
🔊본 포스팅은 '(이코테 2021) 이것이 취업을 위한 코딩 테스트다 with 파이썬' 유튜브 강의를 수강하고 정리한 글입니다.
1. 알고리즘 성능 평가
복잡도(Complexity)
- 복잡도는 알고리즘의 성능을 나타내는 척도이다.
시간 복잡도: 특정한 크기의 입력에 대하여 알고리즘의 수행 시간 분석
공간 복잡도: 특정한 크기의 입력에 대하여 알고리즘의 메모리 사용량 분석 - 동일한 기능을 수행하는 알고리즘이 있다면, 일반적으로 복잡도가 낮을수록 좋은 알고리즘이다.
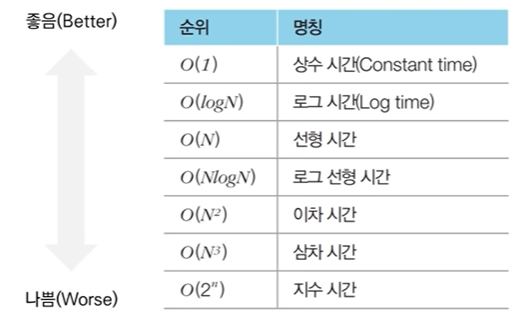
빅오 표기법(Big-O Notation)
- 가장 빠르게 증가하는 항만을 고려하는 표기법이다.
함수의 상한만을 나타나게 된다. - 예를 들어 연산 횟수가 인 알고리즘이 있다.
빅오 표기법에서는 차수가 가장 큰 항만 남기므로 으로 표현된다.
1.시간 복잡도 계산해보기(N개의 데이터의 합을 계산하는 프로그램 예제)
array = [3,5,1,2,4] # 5개의 데이터(N=5)
summary = 0 # 합계를 저장할 변수
# 모든 데이터를 하나씩 확인하며 합계를 계산
for x in array:
summary += x
# 결과를 출력
print(summary)수행 시간은 데이터의 개수 N에 비례할 것임을 예측할 수 있다.
2.시간 복잡도 계산해보기(2중 반복문을 이용하는 프로그램 예제)
array = [3,5,1,2,4] # 5개의 데이터(N=5)
for i in array:
for j in array:
temp = i*j
print(temp)시간복잡도
참고로 모든 2중 반복문의 시간 복잡도가인 것은 아니다.
알고리즘 문제 해결 과정
- 일반적인 알고리즘 문제 해결 과정은 다음과 같다.
1. 지문 읽기 및 컴퓨터적 사고
2. 요구사항(복잡도) 분석
3. 문제 해결을 위한 아이디어 찾기
4. 소스코드 설계 및 코딩수행 시간 측정 소스코드 예제
- 일반적인 알고리즘 문제 해결 과정은 다음과 같다.
import time
start_time = time.time()
# 프로그램 소스코드
end_time = time.time()
print("time:", end_time-start_time) # 수행 시간 출력2. 자료형의 이해
- 파이썬의 자료형으로는 정수형, 실수형, 복소수형, 문자열, 리스트, 튜플, 사전 등이 있다.
정수형(Integer)
- 정수형은 정수를 다루는 자료형이다.
양의 정수, 음의 정수, 0이 포함된다.
a = 1000 # 양의 정수
b = -7 # 음의 정수
c = 0 # 0실수형(Real Number)
- 실수형은 소수점 아래의 데이터를 포함하는 수 자료형이다.
파이썬에서는 변수에 소수점을 붙인 수를 대입하면 실수형 변수로 처리된다.
소수부가 0이거나, 정수부가 0인 소수는 0을 생략하고 작성할 수 있다.
a = 157.93 # 양의 실수
print(a)
b = -1837.2 # 음의 실수
print(b)
c = 5. # 소수부가 0일 때 0을 생략
print(c)
d = -.7 # 정수부가 0일 때 0을 생략
print(d)[실행 결과]
157.93
-1837.2
5.0
-0.7지수 표현 방식
- 파이썬에서는 e나 E를 이용한 지수 표현 방식을 이용할 수 있다.
e나 E 다음에 오는 수는 10의 지수부를 의미한다.
예를 들어 1e9라고 입력하게 되면, 10의 9제곱이 된다.
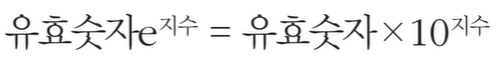
1.지수 표현 방식은 임의의 큰 수를 표현하기 위해 자주 사용된다.
2.최단 경로 알고리즘에서는 도달할 수 없는 노드에 대하여 최단 거리를 무한(INF)로 설정하곤 한다.
3. 리스트 자료형
- 여러 개의 데이터를 연속적으로 담아 처리하기 위해 사용하는 자료형이다.
리스트 대신에 배열 혹은 테이블이라고 부르기도 한다.

리스트 초기화
- 리스트는 대괄호 안에 원소를 넣어 초기화하며, 쉼표(,)로 원소를 구분한다.
- 비어있는 리스트를 선언하고자 할 때는 list() 혹은 간단히 []를 이용할 수 있다.
- 리스트의 원소에 접근할 때는 인덱스(index) 값을 괄호에 넣는다.
인덱스는 0부터 시작한다.
# 직접 데이터를 넣어 초기화
a = [1,2,3,4,5,6,7,8,9]
print(a)
# 네 번째 원소만 출력
print(a[3])
# 크기가 N이고, 모든 값이 0인 1차원 리스트 초기화
n = 10
a = [0]*n
print(a)[실행 결과]
[1,2,3,4,5,6,7,8,9]
4
[0,0,0,0,0,0,0,0,0,0]리스트의 인덱싱과 슬라이싱
- 인덱스 값을 입력하여 리스트의 특정한 원소에 접근하는 것을 인덱싱(Indexing)이라고 한다.
파이썬의 인덱스 값은 양의 정수와 음의 정수를 모두 사용할 수 있다.
음의 정수를 넣으면 원소를 거꾸로 탐색하게 된다.
# 여덟 번째 원소만 출력
a = [1,2,3,4,5,6,7,8,9]
print(a[7])
# 뒤에서 첫 번째 원소 출력
print(a[-1])
# 뒤에서 세 번째 원소 출력
print(a[-3])
# 네 번째 원소 값 변경
a[3] = 7
print(a)[실행 결과]
8
9
7
[1,2,3,7,5,6,7,8,9]- 리스트에서 연속적인 위치를 갖는 원소들을 가져와야 할 때는 슬라이싱(Slicing)을 이용한다.
# 두 번째 원소부터 네 번째 원소까지
a = [1,2,3,4,5,6,7,8,9]
print(a[1:4])[실행 결과]
[2,3,4]리스트 컴프리헨션
- 리스트를 초기화하는 방법 중 하나이다.
대괄호 안에 조건문과 반복문을 적용하여 리스트를 초기화 할 수 있다.
# 0부터 9까지의 수를 포함하는 리스트
array = [i for i in range(10)]
print(array)
# 0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = [i for i in range(20) if i%2==1]
print(array)
# 1부터 9까지의 수들의 제곱 값을 포함하는 리스트
array = [i*i for i in range(1,10)]
print(array)[실행 결과]
[0,1,2,3,4,5,6,7,8,9]
[1,3,5,7,9,11,13,15,17,19]
[1,4,9,16,25,36,49,64,81]- 리스트 컴프리헨션은 2차원 리스트를 초기화할 때 효과적으로 사용될 수 있다.
- 특히 NXM 크기의 2차원 리스트를 한 번에 초기화해야 할 때 매우 유용하다.
좋은 예시: array = [[0]*m for _ in range(n)]
# NXM 크기의 2차원 리스트 초기화
n = 4
m = 3
array = [[0]*m for _ in range(n)]
print(array)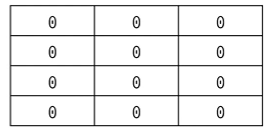
- 만약 2차원 리스트를 초기화할 때 다음과 같이 작성하면 예기치 않은 결과가 나올 수 있다.
잘못된 예시: array = [[0]*m] * n
위 코드는 전체 리스트 안에 포함된 각 리스트가 모두 같은 객체로 인식된다.
# NXM 크기의 2차원 리스트 초기화 (잘못된 방법)
n = 4
m = 3
array = [[0]*m]*n
print(array)
array[1][1] = 5
print(array)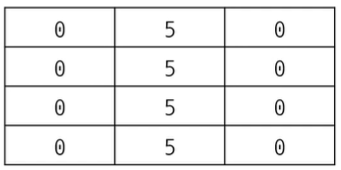
모든 내부적인 리스트가 같은 객체로 인식되는 문제가 발생하여 인덱스 1 위치의 값들이 모두 5로 바뀐다.
리스트 관련 기타 메서드
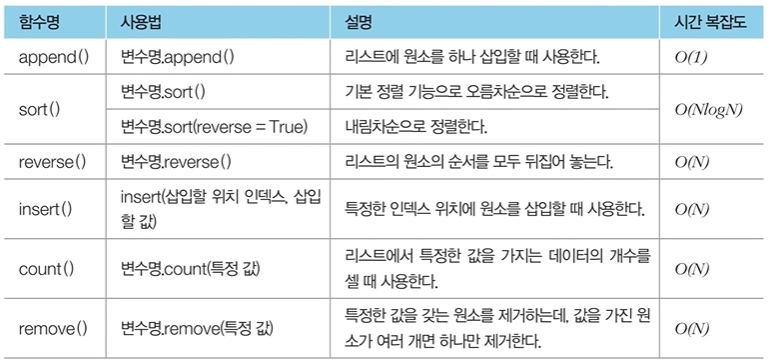
a = [4,3,2,1]
# 리스트 원소 뒤집기
a.reverse()
print("원소 뒤집기: ", a)
# 특정 인덱스에 데이터 추가
a.insert(2,3)
print("인덱스 2에 3 추가: ", a)
# 특정 값인 데이터 개수 세기
print("값이 3인 데이터 개수: ", a.count(3))
# 특정 값 데이터 삭제
a.remove(1)
print("값이 1인 데이터 삭제: ", a)[실행 결과]
원소 뒤집기: [1,2,3,4]
인덱스 2에 3 추가: [1,2,3,3,4]
값이 3인 데이터 개수: 2
값이 1인 데이터 삭제: [2,3,3,4]리스트에서 특정 값을 가지는 원소를 모두 제거하기
a = [1,2,3,4,5,5,5]
remove_set = {3,5}
# remove_list에 포함되지 않은 값만을 저장
result = [i for i in a if i not in remove_set]
print(result)[실행 결과]
[1,2,4]