
Amazon S3 : 스토리지 서비스
| 정의
스토리지 (Storage)
컴퓨터에 데이터를 저장하는 저장소의 역할을 수행하는 부품
호스팅 (hosting)
제공자 등의 사업자가 주로 개인 홈페이지의 서비 기능을 대행
정적 웹 사이트 : 단순한 HTML과 이미지 그리고 자바스크립트와 같은 클라이언트에서 처리하는 스크립트를 포함한 웹 사이트
동적 웹 사이트 : PHP, JSP, ASP, .NET와 같은 서버에서 처리하는 언어가 포함된 사이트
- Amazon S3 (Amazon Simple Storage Service) 는 파일을 저장하는 데 사용되는 스토리지 서비스
- 스마트한 객체 스토리지 서비스 (객체 스토리지는 데이터를 객체 단위로 관리하는 형식)
- 스토리지 서비스 뿐만 아니라 정적 웹 사이트 호스팅도 가능
(EC2 : 서버 프로그램 실행 O <-> S3 : 서버 프로그램 실행 X)
| 활용
Amazon S3가 어떻게 활용되는 지 확인해보자
| 종류 | 설명 |
|---|---|
| 웹 사이트 호스팅 | HTML, CSS, Java Script, 이미지 파일 등 콘텐츠에서 사용 가능 |
| 미디어 콘텐츠 호스팅 | 각종 사진, 배너 이미지, 음악, 영상 등 미디어 콘텐츠를 저장 및 관리 |
| 데이터 백업 및 복원 | 데이터 백업 및 복원을 위한 솔루션 제공 |
| 데이터 저장 및 분석 | 대량의 데이터를 저장하고 분석하는 데에 사용 (머신러닝, 데이터 분석, 비즈니스 인텔리전스) |
| 스토리지 클래스
스토리지의 종류 = 스토리지 클래스
버킷(객체를 저장하는 컨테이너) 단위가 아니고 객체(파일) 단위로 클래스 선택 가능
스토리지 클래스의 종류를 살펴보자.
| 종류 | 설명 |
|---|---|
| S3 Standard | 가장 일반적인 스토리지 클래스 자주 액세스하는 데이터를 위한 스토리지 |
| S3 Intelligent-Tiering (지능형 계층화) |
빈번한 엑세스와 간헐적 엑세스에 최적화된 두 가지 계층에 객체(파일) 저장 알 수 없거나 액세스 패턴이 변경되는 데이터에 대한 자동 비용 절감을 위한 스토리지 |
| S3 Infrequent Access (자주 접근 안 하는) |
자주 액세스하지 않는 데이터를 위한 스토리지 엑세스 빈도가 낮고 용량이 큰 데이터에 적합 |
| Reduced Redundancy Storage (중복 감소 스토리지) |
Standard / Standard-Infrequent Access / Reduced Redundancy Storage |
| S3 Glacier/S3 Glacier Deep Archive (깊은 빙하 보관소) |
몇 시간 만에 검색 가능한 장기간 아카이브 및 디지털 보존을 위한 스토리지 |
| S3 버킷 (S3 Bucket)
Amazon S3의 S3 버킷 (S3 Bucket) = 실제 파일이 보관되는 여러 개의 바구니
버킷은 객체(저장한 파일)를 저장하는 컨테이너 단위
버킷과 객체 키, 버전으로 객체(저장한 파일)를 관리
1. 용어 정리
| 항목 | 설명 |
|---|---|
| 객체 | 저장한 파일(텍스트나 이미지 등) / S3의 엔터티(독립체) 단위 |
| 버킷 | 객체(저장한 파일)를 저장하는 컨테이너 / 모든 객체는 버킷에 저장 |
| 객체 키 | 객체(저장한 파일) 식별자 / 모든 객체는 반드시 한 개의 키를 가짐 / 이름 / 버킷, 객체키, 버전을 조합하여 객체를 고유하게 식별 |
| 버전 관리 | 여러 버전 보관 / 다른 버전은 별도의 객체로 취급 |
2. S3 버킷의 특징
- 버킷은 빈 상태에서 시작
- 버킷에 보관하는 파일의 개수, 크기, 유형의 제한이 없음
- 필요한 사용자에게만 버킷 단위 또는 버킷 내 파일 단위의 접근 권한을 부여
- 파일의 안전성을 보장하는 다양한 보안 및 암호화 기술을 제공
- 버킷에 파일을 저장하거나 꺼낼 때의 비용은 파일의 크기와 저장 기간에 따라 달라짐
- 버킷은 폴더가 아니므로 버킷 안에 버킷을 다시 만드는 것은 불가능
- 접근 제한 설정 가능
(버킷 단위로 제한하는 버킷 정책 / IAM 사용자 단위로 제한하는 사용자 정책 / ACL(엑세스 제어 목록/자신외의 다른 AWS 계정의 접근 제어를 설정한 목록)에 의한 관리 정책)
| 데이터 분석과 연계 : 저장된 데이터의 분석
S3의 객체나 객체의 내용에 대한 데이터를 분석하는 기능이 있다.
S3 Select, Athena, Redshift 종류가 있다.
CSV(comma-separated values)
몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일
| 항목 | 설명 |
|---|---|
| S3 Select | - 단일 데이터 처리 가능 - CSV나 JSON같은 구조화된 텍스트 형식의 데이터에 대해 SQL문을 실행 - CLI(명령줄 기반 환경)나 SDK(소프트웨어 개발 킷)을 지원하며 실행 가능 |
| Amazon Athena | - 대용량 데이터 처리 가능 - CSV나 JSON같은 구조화된 텍스트 형식의 파일에 대해 SQL 문을 실행 - 분석용 서버를 자동으로 실행하여 실행하기 때문에 실행하는 순간만 비용 발생 - 집계나 검색 방법으로 작업 용이 |
| Amazon Redshift Spectrum | - 대용량 데이터 처리 가능 - S3의 데이터에 대해 SQL 문을 실행하는 기능 - 미리 분석용 서버를 시작하고 분석 실행 - 다양한 기준으로 데이터 분석 가능 |
| Amazon CloudFront : 콘텐츠 배포 서비스
CDN(콘텐츠 전송 네트워크)
데이터 사용량이 많은 애플리케이션의 웹 페이지 로드 속도를 높이는 상호 연결된 서버 네트워크
CloudFront는 AWS에서 제공하는 CDN 서비스
캐싱을 통해 사용자에게 좀 더 빠른 전송 속도를 제공하는 것을 목적으로 한다.
전 세계 이곳저곳에 Edge Server(Location)을 두고 사용자에게 가장 가까운 Edge Server를 찾아 빠른 데이터를 제공합니다.
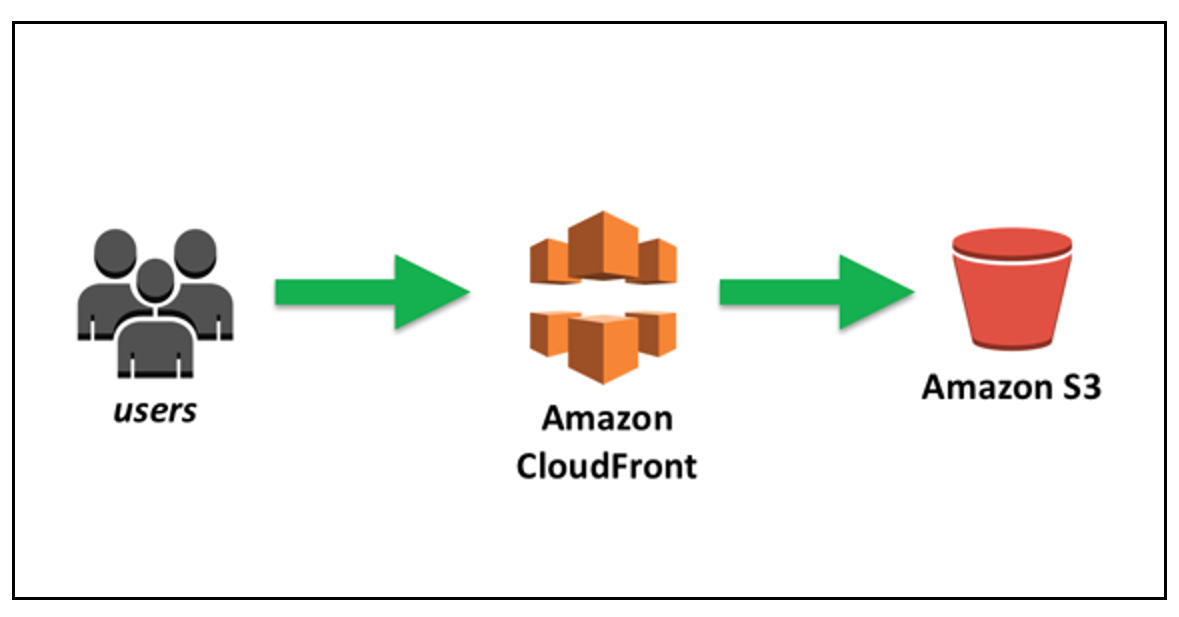
참고
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=274143194
https://velog.io/@doohyunlm/AWS-CloudFront-%EA%B0%9C%EB%85%90
https://velog.io/@rungoat/AWS-S3%EC%99%80-CloudFront-%EC%97%B0%EB%8F%99%ED%95%98%EA%B8%B0
https://blog.devops.dev/effective-strategies-for-writing-one-million-small-objects-to-s3-47496774a048
