[level 2] 재구매가 일어난 상품과 회원 리스트 구하기
구분
코딩테스트 연습 > SELECT
제출 일자
2025년 01월 21일 19:18:30
문제 설명
다음은 어느 의류 쇼핑몰의 온라인 상품 판매 정보를 담은 ONLINE_SALE 테이블 입니다. ONLINE_SALE 테이블은 아래와 같은 구조로 되어있으며 ONLINE_SALE_ID, USER_ID, PRODUCT_ID, SALES_AMOUNT, SALES_DATE는 각각 온라인 상품 판매 ID, 회원 ID, 상품 ID, 판매량, 판매일을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ONLINE_SALE_ID | INTEGER | FALSE |
| USER_ID | INTEGER | FALSE |
| PRODUCT_ID | INTEGER | FALSE |
| SALES_AMOUNT | INTEGER | FALSE |
| SALES_DATE | DATE | FALSE |
동일한 날짜, 회원 ID, 상품 ID 조합에 대해서는 하나의 판매 데이터만 존재합니다.
문제
ONLINE_SALE 테이블에서 동일한 회원이 동일한 상품을 재구매한 데이터를 구하여, 재구매한 회원 ID와 재구매한 상품 ID를 출력하는 SQL문을 작성해주세요. 결과는 회원 ID를 기준으로 오름차순 정렬해주시고 회원 ID가 같다면 상품 ID를 기준으로 내림차순 정렬해주세요.
예시
예를 들어 ONLINE_SALE 테이블이 다음과 같다면
| ONLINE_SALE_ID | USER_ID | PRODUCT_ID | SALES_AMOUNT | SALES_DATE |
|---|---|---|---|---|
| 1 | 1 | 3 | 2 | 2022-02-25 |
| 2 | 1 | 4 | 1 | 2022-03-01 |
| 4 | 2 | 4 | 2 | 2022-03-12 |
| 3 | 1 | 3 | 3 | 2022-03-31 |
| 5 | 3 | 5 | 1 | 2022-04-03 |
| 6 | 2 | 4 | 1 | 2022-04-06 |
| 2 | 1 | 4 | 2 | 2022-05-11 |
USER_ID 가 1인 유저가 PRODUCT_ID 가 3, 4인 상품들을 재구매하고, USER_ID 가 2인 유저가 PRODUCT_ID 가 4인 상품을 재구매 하였으므로, 다음과 같이 결과가 나와야합니다.
| USER_ID | PRODUCT_ID |
|---|---|
| 1 | 4 |
| 1 | 3 |
| 2 | 4 |
풀이
- 문제에서 찾으라 하는 대상은 동일한 회원이 동일한 상품을 재구매한 데이터
- 그래서 테이블 속에서 (user_id-product-id)의 (key-value)쌍을 그룹핑하되, sales_date는 unique한 값이어야 하겠구나!
이러한 생각으로 썼던 GROUP BY - HAVING 쿼리.
처음 코드
SELECT
USER_ID,
PRODUCT_ID
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
HAVING COUNT(UNIQUE SALES_DATE) > 1
ORDER BY
USER_ID ASC,
PRODUCT_ID DESC- 해당 코드 실행 시 에러발생.
- 에러코드 참조.
SQL 실행 중 오류가 발생하였습니다.
You have an error in your SQL syntax;
check the manual that corresponds to your MySQL server version
for the right syntax to use near 'UNIQUE SALES_DATE) > 1
ORDER BY
USER_ID ASC,
PRODUCT_ID DESC' at line 6- 뭔가 문법이 잘못되었다는, Syntax 에러코드였고
UNIQUE SALES_DATE) > 1
ORDER BY
USER_ID ASC,
PRODUCT_ID DESCat line 6, 위 코드 근처에서 사용할 올바른 구문을 쓰라고..
아무래도 unique탓이었던듯
수정 코드
SELECT
USER_ID,
PRODUCT_ID
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
HAVING COUNT(DISTINCT SALES_DATE) > 1
ORDER BY
USER_ID ASC,
PRODUCT_ID DESC;- 해결방법 :
UNIQUE -> DISTINCT
노트
DISTINCT vs UNIQUE
대체 무슨 차이길래?
-
DISTINCT
:SELECT절에 사용
SELECT시 출력되는 row들의 중복값을 제거한 나머지를 출력 -
UNIQUE
:CREATE TABLE시 사용
테이블 내 unique가 적용된 특정 컬럼의 중복값들이INSERT되지 않도록 설정
unique가 설정된 컬럼에서 중복된 값이 들어갈 경우ERROR(값의 유일성)
이렇게 정리했지만..
나는 지금 GROUP BY절과 HAVING에서 집계를 하면서 쓰고 있는데?
관행
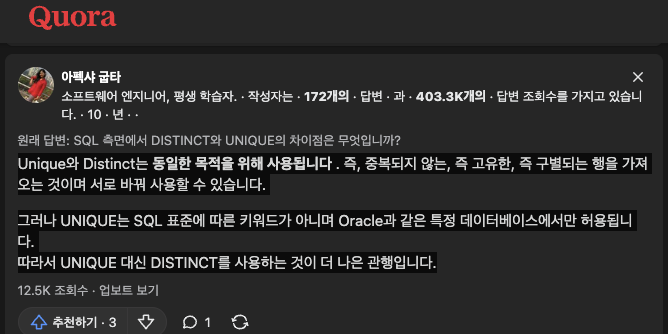
Unique와 Distinct는 동일한 목적을 위해 사용된다.
내가 이해한 바도 동일하다. 그래서 DISTINCT보다 UNIQUE가 먼저 떠오른 거니까.
즉, 중복되지 않는, 즉 고유한, 즉 구별되는 행을 가져오는 것이며 서로 바꿔 사용할 수 있습니다.
여기까지 이해 완료. 바꿔 쓸 수도 있구나, 그럼 내 unique코드는 틀린 게 아니었을지도?
그러나 UNIQUE는 SQL 표준에 따른 키워드가 아니며 Oracle과 같은 특정 데이터베이스에서만 허용됩니다.
여기서 깨달은 점, Syntax오류가 뜬 이유는 이것 때문일 수도 있겠다.
나는 mySQL로 풀고 있었기 때문에 UNIQUE 문법이 오류로 작용했을 수 있겠다는 합리적 추론.
따라서 UNIQUE 대신 DISTINCT를 사용하는 것이 더 나은 관행입니다.
오늘도 배워가는 SQL 문법.
익숙했던 유니꾸 대신 DISTINCT를 다시 기억에 새기는 기회였다.
Reference

TIL 잘쓰시네요 ^^