없음으로 그냥 List 를 사용하면 됩니다.
사실 Python 에서는 List 가 Array 라고 생각하고 써도 무방합니다. 다만 엄밀히 말하자면 Array 와 List 는 다릅니다. 기능적으로는 거의 동일하지만 메모리 효율면에서는 Array 가 유리합니다. 다만 사용하기에는 List 가 훨씬 편합니다. (Python 에서 Array 를 사용하려면 import Array 모듈을 import 해서 사용해야 합니다.)
2. Array 특징
순차적으로 데이터를 저장하는 자료 구조
- Array의 가장 큰 특징은 순차적(ordered)으로 데이터를 저장한다는 점입니다.
- 자료구조에 저장하는 데이터는 일반적으로 요소(element)라고 합니다).
- Array는 주로 서로 연결된 데이터들을 순차적 으로 저장할때 사용합니다.
- 순서가 상관 없더라도 서로 연결된 데이터들을 저장할때 일반적으로 사용됩니다.
- 그래서 array가 가장 자주 사용되는 자료구조중 하나가 되는 것입니다.
기타 특징
- 삽입(insertion) 순서대로 저장됩니다. (즉, 새로 삽입되는 요소는 array의 새로운 꼬리가 됩니다.)
- 이미 생성된 리스트도 수정 가능합니다(mutable).
- 동일한 값도 여러번 삽입 가능합니다.
- Multi-dimentional Array(다중차원 배열)
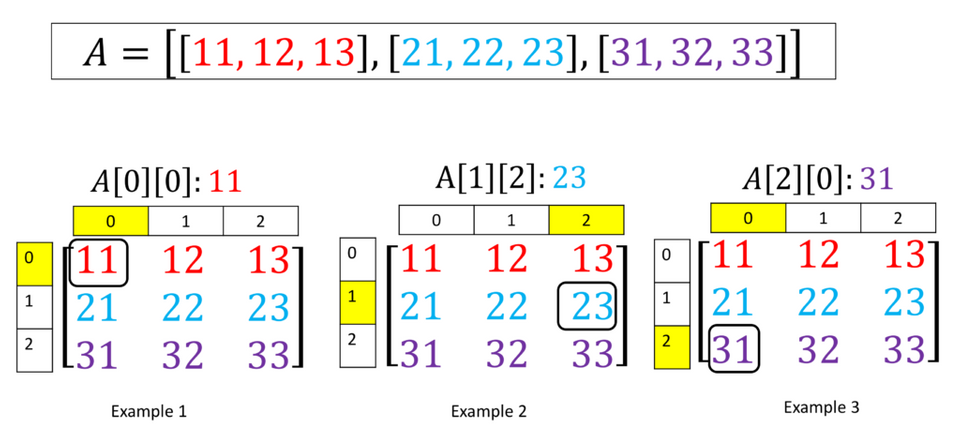
3. Array 내부 구조
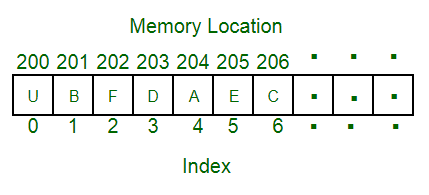
- Array의 가장 큰 특징은 순차적으로 데이터를 저장하는 것이었습니다.
- 이렇게 순서가 있다보니 당연히 순차적으로 번호를 지정할 수 있습니다. 마치 학교에서 이름을 부르지 않고 번호를 불르는 것과 동일한 개념입니다. 이 번호를 index 라고 합니다.
- Index는 0부터 시작됩니다. Index는 마이너스 부호를 가질 수 도 있습니다. 마이너스 index는 맨 마지막 요소 부터 시작합니다. 예를 들어, -1 은 맨 마지막 요소입니다.
그렇다면 왜 Array가 순차적으로 데이터를 저장할 수 밖에 없을까요?
- 그건 바로 실제 메모리 상에서, 즉 물리적으로 데이터가 순차적으로 저장되기 때문입니다.
- 데이터에 순서가 있기 때문에
- 1) index가 존재하며
: 0부터 시작하는 index - 2) Indexing
: Index를 사용해 특정 요소를 array(list)로 부터 읽어 들이는 것이 가능하고 - 3) Slicing
: 요소의 특정 부분, 즉 n번째 index부터 m번째 index까지 따로 분리해 조작하는 것이 가능합니다.
- 1) index가 존재하며
4. 단점
앞서 본대로 Array는 메모리의 실제 주소도 순차적으로 되어있습니다. 그렇기 때문에 indexing이 가능한 것을 비롯하여 여러 가지 장점이 있지만 반대로 단점도 존재합니다. 이번에는 몇 가지의 단점에 대해 배워보도록 하겠습니다.
1. Removing or Adding Elements
- 중간의 특정 요소를 삭제해야 하는 경우를 가정해보겠습니다.
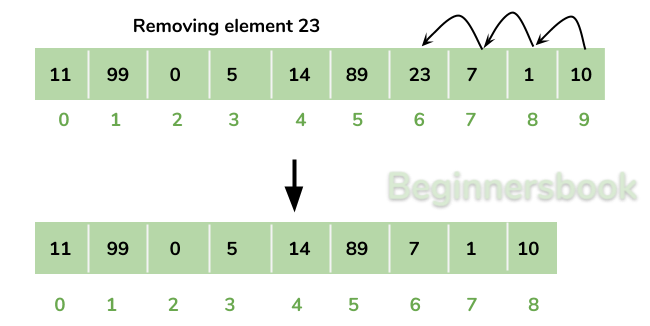
- 순차적으로 담겨있는 데이터 중 특정 위치에 있는 중간의 요소가 삭제 되는 경우에,
- 항상 메모리가 순차적으로 이어져있어야 하기 때문에, 삭제된 요소로 부터 뒤에 있는 모든 요소들을 앞으로 한칸씩 이동시켜주어야 합니다.
- 이뜻은 배열에서 요소를 삭제하는 것은 다른 자료 구조에 비해 느릴 수 있다는 뜻입니다.
- 요소를 삭제하는 과정이 코드 상에서는 한 줄 이지만 실제 메모리 상에서 이루어지는 작업(operation)은 훨씬 커집니다.(expensive operation)
- 중간에 요소가 추가 되는 경우도 마찬가지 입니다. 특정 위치에 새롭게 요소가 추가되는 경우에는 그 뒤의 요소들이 하나씩 밀리게 됩니다.
- 그렇기 때문에 Array 는 정보가 자주 삭제 되거나 추가되는 데이터를 담기에는 적절치 않습니다.
2. Array Resizing
-
Resizing 이란, 말 그대로 사이즈를 다시 조정한다는 뜻입니다.
-
배열은 메모리가 순차적으로 채워지기 때문에 배열이 처음 생성될 때 어느 정도 메모리를 미리 할당합니다.
-
이를 전문 용어로 pre-allocation 이라고 합니다.
-
메모리를 pre-allocation 함으로써 새로 추가되는 요소들도 순차적으로 메모리에 저장될 수 있습니다.
-
하지만 요소들이 처음 할당한 메모리 이상으로 많아진다면 resizing이 필요합니다.
-
즉, 메모리를 더 할당해야 합니다.
-
그리고 추가적으로 할당된 메모리 또한 순차적이어야 합니다.
-
그럼으로 배열의 resizing은 상대적으로 오래걸리는 operation 입니다.
- 100개의 메모리 공간 다 차서 100개를 추가해야 되는 경우
- 200개 크기의 메모리를 생성 후 > 기존 100개를 복사하고 > 그 다음 101번 부터 데이터가 순차적으로 추가됩니다. OMG🤢
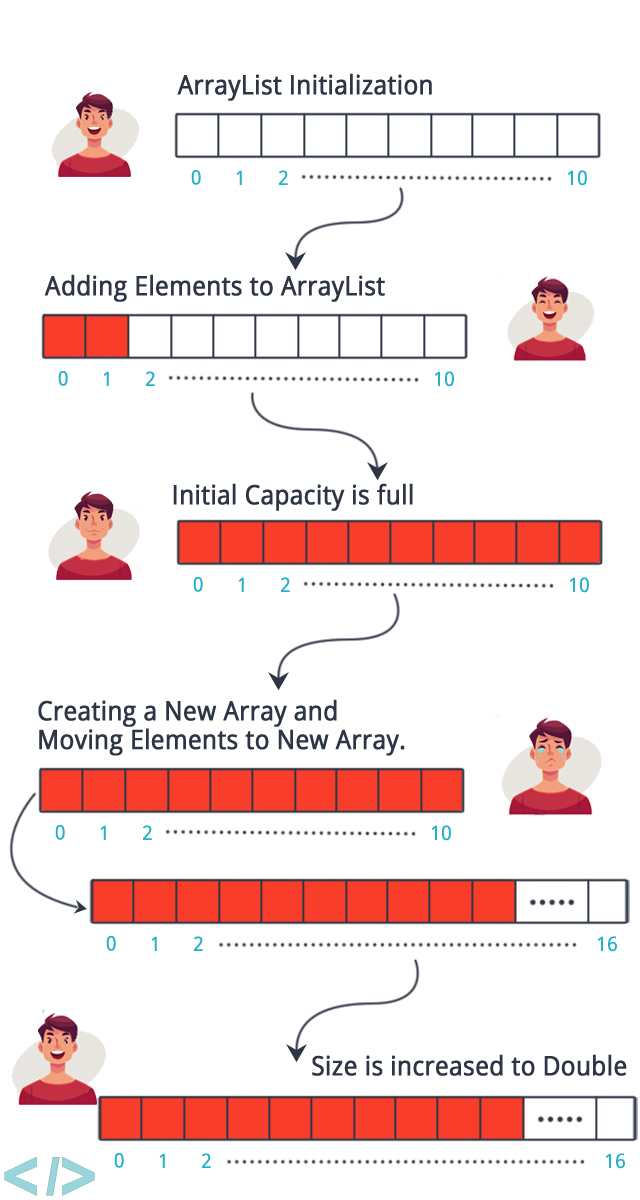
- 200개 크기의 메모리를 생성 후 > 기존 100개를 복사하고 > 그 다음 101번 부터 데이터가 순차적으로 추가됩니다. OMG🤢
- 100개의 메모리 공간 다 차서 100개를 추가해야 되는 경우
-
그렇기 때문에 Array 는 사이즈 예측이 잘 안 되는 데이터를 다루기에는 적절치 않습니다.
-
일반적으로 대부분의 언어에서는 배열의 메모리 pre-allocation과 resizing을 자동으로 실행합니다. 하지만 이러한 점을 알고 있어야 사이즈가 급격하게 자주 늘어날 확률이 있는 데이터는 array 말고 더 적합한 자료구조를 선택해야 한다는 것을 알 수 있습니다.
5. 언제 사용하면 좋을까요?
- 순차열적인 데이터를 저장할 때
- ex) 주식 가격. 어제의 2만원과 오늘의 2만원이 다름 >>> 값보다는 순서가 중요한 데이터
- 다차원 데이터를 다룰 때 >>> Multi-dimensional Array
- 어떠한 특정 요소를 빠르게 읽어야 할 때 >> index를 통해 곧바로 읽을 수 있기 때문
- 데이터의 사이즈가 급변하게 자주 변하지 않을 때
- 요소가 자주 삭제 되거나 추가되지 않을 때
