동아리에서 토이 플젝을 하는데 기능 중에 쿠팡 크롤링이 있었다.. 이 놈 때문에 프로젝트 진행이 계속 늦어져서 애를 먹었다..
우리는 쿠팡에서 상품명과 대표 사진을 받아 와야하는데 상품명은 정적, 사진 url은 동적으로 로드되어 있을 수 있기 때문에 까다롭다.
정적은 jsoup이용, 동적은 selenium과 playwright를 이용한다.
처음은 jsoup으로 진행
→ 상품명마저 얻어오지 못했다..
playwright도 시도
하지만 Dockerfile 설정이 필요했기에 진행하지 못함..
우리 상황
- cloudtype으로 프로젝트 배포 진행
- 하지만 Dockerfile로 배포하지 않음
그래서 selenium으로 진행!
@Service
public class CoupangScraperService {
public Map<String, String> getProductInfo(String url) {
WebDriverManager.chromedriver().setup();
WebDriver driver = new ChromeDriver();
Map<String, String> productData = new HashMap<>();
try {
driver.get(url);
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(10));
// 상품 제목 가져오기
WebElement titleElement = wait.until(ExpectedConditions.visibilityOfElementLocated(By.cssSelector("h1.prod-buy-header__title")));
String title = titleElement.getText();
productData.put("title", title);
// 상품 이미지 가져오기 (올바른 선택자 사용)
WebElement imageElement = wait.until(ExpectedConditions.visibilityOfElementLocated(By.cssSelector("img.prod-image__detail")));
// 기본 이미지 URL 가져오기
String imageUrl = imageElement.getAttribute("src");
// 만약 `data-zoom-image-url` 속성이 있다면, 더 고해상도 이미지 사용
String highResImageUrl = imageElement.getAttribute("data-zoom-image-url");
if (highResImageUrl != null && !highResImageUrl.isEmpty()) {
imageUrl = highResImageUrl;
}
// `src` 속성이 `//`로 시작하는 경우, `https:` 추가
if (imageUrl.startsWith("//")) {
imageUrl = "https:" + imageUrl;
}
productData.put("image", imageUrl);
} catch (Exception e) {
productData.put("error", e.getMessage());
} finally {
driver.quit();
}
return productData;
}
}
f12 개발자 모드를 보면 cssSelector에 어떤 값을 넣어야 하는지 알 수 있음

로컬 환경에서는 쿠팡 크롤링 성공!
Selenium 개념 정리
selenium > 웹 자동화 도구
selenium은 여러 브라우저를 지원, 하지만 chrome이 가장 안정적이기 때문에 chrome을 사용한다.
코드(selenium) > 드라이버 > 브라우저
:이렇게 실행되기 때문에 실행될 때 브라우저 창이 뜸. 드라이버가 실제 브라우저를 띄워서 사람처럼 동작하기 때문
창을 안 뜨게 하고 싶다면 headless 모드를 사용. 백그라운드에서 브라우저가 동작한다.
배포 후 문제 발생
성공 후 프로젝트 배포를하고 프로젝트 도메인으로 request를 날려봤으나 실패.. 로컬 환경에서만 크롤링이 동작하는 거였음.
Cloudtype에서 Chrome, WebDriver 설치 시도
이후 배포 서버 환경 문제라고 생각해서 cloudtype 터미널을 사용해서 chrome과 webdriver를 설치해 보려고 했음.. (로컬엔 설치되어 있으나 서버에는 chrome이 설치되어 있지 않기 때문에)
Cloudtype의 기본 컨테이너는 권한 제한 + 미니멀 리눅스 베이스라서 일반적인 패키지가 없거나 설치가 막혀 있음.
특히 apt install에서 chrome 관련 패키지가 없다고 뜸
수동으로 .deb(리눅스에서 사용하는 패키지 파일 포맷 ex) google-chrome-stable_current_amd64.deb: 구글 크롬 설치용) 파일 받아 설치하는 것도 의존성 지옥에 부딪힘
결국 직접 설치하는 대신,
Dockerfile을 통해 필요한 라이브러리를 미리 다 깔아두는 환경을 만들기로 함...
Dockerfile로 환경 만들기
cloudtype 도커파일 기반으로 프로젝트 재배포
FROM eclipse-temurin:17-jdk AS build
WORKDIR /app
# 프로젝트 복사
COPY . .
# gradlew 실행 권한 부여
RUN chmod +x ./gradlew
# 의존성 설치 및 빌드
RUN ./gradlew bootJar --no-daemon
# Runtime Stage
FROM ubuntu:22.04
WORKDIR /app
# 필요한 패키지 및 Chrome + Chromedriver 설치
# Chrome + Chromedriver 설치
RUN apt-get update && apt-get install -y \
wget curl unzip gnupg2 ca-certificates \
fonts-liberation libappindicator3-1 libasound2 libatk-bridge2.0-0 libatk1.0-0 libgbm1 \
libnspr4 libnss3 libx11-xcb1 libxcomposite1 libxdamage1 libxrandr2 libxss1 libxtst6 \
lsb-release xdg-utils chromium-browser chromium-driver && \
apt-get clean
# 환경 변수 설정
# Chrome & Chromedriver 실행 권한 부여
RUN chmod +x /usr/bin/chromium-browser && \
chmod +x /usr/bin/chromedriver
# 환경 변수 설정
ENV CHROME_BIN=/usr/bin/chromium-browser
ENV CHROMEDRIVER_PATH=/usr/bin/chromedriver
ENV PATH="${CHROMEDRIVER_PATH}:${PATH}"
# JAR 복사
COPY --from=build /app/build/libs/*.jar ./app.jar
EXPOSE 8080
# 애플리케이션 실행
ENTRYPOINT ["java", "-jar", "app.jar"]- Chrome, Chromedriver는 apt로 설치 완료
- 경로도
/usr/bin/chromium-browser,/usr/bin/chromedriver로 잘 들어감
❌ 하지만 실행은 실패
- Cloudtype은 GUI가 없는 headless 서버 환경
- Chromium 실행 시 sandbox / X11 / 권한 제한으로 인해 브라우저 실행 실패
--headless,--no-sandbox옵션을 줘도 일부 환경에선 계속 에러가 발생했다.
EC2로 크롤링 서버 분리
결국 크롤링만을 위한 ec2 서버를 하나 만들기로 하였다.
- 필요한 패키지나 옵션도 자유롭게 설치 가능
- 크롤링 서버를 EC2에 분리해서, Cloudtype에서는 크롤링 요청만 보내는 구조로 변경 > 메인 프로젝트 환경에서는 크롤링 값을 받아 db에 넣기만 하면 됨. 배포 서버에서 외부 크롤링 서버로 요청 보냄.
ec2 서버 생성 후
ec2 인스턴스에 ssh 접속 준비
git bash 접속해서(리눅스/유닉스 계열 명령어이기 때문에 그냥 cmd로는 접속 안 됨) .pem 키 있는 곳으로 경로 이동
나는 .pem 키가 Downloads 폴더에 있었기 때문에
cd Downloads
ssh -i <pem키이름>.pem ubuntu@<퍼블릭_IP>크롬 버전과 크롬드라이버 버전은 반드시 일치해야 함
- 패키지 업데이트
sudo apt update
sudo apt upgrade -y
sudo apt install -y wget curl unzip gnup lsb-release- 크롬 설치
# Ubuntu 20.04 이하:
sudo apt install -y chromium-browser
# 최신 우분투일 때
sudo snap install chromium
# 설치된 크롬 버전 확인
chromium --version
# 크롬드라이버 다운로드(웹에서 직접 버전에 맞는 드라이버 다운로드 - 크롬과 동일해야 함)
wget https://chromedriver.storage.googleapis.com/122.0.6261.111/chromedriver_linux64.zip
#unzip 명령어 설치
sudo apt install unzip -y
# 압축 해제
unzip chromedriver_linux64.zip
# 위치 이동 및 권한 설정
chmod +x chromedriver-linux64/chromedriver
sudo mv chromedriver-linux64/chromedriver /usr/local/bin/chromedriver
# 확인
chromedriver --version
EC2 크롤링 서버용 SpringBoot 코드
build.gradle
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.mysql:mysql-connector-j'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
// Selenium
implementation 'org.seleniumhq.selenium:selenium-java:4.15.0'
// WebDriver Manager
implementation 'io.github.bonigarcia:webdrivermanager:5.6.3'
}CrawlingController.java
@RestController
@RequiredArgsConstructor
public class CrawlingController {
private final CrawlingService crawlingService;
@PostMapping("/crawl")
public ResponseEntity<Map<String, String>> crawl(@RequestBody Map<String, String> request) {
String url = request.get("url");
Map<String, String> result = crawlingService.fetchWishData(url);
return ResponseEntity.ok(result);
}
}
CrawlingService.java
@Service
public class CrawlingService {
public Map<String, String> fetchWishData(String url) {
Map<String, String> productData = new HashMap<>();
ChromeOptions options = new ChromeOptions();
options.setBinary("/snap/bin/chromium");
// EC2 환경 대응 옵션
options.addArguments("--headless=new");
options.addArguments("--no-sandbox");
options.addArguments("--disable-dev-shm-usage");
options.addArguments("--disable-gpu");
options.addArguments("--remote-debugging-port=9222");
options.addArguments("--disable-software-rasterizer");
options.addArguments("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64)");
WebDriver driver = null;
try {
driver = new ChromeDriver(options);
driver.get(url);
WebElement titleElement = driver.findElement(By.cssSelector("h1.prod-buy-header__title"));
WebElement imageElement = driver.findElement(By.cssSelector("img.prod-image__detail"));
String title = titleElement.getText();
String imageUrl = imageElement.getAttribute("src");
String highResImage = imageElement.getAttribute("data-zoom-image-url");
if (highResImage != null && !highResImage.isEmpty()) {
imageUrl = highResImage;
}
if (imageUrl != null && imageUrl.startsWith("//")) {
imageUrl = "https:" + imageUrl;
}
productData.put("title", title);
productData.put("image", imageUrl);
} catch (Exception e) {
// 크롤링 실패 시 null로 반환 (에러 포함)
productData.put("title", null);
productData.put("image", null);
productData.put("error", e.getMessage());
} finally {
if (driver != null) {
driver.quit();
}
}
return productData;
}
}
application.properties
spring.application.name=crawling-server
server.port=8080
spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
#db 없이 실행을 위해 설정
실행 방법
gradle > Tasks > build setup > wrapper 설치
gradle > tasks > build > bootJar해서 jar파일 업데이트 (코드 바뀔때 마다 업뎃하고 ec2에 올려야 함)
해당 .jar 파일을 ec2로 옮겨야 함 > ec2에서 크롤링용 api를 실행해야 하므로..!!
#java 설치
sudo apt update
sudo apt install openjdk-17-jre-headless
#ec2에 .jar 파일 업로드
scp -i "/pem키 경로/<pem키이름>.pem" "/크롤링 서버용 프로젝트 jar 경로/build/libs/jar이름.jar" ubuntu@<여기에_퍼블릭_IP_주소>:~
#ec2에서 실행
ssh -i "/pem키 경로/<pem키이름>.pem" ubuntu@<여기에_퍼블릭_IP_주소>
#스프링부트 앱 실행
java -jar jar이름.jar
#기본 GUI 라이브러리 설치
sudo apt update
sudo apt install -y fonts-liberation libappindicator3-1 libatk-bridge2.0-0 libnss3 libxss1 libx11-xcb1 libgtk-3-0
메인 스프링부트 코드 갈아끼기
크롤링을 배포 서버에서 하지 않고 ec2 서버로 요청을 보내게
//크롤링 코드
@Value("${crawling.server.url}")
private String crawlingServerUrl;
@Override
public Map<String, String> fetchWishData(String url) {
Map<String, String> requestBody = new HashMap<>();
requestBody.put("url", url);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<Map<String, String>> entity = new HttpEntity<>(requestBody, headers);
try {
ResponseEntity<Map> response = restTemplate.postForEntity(
crawlingServerUrl + "/crawl",
entity,
Map.class
);
Map<String, String> result = response.getBody();
if (result == null
|| result.get("title") == null
|| result.get("image") == null ){
throw new EventHandler(ErrorStatus._CRAWLING_ERROR);
}
return result;
} catch (Exception e) {
throw new EventHandler(ErrorStatus._CRAWLING_ERROR);
}
}# application-local.yml 예시
crawling:
server:
url: http://<EC2_PUBLIC_IP>:8080ec2 서버용 크롤링 코드를 수정할 경우, bootJar를 다시 실행해서 아래와 같게 실행하면 원격 접속 성공
#ec2에 .jar 파일 업로드
scp -i "/pem키 경로/<pem키이름>.pem" "/크롤링 서버용 프로젝트 jar 경로/build/libs/jar이름.jar" ubuntu@<여기에_퍼블릭_IP_주소>:~
#ec2에서 실행
ssh -i "/pem키 경로/<pem키이름>.pem" ubuntu@<여기에_퍼블릭_IP_주소>
#스프링부트 앱 실행
java -jar jar이름.jar최종 성공!
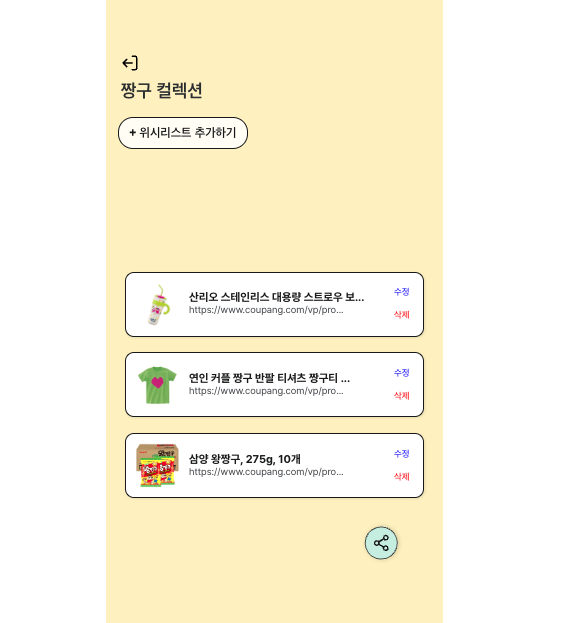
한계
추가로, EC2에서 크롤링을 하다 보니 2시간에 3~4회 요청 후 IP 차단 문제가 발생했다. 해결 방안으로는 User-Agent 랜덤화, 요청 간 딜레이 추가, 프록시 서버 적용, 또는 AWS 인스턴스 재시작을 통한 IP 풀 변경을 고민 중이다.
로컬까지가 한계인 것 같다
