DBCP 알아보기
API 요청의 흐름
api 요청은 아아주 간단하게 다음과 같은 흐름으로 이뤄진다.(스프링부트 톰캣 환경)
- 클라이언트가 백엔드 서버에 api 요청을 보낸다.
- 서버는 서비스를 처리하기 위해 DB에 쿼리를 요청한다.
- DB는 쿼리 요청을 처리해 서버에 응답한다.
- 백엔드 서버는 클라이언트에 응답을 보낸다.
클라이언트와 백엔드 서버는 HTTP로 통신한다. 그럼 서버와 DB는 어떤 연결로 통신을 할까?
TCP/IP Connection
서버와 DB는 TCP/IP 연결로 통신을 한다고 한다. TCP/IP 연결은 연결을 맺을 때 3way handshaking, 연결을 해제할 때 4way handshaking을 진행하기 때문에 연결에 필요한 시간적인 비용이 큰 작업이라고 할 수 있다.
그럼 서버와 DB가 쿼리요청을 보낼 때 마다 새롭게 연결을 해야한다면 얼마나 큰 손해일까? 초당 10건의 요청이 들어오고, 해당 요청을 쿼리 레벨에서 0.1초 안에 처리할 수 있어도, 연결을 맺고 끊는 부분에서 네트워크 상황에따라 수십 ms에서 길면 수백 ms까지 걸릴 수도 있을 것이다.
비즈니스 로직을 처리하는것도 바빠 죽겠는데 서버끼리 악수나 하고있느라 시간을 보내면 정말 이토록 손해가 있을까? 이를 보완하기 위해 등장한것이 DBCP이다.
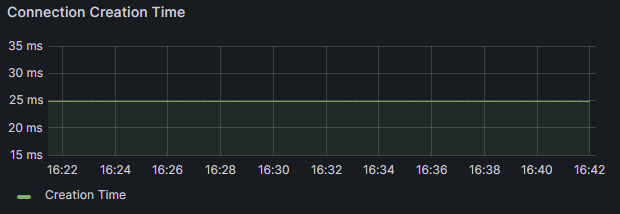
현재 운영중인 서버의 안정적인 환경에서 연결 생성시간이 무려 25ms나 된다.
DBCP(database connection pool)
직역하자면 데이터베이스 연결 모음(주머니?)정도로 할수 있겠다. 연결의 모음이란 무엇인가.. 그건 바로 요청이 들어올때마다 새롭게 연결을 만드는게 아니라 미리 연결을 해놓은 채로 Pool이라는 곳에 저장했다가, 쿼리 요청이 올때마다 서버의 쓰레드에 해당 연결을 할당시켜 DB 작업을 처리시키는 것이다.
그럼 연결을 유지시킨다는건 뭐여??
기본적으로 jdbc는 연결을 connection 객체를 생성하고, 미리 pool에 저장해놓는다고 한다.
그러면 위 문장에서 의문이 생길것이다.
1. connection 객체는 뭐지?
2. pool에 저장한다라는건 어떤 개념이지?
connection 객체는
Connection connection = DriverManager.getConnection(address, userName, password);형태로 connection을 얻어올 수 있게 만들어지는데, 이 주소값, db아이디, 패스워드를 미리 기억한 채 연결을 유지하고있는 것이 connection 객체이다.
그럼 connection은 어떻게 유지되는 것이고 저장한다는 건 어떤 개념일까?
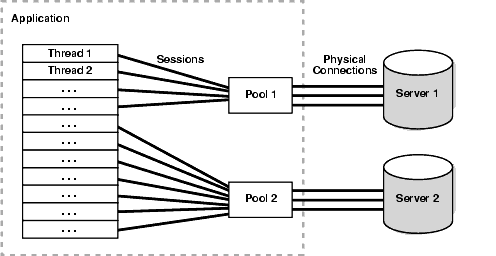
앞서 서버와 DB 연결은 TCP/IP 통신을 통해 이뤄진다고 했다. tcp는 한번 연결을 맺고나면 따로 끊기전까지는 연결을 유지하고 있기 때문에 connection pool에 10개의 연결을 유지하겠다라는 건 10번의 TCP 연결을 맺고, 연결을 끊지않은채로 인스턴스로 보관하며 기다리다가 특정 메서드(api 요청)에서 연결을 요청하면 해당 연결정보를 전달해주는 것이다.
설정 방법은?
설정 방법은 DB의 입장에서 내가 제공해줄 수 있는 최대 연결을 제어하는 부분과, 연결을 갖다 쓰는 서버 입장에서 몇개의 연결을 유지할지 설정해줄 수 있다.
MySQL, Spring Boot(hikariCP)환경에서 설정에 대해 간단히 알아보겠다.
MySQL
max_connections:
클라이언트와 맺을 수 있는 최대 connection 수, 여기서 말하는 클라이언트란 스프링 서버를 포함한 db에 접근을 요청하는 모든 무언가라고 할 수 있다.
max connection 보다 많은 커넥션 요청을 보낼 경우, db는 더이상 연결을 맺어주지 않고 too many connections 에러를 응답한다. 운영중인 서버와, 로컬 환경에서 db 접근을 위해 남겨놓을 connection까지 적절히 관리하는 것이 중요하다.
불필요하게 max_connection을 너무 많이 설정해 무수한 연결을 허용해놓을 경우 CPU와 메모리를 소모하는 연결작업이 불필요한 오버헤드를 발생시켜 서버 부하를 발생시킬 수 있다. 또한 네트워크 트래픽도 증가해 네트워크 병목을 발생시킬 수 있다. 서버 성능에 맞는 적절한 connection 설정이 필요한 부분이다.
wait_timeout
DB에서 클라이언트에게 할당해준 연결이 이 설정값보다 늘어날 경우 연결을 강제로 끊어버리기 위한 설정이다. 비정상적인 연결 종료, 연결을 다 쓴 뒤 반환이 안되거나, 네트워크가 단절되거나, 쿼리가 너무 오래걸리거나 등의 연결을 너무 오래 유지하는 상황이 생길 때 연결을 끊어버리기 위함이다.
이 설정을 너무 길게 한다면 비정상적인 동작 흐름임에도 연결이 끊기지 않고 연결을 유지하고 있기 때문에 스프링의 다른 쓰레드들이 해당 연결을 쓰지 못하게 될것이다.
극단적인 예시로는 스프링에서 1개의 connection pool만 유지하고 있을 때, 해당 연결이 특정 상황에서 비정상적으로 연결이 오래 된다면, 다른 쓰레드들은 DB로직을 처리하지 못하고 쓰레드 레벨에서 타임아웃에 걸려 클라이언트에게 서버에러를 응답할것이다.
즉 MySQL에서는 Connection Pool을 갖는 것이 아니다. 절대 오해하면 안된다. MySQL에서는 모든 클라이언트의 최대 연결 수의 합만 제한하는 것이고, connection pool size는 클라이언트쪽에서 설정해줘야한다.
※여기서 말하는 클라이언트는 프론트엔드쪽이 아닌 서버에 요청을 보내는 백엔드서버쪽임을 주의하자
Spring Boot (hikariCP)
minimumIdle
connection pool에서 유휴 연결로 유지할 최소한의 값을 말한다.
tomcat의 쓰레드 설정에서 min-spare를 설정해주면 유지하는 최소 쓰레드와는 약간 다른점이 있다. 톰캣의 쓰레드는 최소쓰레드 이상의 요청이 와야지만 새롭게 쓰레드를 생성하지만, Connection Pool에서 최소 유휴자원은 새롭게 요청이 오면 계속해서 이 설정값을 유지하려 한다.
예를 들면 maximumPoolSize = 10, minimumIdle = 3이라면, 한개의 DB 연결 요청이 올 때
연결을 총 4개 만들어 1개는 연결을 활성해 사용하고, 3개는 유휴 연결로 둔다. DB 연결 요청이 여기서 세건 더 온다면 연결을 3개 더 만들어 4개의 활성 연결, 3개의 유휴연결을 남긴다.
maximumPoolSize
위에서 maximumPoolSize를 언급했는데, 이는 말 그대로 백엔드 서버에서 유지할 max connection pool size이다. 이 설정값은 정말 직관적이니 더 설명을 필요 없을듯 하다.
하지만
minimumIdle과 maximumPoolSize는 충돌되는 요소가 있다. 앞선 예시에서 연결이 8건이 필요하다면 활성 연결이 8건, 유휴 연결이 3건이 필요할 것이다. 이는 maximum으로 설정한 10건보다 연결이 커지는 것인데, 이런 판정에서는 당연히 maximumPoolSize가 우선된다. 총 8건의 연결이 발생한다면 8건의 활성연결, 2건의 유휴연결이 남아 max값인 10건의 connection pool을 넘길 수 없다.
일반적으로 minimumIdle과 maximumPoolSize는 같은 값으로 두는 것을 권장한다고 한다. 즉 maximumPoolSize만큼 항상 연결을 유지시켜놓고 필요할 때 꺼내쓴다는 것이다.
이렇게 하는 이유는 트래픽이 갑자기 몰리는 경우 연결에 큰 비용을 쓸 수도 있기 때문이라고 한다.
그럼 연결을 계속 유지해야한다는 건 ? 네트워크나 CPU, 메모리적인 소모가 있다는 것이기 때문에 maximumPoolSize를 서버의 환경에 맞게 적절히 구성해주는 것이 중요하다.
서버에서 운영중인 tomcat 쓰레드 수와, 메서드를 처리할 때 필요한 connection의 수를 잘 판단해 적절히 조절해야 할 것이다.
connectionTimeout
쓰레드가 200개고, CP를 10개로 설정해놨다면, 동시에 200건의 요청이 들어올 때 190개의 쓰레드는 DB 연결을 점유하기 위해 대기하는 시간이 필요할 것이다.
이 때 대기하는 시간이 connectionTimeout보다 길어지면 연결을 점유하지 못하고 에러를 터뜨리고 만다. 너무 길 경우 클라이언트에게 해주는 응답에 시간이 무한정 길어질 수도 있을것이고, 너무 짧을 경우 연결을 획득하지 못한 에러가 터지는 경우가 많을 것이니 적절히 조절하는 것이 중요하다.
설정방법은 알았으니 어떻게 설정하는게 좋나?
정답은 바로 "없다"이다. 서버마다 환경이 제각각이기 때문에 정해진 정답은 없으나, 권장하는 답은 있다.
먼저 부하테스트를 진행해보는 것이 좋다. 부하테스트를 진행하다가 특정 요청횟수 이상에서 병목이 발생해 응답시간이 길어질텐데, 해당 병목이 톰캣의 쓰레드에 문제가 있는건지, DB 연결에 문제가 있는건지 값을 적절히 조정해가며 직접 맞춰가는 것이다.
만약 서버가 분산돼있다면 분산된 서버별로 스펙에 맞춰 잘 조절해야할 것이다. 아주 어려운 문제라고 할 수 있다.
마치며
현재 진행중인 프로젝트에서 기본값으로 설정해서 쓰다가, 적절히 값을 튜닝해주니 서버 성능이 확 뛰었다. 하지만 결국 일정 횟수 이상 요청을 보내니 서버 자체의 CPU 한계로 더 늘리는 건 실패했지만, 아주 간단한 설정만으로 서버 성능을 크게 개선시킬 수 있다면, 안해볼 이유가 없지 않겠는가.
설정은 딸깍딸깍 몇번이면 되지만, 각각이 갖는 의미를 잘 알아야 잘 설정할 수 있을테니 정리해보는 시간을 가져도 좋을것같다.
Source
주로 참조 - [Youtube] DBCP (DB connection pool)의 개념부터 설정 방법까지!
HTTP 통신과 TCP 통신의 차이와 이해
[SpringBoot] HikariCP를 알아보자!
