어제한것
메인화면에 이미지대신 동영상 넣기(시연영상) // 이거 클릭시 분석 한눈에보기 게시판이동
화면 랜딩시 (첫진입) 전체블루컬러 , 스크롤시 페이드아웃 컬러사라지게
로그인했을때 문의하기 게시판 보이게하기
네비바를 컴포넌트로 빼니 게시판들이 제일 위가 잘리는 현상 -> 패딩값으로 조절하기
분석사례 하위카테고리에 분석게시판들 드롭다운으로 넣어버리기
오늘 할 것
배송기간말고 다른 요인 찾아보기
머신러닝 & 리액트 코드리뷰
로그인 한 상황일 시 메인 페이지의 무료로 시작하기 버튼 클릭시 문의하기 게시판으로 이동하도록 변경
회원가입 창의 네비바 표시 없애고, 뒤의 그레이 백그라운드 없애기
네비바 문의하기 버튼 컴포넌트에 연결하기
분석사례 눌러도 분석 전체보기로 이동하게 하기
cursor ai 자동적용은 믿을게 못되어서 (그냥 어플라이 올 하면 어떤건 적용안되고 꼬이기 쉽더라) 따로 카피하고 코드 보고 내가 집어 넣는게 편하더라
그리고 퍼플렉시티도 클로드,지피티 다른버전 다 모델변경해서 사용가능하지만 실제 각 모델 사이트에서 런칭하고있는건 최신버전이라 그런지 대답이 조금씩 다르다. 여전히 다 물어봐야할듯. 제미나이, 딥시크 , 클로드 , 챗지피티, 퍼플렉시티 , 커서에이아이, 가끔 vscode copilot 쓰는 정도로 ai 성능 비교중인데 대화형엔 지피티가 제일 낫지만 정보의 정확성은 글쎄. 너무 이모지를 많이 쓰기도 하고.
딥시크가 의외로 설명을 잘한다. (중국어로 질의하면 어떨지 궁금하여서 현재 중국어 공부중이다.)
사용성이 제일 편한건 커서 에이아이고 ( 코드를 알아서 읽으니) 그다음은 퍼플렉시티와 클로드인듯하다. 파일첨부가 매우 간단하니까. 지피티는 입력수 제한 둔게 매우불편해짐. 그래프나 코드 생성은 제미나이가 제일 빠른듯함.
그리고 ai에게 질문할땐 무조건 영어로 질의하는데, 그 이유는 ai가 학습한 데이터셋에 영어 데이터가 압도적으로 많기 때문이고 한국어로 질문하면 영어답을 번역해서 출력하는게 아니라 다이렉트로 한국어로 이해하고 학습한 한국어 데이터 정답을 뱉기때문에
최신 정보나 구체적인 내용을 듣고싶으면 영어로 봐야함. 자료의 양과 설명의 질적 차이가 엄청나니 꼭!! 영어로 질의해야함.
to_timedelta
판다스가 자동으로 넘파이로 계산하니까 구매날짜는 데이트레인지로 만든 데이트타임이고, 뒤에 더한건 타임델타인데 넘파이로 타임델타로 계산됨
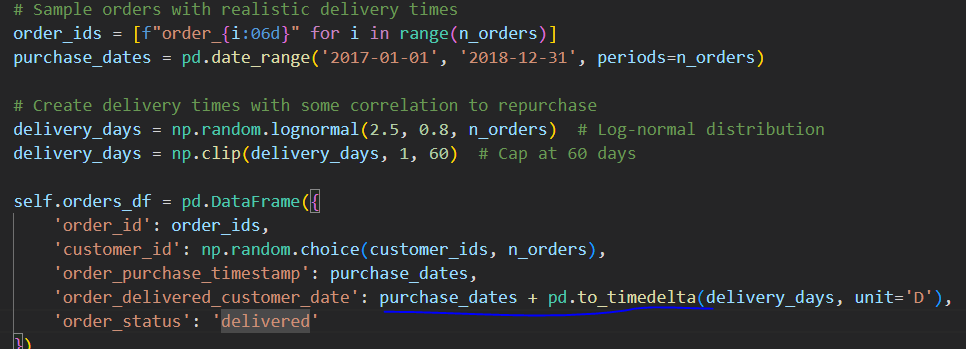
그래서 앞에는 날짜, 뒤에는 기간으로 day기준으로 배송기간을 더해서 배송완료날짜 더미데이터 만듦
to_datetime 이랑 to_timedelta차이
데이트타임은 정확히 몇월몇일몇시 나오게하는거고 타임델타는 2일,3일, 이런식으로 기간을 표현
물론 앞에 데이트타임 더하면 2일 더해진 날짜값이 나오긴함
dropna(subset=columns)은 컬럼에 결측치가 있으면 그 행을 드랍하라는 뜻임. 그냥 칼럼을 드랍하라는게아님.
시리즈.dt.days 는 3일4일 이걸그냥 3,4로 출력하게하는거 타임델타.days.랑 똑같
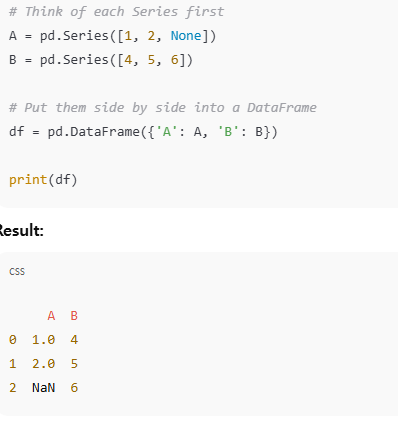
Series = 리스트 하나 , 인덱스랑 리스트 있는거. 걍 로우라서 컬럼존재안함.
s = pd.Series([1, 2, None])
DataFrame = 시리즈 여러개. 컬럼 존재.
df = pd.DataFrame({
'A': [1, 2, None],
'B': [4, 5, 6]
})
데이터 프레임에서 칼럼은 즉 하나의 시리즈임.

So: are columns just rows flipped?
✔️ A column = a vertical Series
✔️ A row = a horizontal snapshot of all columns at that index (horizontal record of values across columns)
So a DataFrame is like:
Rows: index 0, 1, 2, ...
Columns: A, B, C, ...
행 인덱스 그냥 숫자로 하기 싫으면 데이터프레임 만들때 index=[~~]설정하기


.iloc | .loc | |
|---|---|---|
| What it uses | Integer position | Label (index name or column name) |
| Example | Row 0, Row 1, etc. | Row named 'A' or index 2024-01-01 |
이거쓸때 쓰니까 인덱스가 매우중요함. 근데 내가 인덱스지정할때, 라벨링한 인덱스는 복제된게 여러개 있을 수 있어서 loc로 불러올때 여러행이 불러와질수있어서 주의해야함.
.iloc — integer location
.loc — label-based
DataFrame.merge
sql 조인이랑 같음
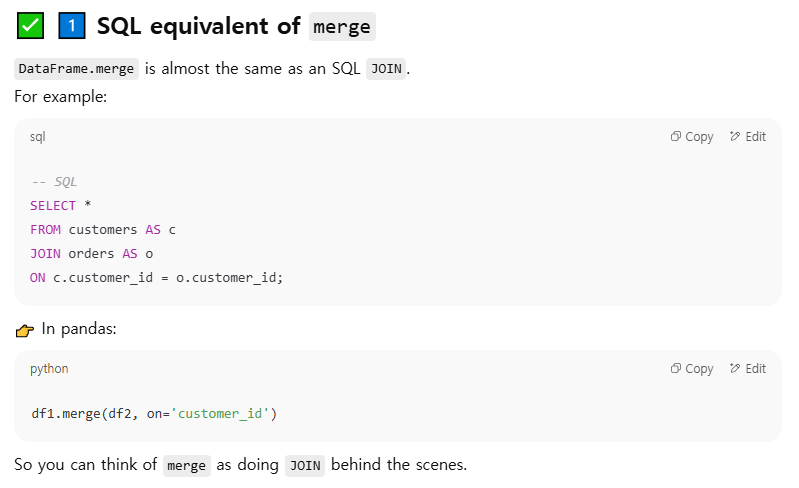
레프트온 라이트온은 다른컬럼네임가진애들로 테이블 붙일때(보통은 같은 이름인 컬럼으로 on해서 붙이니까 on label or list
Column or index level names to join on. These must be found in both DataFrames. )
서브픽스는 같은칼럼이름이라 헷갈리니 이건 왼쪽서 이건 오른쪽서 온거라고 접미사붙이는거
df1.merge(df2, left_on='lkey', right_on='rkey', suffixes=(False, False)) ==> 중복되는 컬럼이름있어도 접미사붙이지말라는건데
판다스는 이걸 허용안하니 익셉션 뜸
inner join
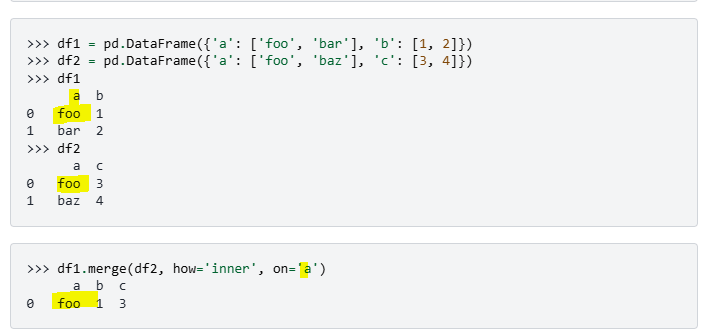
a 컬럼을 두 테이블이 둘다 가지고 있어야하고 그걸 기준으로 조인, 이너조인은 둘다 가진걸 남기는거임.
df1과 df2에 중복되어 있는건 foo 밖에 없으므로 그것만 살아남고
foo가 있는 인덱스가 df1에선 0번인덱스인 b컬럼의 1, df2에선 0번인덱스인 c컬럼의 3
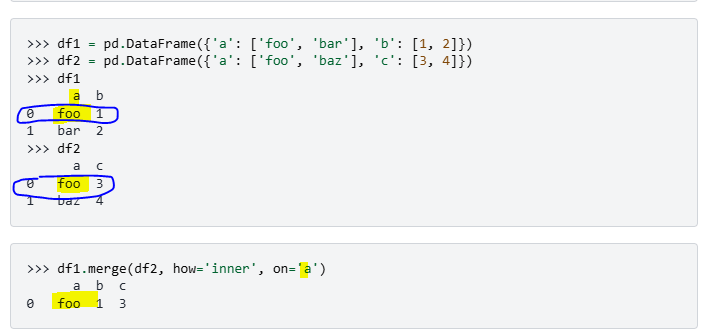
how = cross 는 데카르트곱이라는데 뭔지 잘 모르겠음
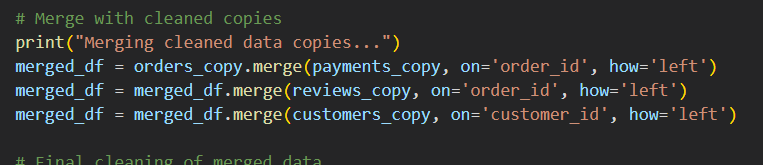
레프트 (오더카피) 기준으로 계속 오더아이디기준, 커스터머 아이디기준 계속 붙여서 한방에 보이는 표 만들기

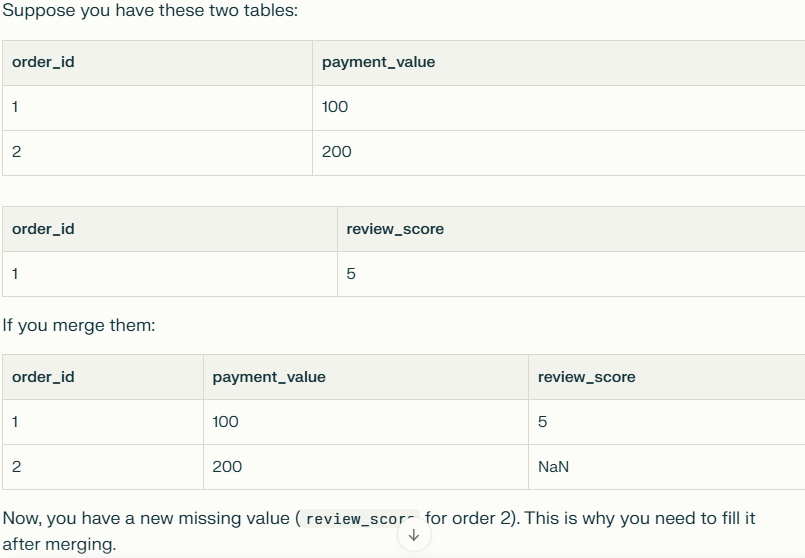
결측치 채우기. 머지하면 결측치가 새로 생기는경우가 잦음. 주문해도 리뷰안남긴경우
sort_values
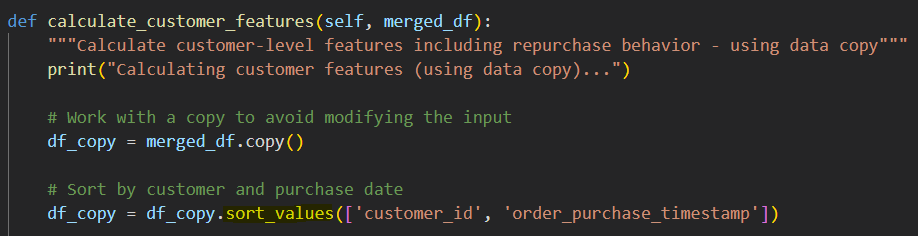
by 파라미터는 무슨 컬럼 기준으로 정렬할거냐는거. 바이=[리스트] 이렇게 리스트로 안에 여러 컬럼명 넣으면 젤 첫번째걸로 정렬하고 첫번째 컬럼기준으로 정렬하는데 동일한 애가 있다 ? 그럼 걔넨 리스트 안에 있던 다음 컬럼 기준으로 정렬하고 이렇게 함
Direction matters: If you have duplicate regions, it will use sales as the tiebreaker
데이터 전처리 순서
1.파일로드
2.파일 카피
3.결측치 드랍
4.csv파일이여서 날짜가 문자열타입된거 날짜타입으로 변환 후 칼럼에 적용 (안그러면 날짜끼리 빼고 계산하는거 못함)
5.
