이진 인덱스 트리
구간합을 이내에 구할 수 있는 자료구조입니다.
그러면 이런 이진 인덱스 트리를 사용하는 이유는 무엇일까요?
다음과 같은 배열 A가 주어졌다고 가정해 봅니다.
A
| 1 | 2 | 0 | 4 | 1 | 3 | 5 | 9 | 8 | 6 |
이 때, 라 정의할 때, 이므로 시간 복잡도는 으로 구간합을 구할 수 있습니다.
만약, 이런 을 번 구할 경우, 시간 복잡도는 이 되게됩니다.
하지만 전처리과정을 통해 시간 복잡도를 으로 줄일 수 있습니다.
전처리 과정을 저장할 배열 P를 선언하고 를 저장하면 다음과 같이 배열 P가 주어집니다.
P
| 1 | 3 | 3 | 7 | 8 | 11 | 16 | 25 | 33 | 39 |
따라서 이제 이 걸리던 구간합을 안에 바로 구할 수 있습니다.
예를 들어 를 구할 경우 임을 바로 알 수 있습니다.
다음과 같이 A 배열의 구간 5~8위치의 합을 이라 할 때, 마찬가지로 시간 복잡도 에 구할 수 있습니다.
이므로 전처리과정을 통하여 시간복잡도 로 빠르게 구할 수 있음을 알 수 있습니다.
하지만 만약 A배열의 5번째 위치의 값이 1이 아닌 3으로 바뀌게 된다면 구간합을 구하는 전처리 배열을 다시 구해 주어야 합니다.
이런 배열의 k위치의 값을 x로 바꿔주는 함수를 라 하고 다시 전처리 배열을 구하는데 걸리는 시간복잡도는 입니다.
이 때, Binary Index Tree를 사용할 경우, 가 수행될 때, 다시 전처리 배열을 에 구할 수 있습니다.
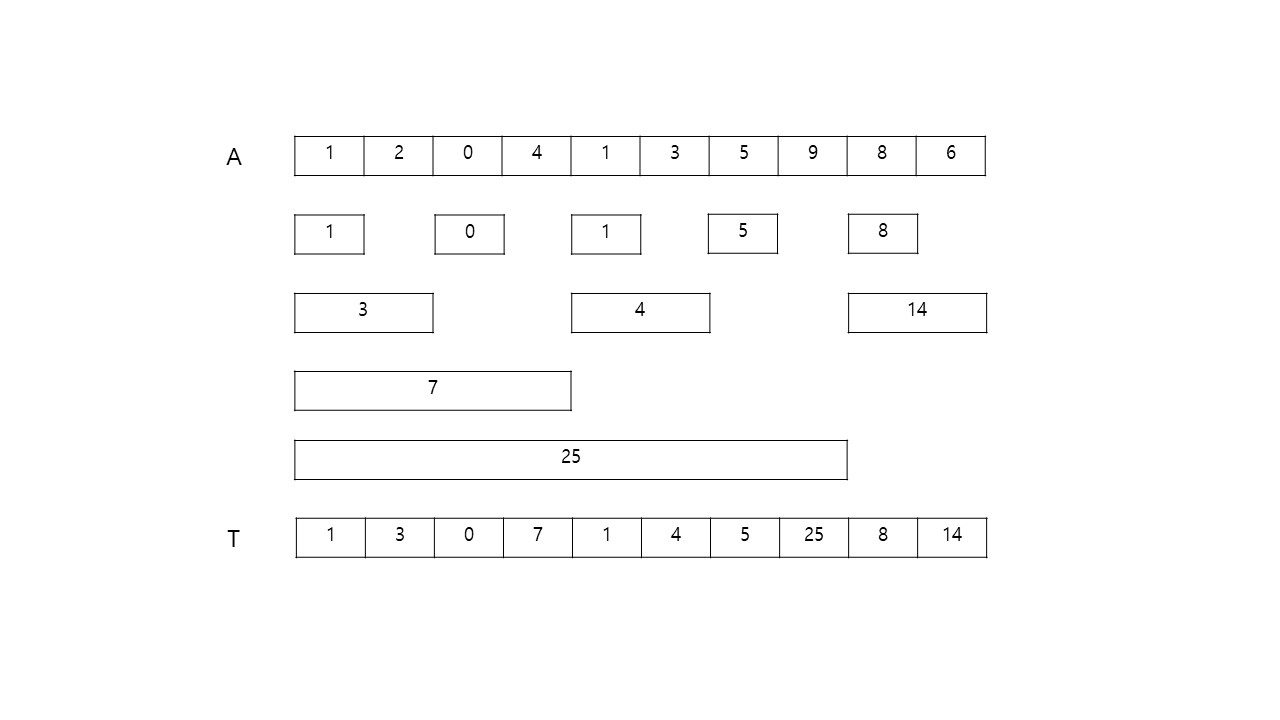
이진 인덱스 트리로 사용할 배열 T를 먼저 선언해줍니다.
그리고 다음 수식처럼 T의 각 위치에 A배열의 구간합을 나누어 넣어줄 것입니다.
그러면 각 위치에 저장할 구간합을 어떻게 나누어 저장해야 할까요?
바로 와 같이 저장합니다.
이 때, 는 를 비트로 나타냈을 때, 오른쪽끝에서 왼쪽끝으로 이동하면서 처음 1이 등장하는 위치가 d일 때, 로 구해줍니다.
따라서, 일 때, 비트로 표현하면 110 이고, 처음 1이 등장하는 위치인 d는 1이므로 가 됩니다.
그러므로 가 저장되게 하면 됩니다.
이대로 T 배열을 모두 구하면 다음과 같이 구해집니다.
그러면 의 시간복잡도는 과연 어떻게 될까?
를 구하는데 오래 걸리면 효율적이지 못하므로 먼저 의 시간 복잡도를 구해봅니다.
다음과 같이 비트가 01101000인 k가 주어졌다고 가정해봅니다.
이 때, k의 2의 보수 (= 1의 보수 +1)를 구하면 입니다.
이를 k와 &연산하면 로 상수시간 안에 를 구할 수 있음을 알 수 있습니다.
그러면 T에 저장된 각 구간의 합을 이용하여 어떻게 원하는 구간의 합을 구할 수 있을까요?
배열 T를 보면 각 누적합이 트리 형태와 유사하게 저장되어 있습니다.
이 때, 각 누적합은 LSB를 사용하여 구간을 나누었으므로 구하고자 하는 를 구할 때, 시작 위치를 k로 두고 k에서 를 계속 빼주어 k값이 0이 될 때까지 T배열의 위치를 이동시키면서 각 구간의 합을 합해주면 구할 수 있습니다.
def prefix_sum(k):
s = 0
while k>=1: # 1의 개수만큼 복잡도를 가짐, k<=n, O(log n)
s= s+T[k]
k = k - LSB(k)
return s
마찬가지로 배열의 값이 변경되었다면,
def update(k,x): #A[k] -> x로 체인지
d= x-A[k]
while k <= n:
T[k] = T[k] + d
k = k + LSB(k)따라서 이진 인덱스 트리(펜윅트리)를 사용할 경우, 각 구간 합과 구간의 변경을 에 구할 수 있습니다.
