이번 장에서는 지메일 또는 야후 메일과 같은 대규모 이메일 서비스를 설계해본다.
1단계 문제 이해 및 설계 범위 확정
기능 요구 사항
- 이메일 발송/수신
- 모든 이메일 가져오기
- 읽음 여부에 따른 이메일 필터링
- 제목, 발신인, 메일 내용에 따른 검색 기능
- 스팸 및 바이러스 방지 기능
- HTTP로 메일 서버와 통신
- 첨부 파일도 지원
비기능 요구사항
- 안정성 : 이메일 데이터는 소실되어서는 안된다.
- 가용성 : 이메일과 사용자 데이터를 여러 노드에 자동으로 복제하여 가용성을 보장해야 한다. 아울러 부분적으로 장애가 발생해도 시스템은 계속 동작해야 한다.
- 확장성 : 사용자 수가 늘어나도 감당할 수 있어야 한다. 사용자나 이메일이 많아져도 시스템 성능은 저하되지 않아야 한다.
- 유연성과 확장성 : 새 컴포넌트를 더하여 쉽게 기능을 추가하고 성능을 개선할 수 있는 유연하고 확장성 높은 시스템이어야 한다. POP나 IMAP 같은 기존 이메일 프로토콜은 기능이 매우 제한적이다. 따라서 유연성과 확장성을 갖추려면 맞춤형 프로토콜이 필요할 수도 있다.
개략적인 규모 추정
- 10억 명의 사용자
- 한 사람이 하루에 보내는 평균 이메일 수는 10건이라고 가정한다. 따라서 이메일 전송 QPS=100,000dlek.
- 한 사람이 하루에 수신하는 이메일 수는 평균 40건이라고 가정하고, 이메일 하나의 메타 데이터는 평균 50KB로 가정한다. 메타데이터는 주어진 이메일에 대한 모든 정보이며, 첨부 파일은 포함하지 않는다.
- 메타데이터는 데이터베이스에 저장한다고 가정. 1년간 메타 데이터를 유지하기 위한 스토리지 요구사항은 10억명 사용자 X 하루 40건의 이메일 X 365일 X 20% X 500KB = 1,4560PB에 달한다.
결론적으로, 상당한 양의 데이터를 처리해야 하기 때문에 분산 데이터 베이스 솔루션 이 필요하다 !
2단계 개략적 설계안 제시 및 동의 구하기
이메일 101
이메일을 주고 받는 프로토콜은 여러 가지가 있는데, 대부분의 메일 서버는 POP, IMAP, SMTP 같은 프로토콜을 사용해왔다.
- SMTP
- 이메일을 한 서버에서 다른 서버로 보내는 표준 프로토콜이다.
- POP
- 이메일 클라이언트가 원격 메일 서버에서 이메일을 수신하고 다운로드하기 위해 사용하는 표준 프로토콜이다.
- 단말로 다운로드된 이메일은 서버에서 삭제되기 때문에 결과적으로 한 대 단말에서만 이메일을 읽을 수 있다.
- 해당 프로토콜을 사용하는 클라이언트는 이메일을 일부만 읽을 수 없기 때문에, 용량이 큰 첨부 파일이 붙은 이메일을 읽을려면 시간이 오래 걸린다.
- IMAP
- 이메일 클라이언트가 원격 메일 서버에서 이메일을 수신하는 데 사용되는 또 다른 표준 프로토콜이다.
- POP와는 달리 클릭하지 않으면 메세지는 다운로드 되지 않으며, 메일 서버에서 지워지지도 않는다. 따라서 여러 단말에서 이메일을 읽을 수 있다.
- 개인 이메일 계정에서 가장 널리 이용되는 프로토콜이다.
- HTTPS
- 이 프로토콜은 기술적으로 보자면 메일 전송 프로토콜이 아니다. 하지만 웹 기반 이메일 프로젝트의 메일함 접속에 이용될 수 있다.
도메인 이름 서비스 (DNS)
DNS 서버는 수신자 도메인의 메일 교환기 레코드 (MX) 검색에 이용된다. 가령 커맨드-라인에서 gmail.com의 DNS 레코드를 검색해 보면 다음과 같은 MX 레코드가 표시된다.

우선순위 값은 선호도를 나타내는 것으로, 그 값이 낮을수록 우선순위가 높아서 선호하는 것으로 이해하면 된다. 따라서 위의 사진을 기준으로는, gmail-smtp-in.l.google.com이 우선순위가 가장 높기 때문에 송신자 측 메일 서버는 이 메일 서버에 접속해서 메세지를 보내려고 시도한다. 연결 실패 시, 그 다음으로 우선순위가 높은 메일 서버와 연결을 시도한다.
첨부파일
이메일 첨부 파일은 이메일 메세지와 함께 전송되며, 일반적으로 Base64 인코딩을 사용한다.
전통 메일 서버
분산 메일 서버에 대해 알아보기 전에 기존 메일 서버(보통 서버 한대로 운용)의 역사와 동작 방식을 간단히 살펴보자.
전통적 메일 서버 아키텍쳐
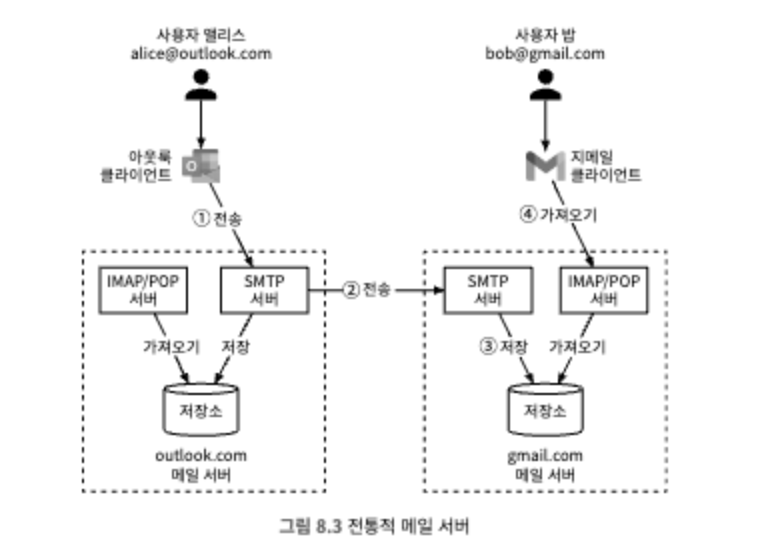
해당 프로세스는 아래 단계로 구성된다.
- 앨리스는 아웃룩 클라이언트에 로그인하여 이메일을 작성하고 '보내기' 버튼을 누른다. 이메일은 아웃룩 메일 서버로 전성되고, 아웃룩 클라이언트와 메일 서버 사이의 통신 프로토콜은 SMTP이다.
- 아웃룻 메일 서버는 DNS 질의를 통해 수신사 SMTP 서버 주소를 찾고 해당 메일 서버로 이메일을 보낸다. 메일 서버 간 통신 프로토콜도 SMTP이다.
- 지메일 서버는 이메일을 저장하고 수신자인 밥이 읽어갈 수 있도록 한다.
- 밥이 지메일에 로그인하면 지메일 클라이언트는 IMAP/POP 서버를 통해 새 이메일을 가져온다.
저장소
전통적 메일 서버는 이메일을 파일 시스템의 디렉터리에 저장했다. 이때 각각의 이메일은 고유한 이름을 가진 별도 파일로 보관한다. 각 사용자의 설정 데이터와 메일함은 사용자 디렉터리에 보관한다.
하지만 이런 구조는 사용자가 많아짐에 따라 수십억 개의 이메일을 검색하고 백업하는 목적으로 활용하기에는 곤란했다. 이메일 양이 많아지고 파일 구조가 복잡해지면 디스크 I/O가 병목이 되곤 했다.
또한 이메일을 서버의 파일 시스템에 저장했으므로 가용성과 안정성 요구 사항도 만족할 수 없었다.
디스크 손상이나 서버 장애가 언제든 발생할 수 있었기 때문에, 더 안정적인 분산 데이터 저장소 계층이 필요했다.
분산 메일 서버
이렇게 등장한 분산 메일 서버는 현대적 사용 패턴을 지원하고 확장성과 안정성 문제를 해결한다. 이번 절에서는 이메일 API, 분산 이메일 서버 아키텍처, 이메일 발송 및 수신 흐름을 살펴 본다.
이메일 API
이메일 API의 의미는 메일 클라이언트마다, 그리고 이메일 생명주기 단계마다 달라질 수 있다.
- 모바일 단말 클라이언트를 위한 SMTP/POP/IMAP API
- 송신 측 메일 서버와 수신 측 메일 서버 간의 SMTP 통식
- 대화형 웹 기반 이메일 애플리케이션을 위한 HTTP 기반 RESTful API
POST /v1/messages 엔드포인트
To, Tc, Bcc 헤더에 명시된 수신자에게 메세지를 전송한다.
GET /v1/folder 엔드포인트
주어진 이메일 계정에 존재하는 모든 폴더를 반환한다.
응답 형식은 아래와 같다.
[{
id: string 고유한 폴더 식별자
name: string 폴더 이름
기본 폴더는 다음 폴더 가운데 하나다.
All, Archive, Drafts, Flagged, Junk, Sent, Trash
user_id: string 계정 소유자 ID
}]GET /v1/folders/{:folder_id}/messages 엔드포인트
주어진 폴더 아래에 있는 메세지들을 전부 반환한다.
GET /v1/messages/{:message_id}
주어진 특정 메세지에 대한 모든 정보를 반환한다. 메세지는 이메일 애플리케이션의 핵심 구성 요소로, 발신자, 수신자, 메세지 제목, 본문, 첨부 파일 등의 정보로 구성된다.
{
user_id: string 계정주의 ID
from: [name: string, email: string] 발신자의 <이름, 이메일> 쌍
to : [name: string, email: string] 수신자 <이름, 이메일> 쌍의 목록
subject: string 이메일 제목
body: string 이메일 본문
is_read: Boolean 수신자가 메세지를 읽었는지 여부
}분산 메일 서버 아키텍처
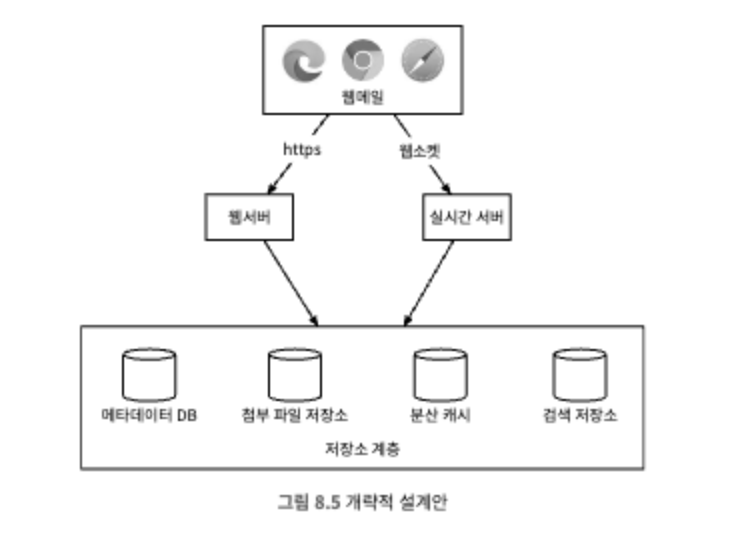
- 웹메일 : 사용자는 웹브라우저를 사용해 메일을 받고 보낸다.
- 웹서버 : 웹서버는 사용자가 이용하는 요청/응답 서비스로, 로그인, 가입, 사용자 프로파일 등에 대한 관리 기능을 담당한다. 본 설계안의 경우 이메일 발송, 폴더 목록 확인, 폴더 내 모든 메세지 확인 등의 모든 이메일 API 요청은 전부 웹서버를 통한다.
- 실시간 서버 : 실시간 서버는 새로운 이메일 내역을 클라이언트에 실시간으로 전달하는 역할을 한다. 실시간 서버는 지속성 연결을 맺고 유지해야 하므로 상태 유지 서버다. 실시간 통신 지원 방안으로는 롱 풀링, 웹소켓 등이 있다.
- 메타데이터 데이터베이스 : 이메일 제목, 본문, 발신인, 수신인 목록 등의 메타 데이터를 저장하는 데이터베이스이다.
- 첨부 파일 저장소 : 아마존 S3 같은 객체 저장소를 사용할 것이다. 카산드라 같은 컬럼 기반 NoSQL 데이터베이스는 이 용도로는 적당하지 않을 것 같다.
- 카산드라가 BLOB 자료형을 지원하고 해당 자료형이 지원하는 데이터의 최대 크기가 2GB이긴 하지만 실질적으로는 1MB 이상의 파일을 지원 못함
- 카산드라에 첨부 파일을 저장하면 레코드 캐시를 사용하기 어렵다. 첨부 파일이 너무 많은 메모리를 잡아먹을 것이다.
- 분산 캐시 : 최근에 수신된 이메일은 자주 읽을 가능성이 높으므로 클라이언트로 하여금 메모리에 캐시해 두도록 하면 메일을 표시하는 시간을 많이 줄일 수 있다. 리스트 같은 다양한 기능을 제공하는 데다 규모 확장도 용이하므로 본 설계안에서는 레디스를 활용한다.
- 검색 저장소 : 검색 저장소는 분산 문서 저장소다. 고속 텍스트 검색을 지원하는 역 인덱스를 자료 구조로 사용한다.
분산 메일 서버에서 가장 중요한 작업 흐름은 아래와 같다.
1) 이메일 전송 절차
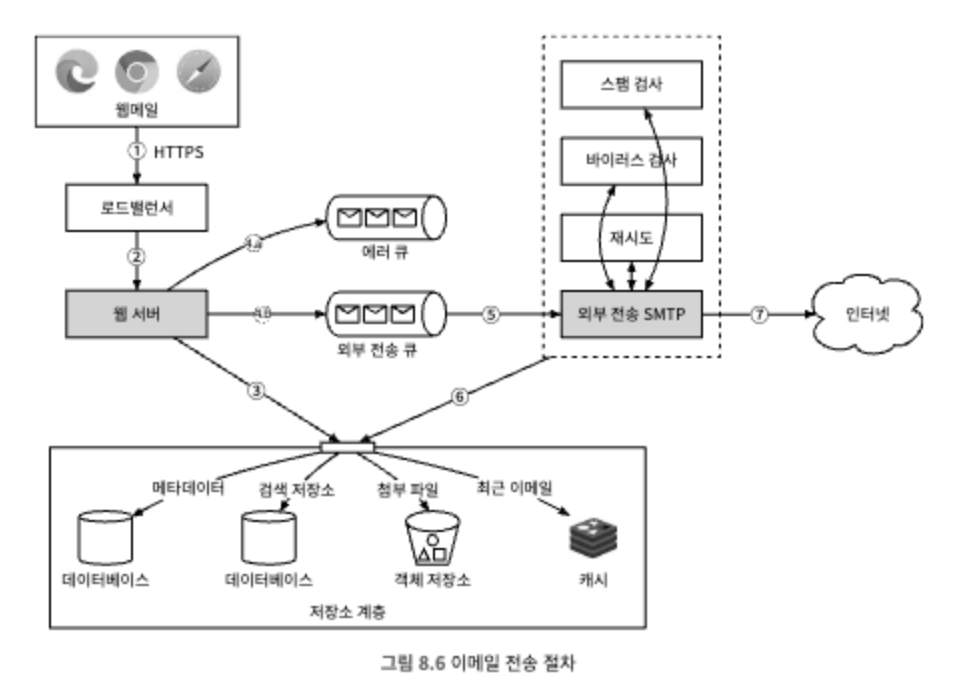
- 사용자가 웹메일 환경에서 메일을 작성한 다음 전송 버튼을 누른다. 요청은 로드밸런서로 전송된다.
- 로드밸런서는 처리율 제한 한도를 넘지 않는 선에서 요청을 웹서버로 전달한다.
- 웹 서버는 다음 역할을 담당한다.
- 기본적인 이메일 검증 : 이메일 크기 한도처럼 사전에 미리 정의된 규칙을 사용하여 수신된 이메일을 검사한다.
- 수신자 이메일 주소 도메인이 송신자 이메일 주소 도메인과 같은지 검사 : 같다면 웹 서버는 이메일 내용의 스팸 여부와 바이러스 감염 여부를 검사한다. 검사를 문제없이 통과한 이메일은 송신인의 '보낸 편지함'과 수신인의 '받은 편지함'에 저장된다. 수신인 측 클라이언트는 RESTful API 를 사용하여 이메일을 바로 가져올 수 있으며, 4단계 이후 수행할 필요는 없다.
- 메세지 큐
a. 기본적인 검증을 통과한 이메일은 외부 전송 큐로 전달된다. 큐에 넣기에 첨부 파일이 너무 큰 이메일은 객체 저장소에 첨부파일을 따로 저장하고 큐에 전달하는 이메일 안에는 해당 저장 위치에 대한 참조 정보만 보관한다.
b. 기본적인 검증에 실패한 이메일은 에러 큐에 보관한다. - 외부 전송 담당 SMTP 작업 프로세스는 외부 전송 큐에서 메세지를 꺼내어 이메일의 스팸 및 바이러스 감염 여부를 확인한다.
- 검증 절차를 통과한 이메일은 저장소 계층 내의 '보낸 편지함'에 저장된다.
- 외부 전송 담당 SMTP 작업 프로세스가 수신자의 메일 서버로 메일을 전송한다.
분산 메세지 큐는 비동기적 메일 처리를 가능하게 하는 핵심 컴포넌트이고 웹서버에서 외부 전송 담당 SMTP 프로세스를 분리함으로써 전송용 SMTP 프로세스의 규모를 독립적으로 조정할 수 있게 한다.
외부 전송 큐의 크기를 모니터링할 때는 각별히 주의해야 하는데, 만일 메일이 처리되지 않고 큐에 오랫동안 머물러있다면 다음과 같은 문제가 있을 수 있다.
- 수신자 측 메일 서버에 장애 발생: 나중에 메일을 다시 전송해야 한다. 지수적 백오프가 좋은 전략일 수 있다.
- 이메일을 보낼 큐의 소비자 수가 불충분 : 더 많은 소비자를 추가하여 처리 시간을 단축하는 방법을 생각해볼 수 있다.
이메일 수신 절차
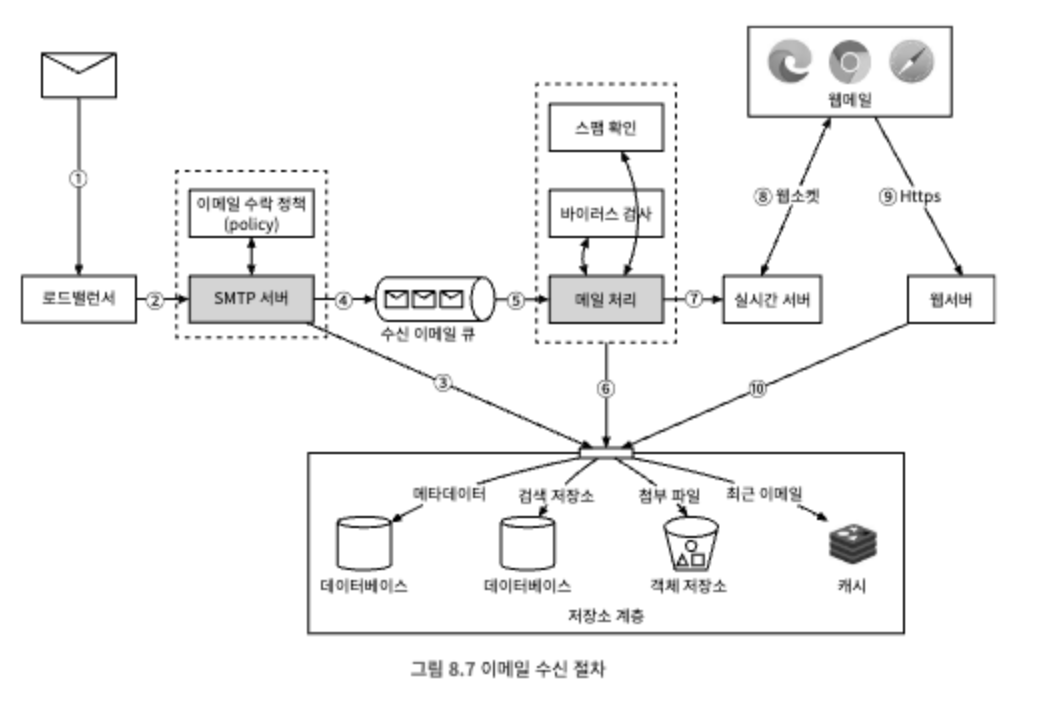
1. 이메일이 SMTP 로드밸런서에 도착한다.
2. 로드밸런서는 트래픽을 여러 SMTP 서버로 분산한다. SMTP 연결에는 이메일 수락 정책을 구성하여 적용할 수 있다. 예를 들어 유효하지 않은 이메일은 반송하도록 하면 불필요한 이메일 처리를 피할 수 있다.
3. 이메일의 첨부 파일이 큐에 들어가기 너무 큰 경우에는 첨부 파일 저장소(S3)에 보관한다.
4. 이메일을 수신 이메일 큐에 넣는다. 이 큐는 메일 처리 작업 프로세스와 SMTP 서버 간의 결합도를 낮추어 각자 독립적으로 규모 확장이 가능하도록 한다. 갑자기 수신되는 이메일의 양이 폭증하는 경우 버퍼 역할도 한다.
5. 메일 처리 작업 프로세스(worker)는 스팸 메일을 걸러내고 바이러스를 차단하는 등의 다양한 역할을 한다. 아래의 절차들은 검증 작업이 끝난 이메일을 대상으로 한다.
6. 이메일을 메일 저장소, 캐시, 객체 저장소 등에 보관한다.
7. 수신자가 온라인 상태인 경우 이메일을 실시간 서버로 전달한다.
8. 실시간 서버는 수신자 클라이언트가 새 이메일을 실시간으로 받을 수 있도록 하는 웹소켓 서버다.
9. 오프라인 상태 사용자의 이메일은 저장소 계층에 보관한다. 해당 사용자가 온라인 상태가 되면 웹메일 클라이언트는 웹 서버에 RESTful AP를 통해 연결한다.
10. 웹 서버는 새로운 이메일을 저장소 계층에서 가져와 클라이언트에 반환한다.
3단계 상세 설계
몇 가지 핵심 요소를 더 자세히 알아보자.
메타데이터 데이터베이스
이메일 메타데이터의 특성을 알아보고 올바른 데이터베이스와 데이터 모델을 고르는 문제, 그리고 이메일 타래 지원 방안에 대해 알아보자.
- 이메일 헤더는 일반적으로 작고, 빈번하게 이용된다.
- 이메일 본문의 크기는 작은 것부터 큰 것까지 다양하지만 사용 빈도는 낮다. 일반적으로 사용자는 이메일을 한 번만 읽는다.
- 이메일 가져오기, 읽은 메일로 표시, 검색 등의 이메일 관련 작업은 사용자별로 격리 수행되어야 한다. 즉, 어떤 사용자의 이메일은 해당 사용자만 읽을 수 있어야 하고, 그 이메일에 대한 작업도 그 사용자만이 수행할 수 있어야 한다.
- 데이터의 신선도는 데이터 사용 패턴에 영향을 미친다. 사용자는 보통 최근 메일만 읽는다. 만들어진 지 16일 이하 데이터에 발생하는 읽기 질의 비율은 전체 질의의 82%에 달한다.
- 데이터의 높은 안정성이 보장되어야 한다. 데이터 손실은 용납되지 않는다.
올바른 데이터베이스의 선정
가능한 모든 선택지는 아래와 같다.
- 관계형 데이터베이스
- 관계형 데이터베이스를 고르는 주된 동기는 이메일을 효율적으로 검색이 가능하기 때문이다.
- 이메일 헤더와 본문에 대한 인덱스를 만들어두면 간단한 검색 질의 빠르게 처리 가능하다. - 하지만 관계형 데이터베이스는 데이터 크기가 작을 때 적합하기 때문에 바람직하지 않다.
- 분산 객체 저장소
- 이메일의 원시 데이터를 그대로 아마존 S3 같은 객체 저장소에 보관하는 것이다. 객체 저장소는 백업 데이터를 보관하기에는 좋지만 이메일의 읽음 표시, 키워드 검색, 이메일 타래 등의 기능을 구현하기에는 그다지 좋지 않다.
- NoSQL 데이터베이스
- 지메일은 구글 빅테이블을 저장소로 사용한다. 따라서 충분히 실현 가능한 방안이다.
- 하지만 빅테이블은 오픈소스로 공개되어 있지 않기 때문에 어떻게 구현이 내부적으로 되어있는지는 모른다.
- 카산드라가 좋은 대안이 될 수도 있지만 대형 이메일 서비스 제공 업체 가운데 카산드라를 쓰는 곳은 없다.
그냥 결론적으로는 본 설계안이 필요로 하는 기능을 완벽히 지원하는 데이터베이스는 없다. 대형 이메일 서비스 업체는 보통 자체적으로 데이터베이스 시스템을 만들어서 사용한다.
데이터 모델
데이터를 저장하는 한가지 방법은 user_id를 파티션 키로 사용하여 특정한 사용자의 데이터는 항상 같은 샤드에 보관하는 것이다. 이 데이터 모델의 한 가지 문제는 메세지를 여러 사용자와 공유할 수 없다는 것이다. 하지만 이는 요구사항과 관계 없으므로 신경 쓰지 않아도 된다.
그럼 이제 테이블을 정의해보자. 기본 키는 파티션 키와 클러스터 키의 두 가지 부분으로 구성된다.
- 파티션 키 : 데이터를 여러 노드에 분산하는 구실을 한다. 일반적으로 통용 되는 규칙은 데이터가 모든 노드에 균등하게 분산되도록 하는 파티션 키를 골라야 한다는 것이다.
- 클러스터 키 : 같은 파티션에 속한 데이터를 정렬하는 구실을 한다.
이메일 서비스의 데이터 계층은 다음과 같은 질의를 지원해야 한다.
- 주어진 사용자의 모든 폴더를 구한다.
- 특정 폴더 내의 모든 이메일을 표시한다.
- 메일을 새로 만들거나, 삭제하거나, 가져온다.
- 이미 읽은 메일 전부, 또는 아직 읽지 않은 메일 전부를 가져온다.
- 보너스 점수를 받을 수 있는 질의 : 이메일 타래를 전부 가져온다.
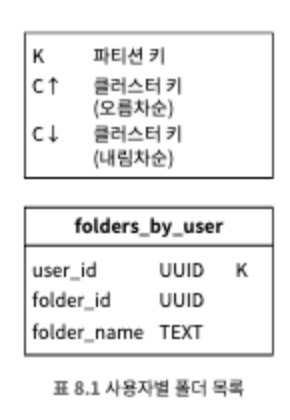
질의 1: 특정 사용자의 모든 폴더 질의
아래에서 볼 수 있듯, 파티션 키는 user_id다. 따라서 어떤 사용자의 모든 폴더는 같은 파티션 안에 있다.
질의 2: 특정 폴더에 속한 모든 이메일 표시
사용자가 자기 메일 폴더를 열면 이메일은 가장 최근 이메일부터 오래된 것 순서로 정렬되어 표시된다. 같은 폴더에 속한 모든 이메일이 같은 파티션에 속하도록 하려면 <user_id, folder_id> 형태의 복합 파티션 키를 사용해야 한다.
email_id의 xkdlqdms TIMEUUID로 이메일을 시간순으로 정렬하는데 사용하는 클러스터 키이다.
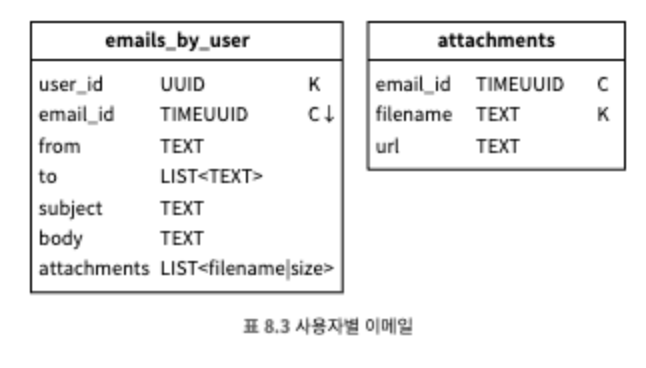
질의 3: 이메일 생성/삭제/수신
이 질의를 지원하기 위해서는 두 테이블이 필요하다. 다음과 같은 간단한 질의를 통해 특정 이메일의 상세 정보를 가져올 수 있다.
SELECT * FROM emails_by_user WHERE email_id = 123;
한 이메일에는 여러 첨부 파일이 있을 수 있다. email_id와 filename 필드를 같이 사용하면 모든 첨부 파일을 질의할 수 있다.
질의 4: 읽은, 또는 읽지 않은 모든 메일
관계형 데이터베이스로 도메인 모델을 구현하는 경우, 읽은 메일 전부는 다음과 같이 질의 가능하다.
SELECT * FROM emails_by_folder
WHERE user_id = <user_id> and folder_id = <folder_id> and is_read = true
ORDER BY email_id읽지 않은 메일을 전부 가져오는 것도 비슷하다.
하지만 본 설계안의 데이터 모델은 NoSQL이다. NoSQL 데이터베이스는 보통 파티션 키와 클러스터 키에 대한 질의만 허용한다. emails_by_folder 테이블의 is_read 필드는 이에 해당하지 않으므로, 대부분의 NoSQL 데이터베이스는 위의 질의문을 실행하지 못한다.
이 문제를 해결하는 방법은 주어진 폴더에 속한 모든 메세지를 가져온 다음 애플리케이션 단에서 필터링을 수행하는 것이다. 하지만 대규모 서비스에서는 안티 패턴이다.
따라서 이 문제는 NoSQL 데이터베이스 테이블을 비정규화하여 해결하는 것이 보통이다. 즉, emails_by_folder 테이블을 아래처럼 두 테이블로 분할하는 것이다.

- read_emails : 읽은 상태의 모든 이메일을 보관하는 테이블
- unread_emails : 읽지 않은 모든 이메일을 보관하는 테이블
읽지 않은 메일을 읽은 메일로 변경하려면 해당 이메일을 unread_emails 테이블에서 삭제한 다음, read_emails 테이블로 옮기면 된다.
또한 특정 폴더 안에 읽지 않은 모든 메일을 가져오는 질의는 아래와 같이 작성하면 된다.
SELECT * FROM unread_emails
WHERE user_id = <user_id> and folder_id = <folder_id>
ORDER BY email_id일관성 문제
높은 가용성을 달성하기 위해 다중화에 의존하는 분산 데이터베이스는 데이터 일관성과 가용성 사이에서 타협적인 결정을 내릴 수 밖에 없다.
이메일 시스템의 경우에는 데이터의 정확성이 아주 중요하므로, 모든 메일함은 반드시 하나의 주 사본을 통해 서비스된다고 가정해야 한다.
따라서 장애가 발생하면 클라이언트는 다른 사본을 통해 주 사본이 복원될 때까지 동기화/갱신 작업을 완료할 수 없다. 데이터 일관성을 위해 가용성을 희생하는 것이다.
이메일 전송 가능성
메일 서버를 구상하고 이메일을 보내는 것은 쉽지만 특정 사용자의 메일함에 실제로 메일이 전달되도록 하는 것은 어려운 문제다.
이메일 전송 가능성을 높이기 위해서는 다음과 같은 요소들을 고려해야 한다.
- 전용 IP : 이메일을 보낼 때는 전용 IP 주소를 사용한다.
- 범주화 : 범주가 다른 이메일은 다른 IP 주소를 통해 보내라.
- 발신인 평판: 새로운 이메일 서버의 IP 주소는 사용 빈도를 서서히 올리는 것이 좋다.
- 스팸 발송자의 신속한 차단 : 스팸을 뿌리는 사용자는 서버 평판을 심각하게 훼손하기 전에 시스템에서 신속히 차단해야 한다.
- 피드백 처리 : 불만 신고가 접수되는 비율을 낮추고 스팸 계정을 신속히 차단하기 위해서는 ISP 측에서의 피드백을 쉽게 받아 처리할 수 있는 경로를 만드는 것이 중요하다.
검색
기본적인 이메일 검색은 보통 이메일 제목이나 본문에 특정 키워드가 포함되었는지 찾는 것을 뜻한다. 검색 기능을 제공하려면 이메일이 전송, 수신, 삭제될 때마다 색인(인덱싱) 작업을 수행해야 한다.
그에 반해 검색은 사용자가 '검색' 버튼을 누를 때만 실행된다. 따라서 이메일 시스템의 검색 기능에서는 쓰기 연산이 읽기 연산보다 훨씬 많이 발생한다.
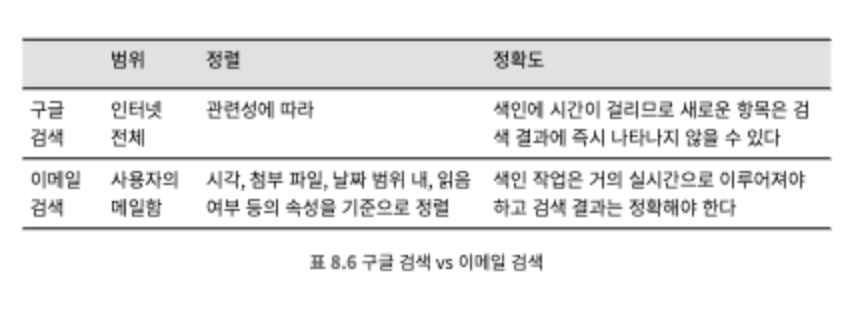
검색 기능을 지원하기 위해서는 엘라스틱서치를 이용하는 방법과 데이터 저장소에 내장된 기본 검색 기능을 활용하는 방안의 두 가지 선택지를 지금부터 비교해보자.
방안 1: 엘라스틱 서치
엘라스틱 서치 기술을 활용해 검색 기능을 구현할 경우 아래와 같은 설계안이 나온다.
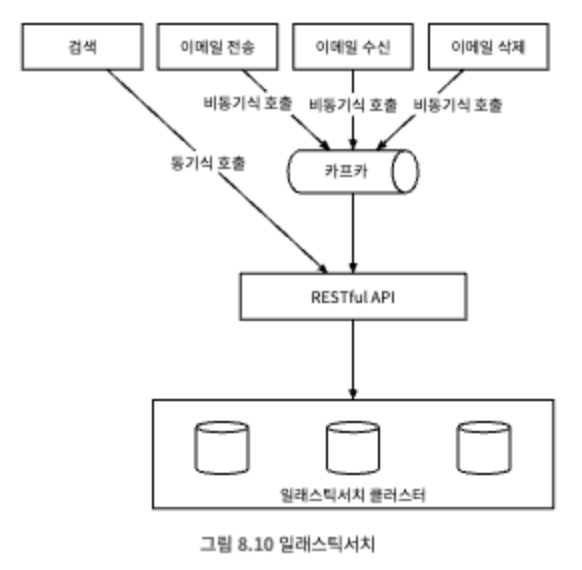
질의가 대부분 사용자의 이메일 서버에서 실행되므로 user_id를 파티션 키로 사용하여 같은 사용자의 이메일은 같은 노드에 묶어 놓는다.
본 설계안은 카프카를 활용하여 색인 작업을 시작하는 서비스와 실제로 색인을 수행할 서비스 사이의 결합도를 낮추는 방안을 채택했다.
엘라스텍 서치를 사용할 경우 한 가지 까다로운 문제는 주 이메일 저장소와 동기화를 맞추는 부분이다.
방안 2: 맞춤형 검색 솔루션
대규모 이메일 서비스 사업자는 보통 자기 제품에 고유한 요구사항을 만족시키기 위해 검색 엔진을 자체적으로 개발해 사용한다. 하지만 이메일 검색 엔진의 설계는 아주 복잡한 과제이기 때문에, 여기서는 자세히 다루지는 않는다.
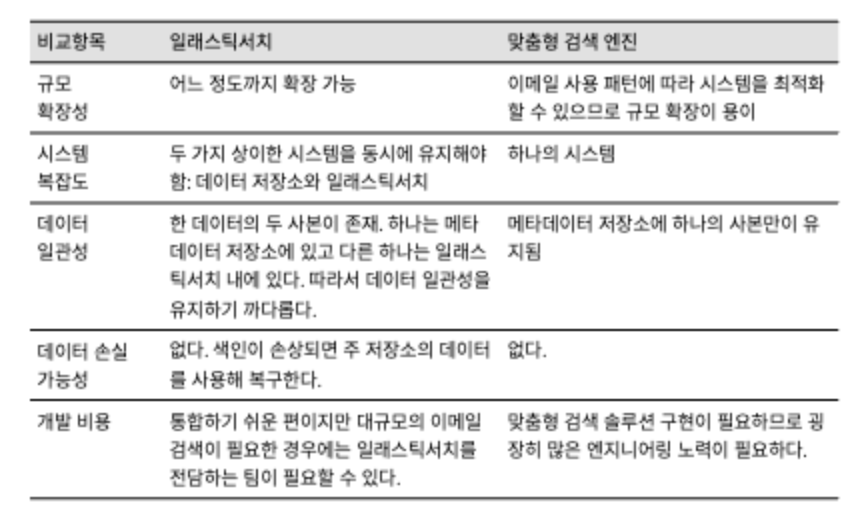
두 가지 방안을 간략하게 비교해본 표는 위와 같다.
소규모의 이메일 시스템을 구축하는 경우에는 엘라스틱 서치가 좋은 선택지다.
통합하기 쉽고 엔지니어링에 많은 노력이 필요하지도 않다. 대규모 시스템을 구축하는 경우에도 일래스틱서치를 사용할 수는 있겠지만 이메일 검색 인프라를 개발하고 관리하는 전담 팀이 필요할 수 있다.
지메일이나 아웃룩 규모의 이메일 시스템을 지원하려면 독립적인 검색 전용 시스템을 두기보다는 데이터 베이스에 내장된 전용 검색 솔루션을 사용하는 것이 바람직할 수도 있다.
규모 확장성 및 가용성
각 사용자의 데이터 접근 패턴은 다른 사용자와 무관하므로, 시스템의 대부분 컴포넌트는 수평적으로 규모 확장이 가능할 것으로 기대할 수 있다.
가용성을 향상시키기 위해서는 데이터를 여러 데이터센터에 다중화하는 것이 필요하다. 사용자는 네트워크 토폴로지 측면에서 보았을 때 자신과 물리적으로 가까운 메일 서버와 통신한다. 장애 때문에 네트워크 파티션(network partition), 즉 통신이 불가능한 네트워크 영역이 생기게 되면 사용자는 다른 데이터센터에 보관된 메시지를 이용한다.
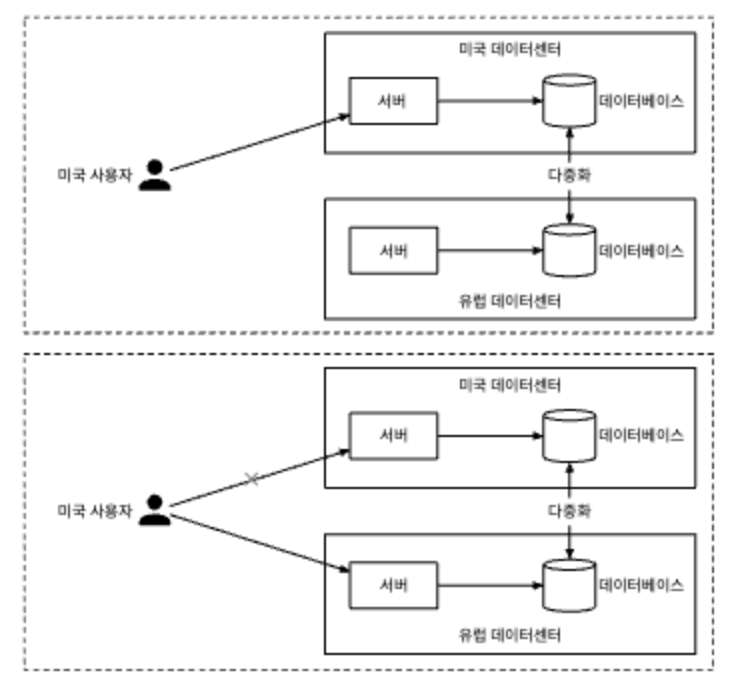
4단계 마무리
면접장에서 시간이 된다면 아래 추가로 논의해볼 만한 주제도 언급하면 좋을 것 같다.
- 결합 내성(fault tolerance): 시스템의 많은 부분에 장애가 발생할 수 있다.
노드 장애, 네트워크 문제, 이벤트 전달 지연 등의 문제에 어떻게 대처할지 살펴보면 좋을 것이다. - 규정 준수(compliance): 이메일 서비스는 전 세계 다양한 시스템과 연동해야 하고 각 나라에는 준수해야 할 법규가 있다. 예를 들어 유럽에서는 GDPR(General Data Protection Regulation) 기준에 따라 개인 식별 정보(Personally Identifiable Information, PII)를 처리하고 저장해야 한다. 합법적 감청(legal intercept)은 이 분야의 또 다른 대표적 특징이다.
- 보안(security): 이메일 보안은 중요하다. 이메일에는 민감한 정보가 포함되기 때문이다. 지메일은 피싱이나 멀웨어 공격을 방지하는 피싱 방지(phish-ing protection), 안전하지 않은 사이트를 경고하는 안전 브라우징(safe browsing), 보안 결함이 있는 첨부 파일에 대한 사전 경고(proactive alert), 의심스러운 로그인 시도를 차단하는 계정 안전(account safety), 송신자가 메시지에 대한 보안 정책을 설정할 수 있도록 하는 기밀 모드(confidential mode), 타인이 이메일 내용을 엿보지 못하도록 하는 이메일 암호화(email encryption) 등의 보안 관련 기능을 제공한다.
- 최적화(optimization): 때로는 같은 이메일이 여러 수신자에게 전송되기 때문에 똑같은 첨부 파일이 그룹 이메일 객체 저장소(S3)에 여러 번 저장되는 경우가 있다. 저장하기 전에 저장소에 이미 동일한 첨부 파일이 있는지 확인하면 저장 연산 실행 비용을 최적화할 수 있다.
