데이터 파이프라인, 그리고 ETL
ETL
= Data Pipeline
= ETL
= Data Workflow
= DAG (Directed Acyclic Graph)
- Direct: 한방향으로 흐른다.
- Acyclic: 루프가 없다.
- 루프를 만들고 싶으면 다른 방법을 해야한다.
Extract
- Data를 Dump하는 것
- file을 다운받는다.
- 데이터 소스가 제공하는 api를 호출한다.
Transform
- 원하는 형태로 데이터를 변형하는 것
- 경우에 따라서는 Transform을 하지 않기도 한다.
- 원하는 것만 추출하기도 한다.
Load
- 데이터웨어하우스에 테이블로 저장한다.
ETL vs ELT
ELT
- 데이터웨어하우스 내부 데이터를 조작해서, 보통은 좀 더 추상화되고 요약된 새로운 데이터를 만드는 프로세스
- 데이터 분석가들이 많이 수행한다.
- 데이터 레이크 위에서 작업들이 벌어지기도 한다.
- 이 일을 Analytics Engineering이라고 한다.
- 이 프로세스 전용 툴로 가장 유명한 것은 DBT(Data Build Tool)이 있다.
데이터레이크 vs 데이터웨어하우스
데이터레이크
- Storage
- 용량이 크고 가격이 저렴하다.
- 구조화 데이터, 비구조화 데이터를 모두 저장한다.
데이터웨어하우스 (= Data Mart)
- 보존 기한이 있는 구조화된 데이터를 저장하고 처리(SQL)한다.
- BI 툴은 데이터웨어하우스를 백엔드로 사용한다.
Data Pipeline
- 데이터를 소스로부터 목적지로 복사하는 작업이다.
데이터파이프라인의 종류
-
Raw Data ETL Jobs
- 외부와 내부 데이터 소스에서 데이터를 읽고 (많은 경우 API를 통해서 가져온다.)
- 데이터 포맷을 변환한 후에 (데이터 크기가 커지면 Spark 등의 기술이 필요해진다.)
- 데이터 웨어하우스로 로드한다.
-
Summary/Report Jobs
-
DW(혹은 DL)로부터 데이터를 읽어 다시 DW에 쓰는 ETL
-
Raw Data를 읽어서 리포트 형태나 summary 형태의 테이블을 다시 만드는 용도
-
AB테스트 결과를 분석하는 데이터 파이프라인도 존재
-
요약 테이블의 경우 SQL만으로 만든다. 주로 데이터 분석가들이 한다.
- Analytics Engineer
- DBT
-
데이터 엔지니어 관점에서는 어떻게 데이터 분석가들이 편하게 분석할 수 있는 환경을 만들어주냐를 고민해야 한다.
-
-
Production Data Jobs
- 결과의 목적지가 데이터 시스템 밖인 것
- DW로부터 데이터를 읽어 다른 Storage로 쓰는 ETL
- Summary 정보가 프로덕션 환경에서 성능 이유로 필요한 경우
- 머신러닝 모델에서 필요한 피쳐들을 미리 계산해두는 경우
데이터 파이프라인을 만들 때 고려할 점
Full refresh or Incremental Update
- Full refresh가 가능할 때는 Full refresh를 한다.
- 데이터 크기가 커지면 힘들어진다.
- 시간이 오래걸리는 경우
- 데이터 크기가 커지면 힘들어진다.
- Incremental update만 가능하다면, 대상 데이터 소스가 갖춰야 할 몇가지 조건을 만족시키자.
- 데이터 소스가 프로덕션 테이블이라면 다음 필드가 필요하다:
- created
- modified
- deleted
- 데이터 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을 읽어올 수 있어야 한다.
- 데이터 소스가 프로덕션 테이블이라면 다음 필드가 필요하다:
멱등성(Idempotency)
- 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 않아야 함
- 중복 데이터 x
- Full refresh의 경우 모두 삭제하고 새로 copy한다.
- critical point들이 모두 one atomic action으로 실행되어야 한다.
- SQL transaction이 필요하다.
Backfill
- 재실행하는 과정
- 실패한 데이터 파이프라인은 재실행할 수 있어야 한다.
- Airflow는 backfill에 강점이 있다.
데이터 파이프라인의 입출력을 명확히 하고 문서화
- 비즈니스 오너 명시
- 누가 이 데이터를 요청했는지 기록으로 남길 것
- (테크니털 오너는 코드를 작성한 사람)
- 유닛테스트 작성하기
- 입력 레코드 수와 출력 레코드의 수가 몇개인지 체크하는 것부터 시작
- summary table을 만들어내고 PK가 있다면 PK uniqness가 보장되는지 체크
- 중복 레코드 체크
- 데이터 카탈로그로 들어가서 데이터 디스커버리에 사용 가능하도록 한다.
- 데이터 리니지
- 데이터의 생애주기를 추적하고 시각화하는 것
- 데이터가 어디에서 왔는지, 어떻게 변형되었는지, 어디로 이동하는지에 대한 정보 제공
- 데이터 관리, 품질, 거버넌스에 중요한 역할을 한다.
- 데이터 거버넌스
- 조직 내 데이터 자산의 관리 및 운영에 대한 전략적 접근법
- 데이터 품질, 일관성, 가용성, 보안 및 규정 준수를 보장하기 위한 정책, 절차, 기준 및 기술의 체계적인 집합..?
- 조직 내에서 데이터를 효과적으로 관리하고 활용해 비즈니스 목표를 달성하는 것이 목적
주기적으로 사용되지 않는 데이터를 삭제한다.
- Kill unused tables and pipelines proactivley
- Retain only necessary dta in DW and move past data to DL
데이터 파이프라인 사고시 마다 리포트(post-mortem) 쓰기
- 동일한 사고 혹은 비슷한 사고가 발생하는 것을 막기 위한 목 적
- 사고 원인(root-cause)를 이해하고 이를 방지하기 위한 action item의 실행
- 기술 부채의 정도를 이야기해주는 바로미터이다.
- management support가 필요하다.
Airflow
Airflow 소개
- stable한 버전을 확인해보기 위해 Google Cloud에서 어떤 버전을 사용하는지 알아보자. Cloud Composer version list | Google Cloud
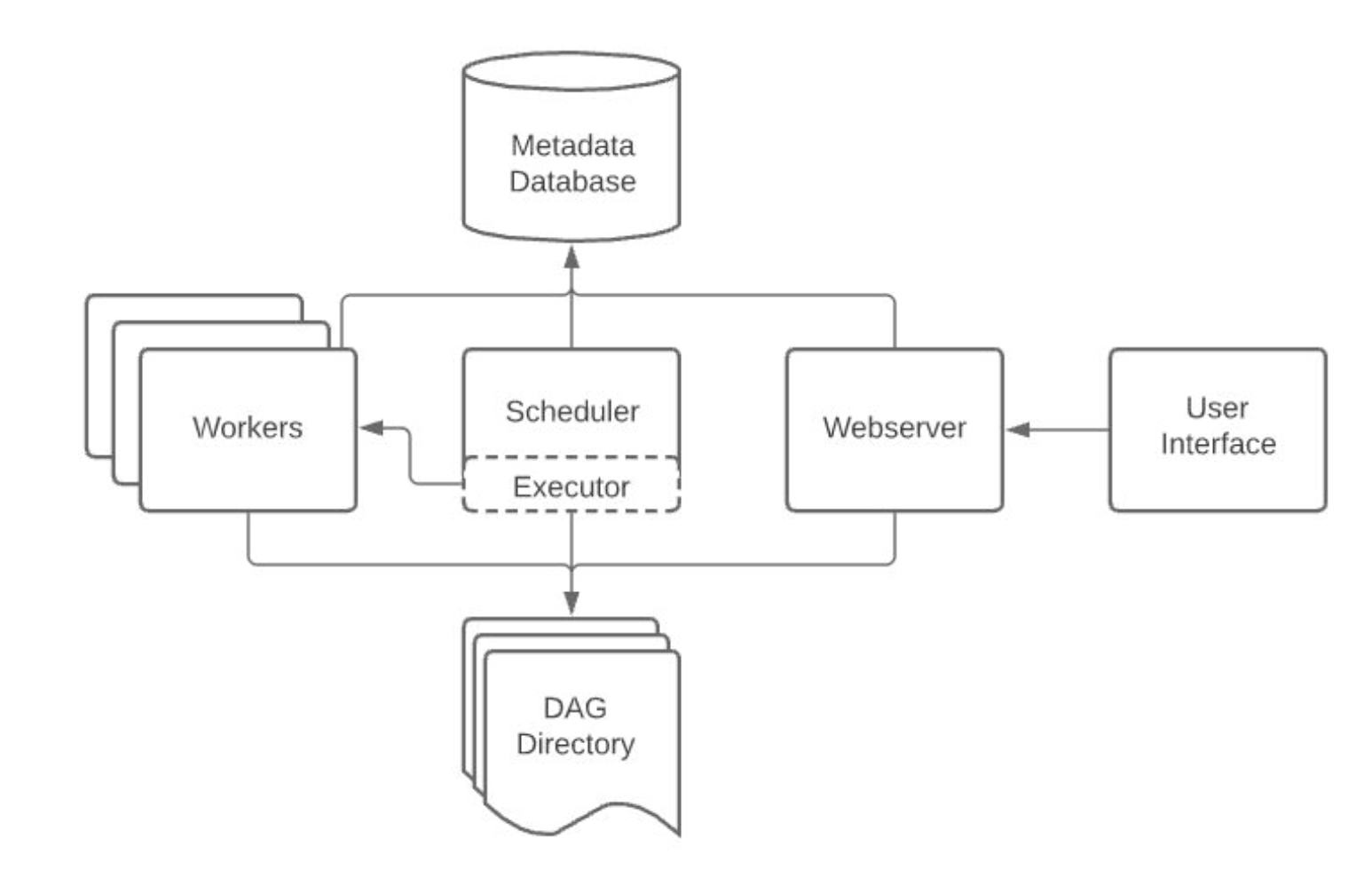
Airflow 구성
컴포넌트
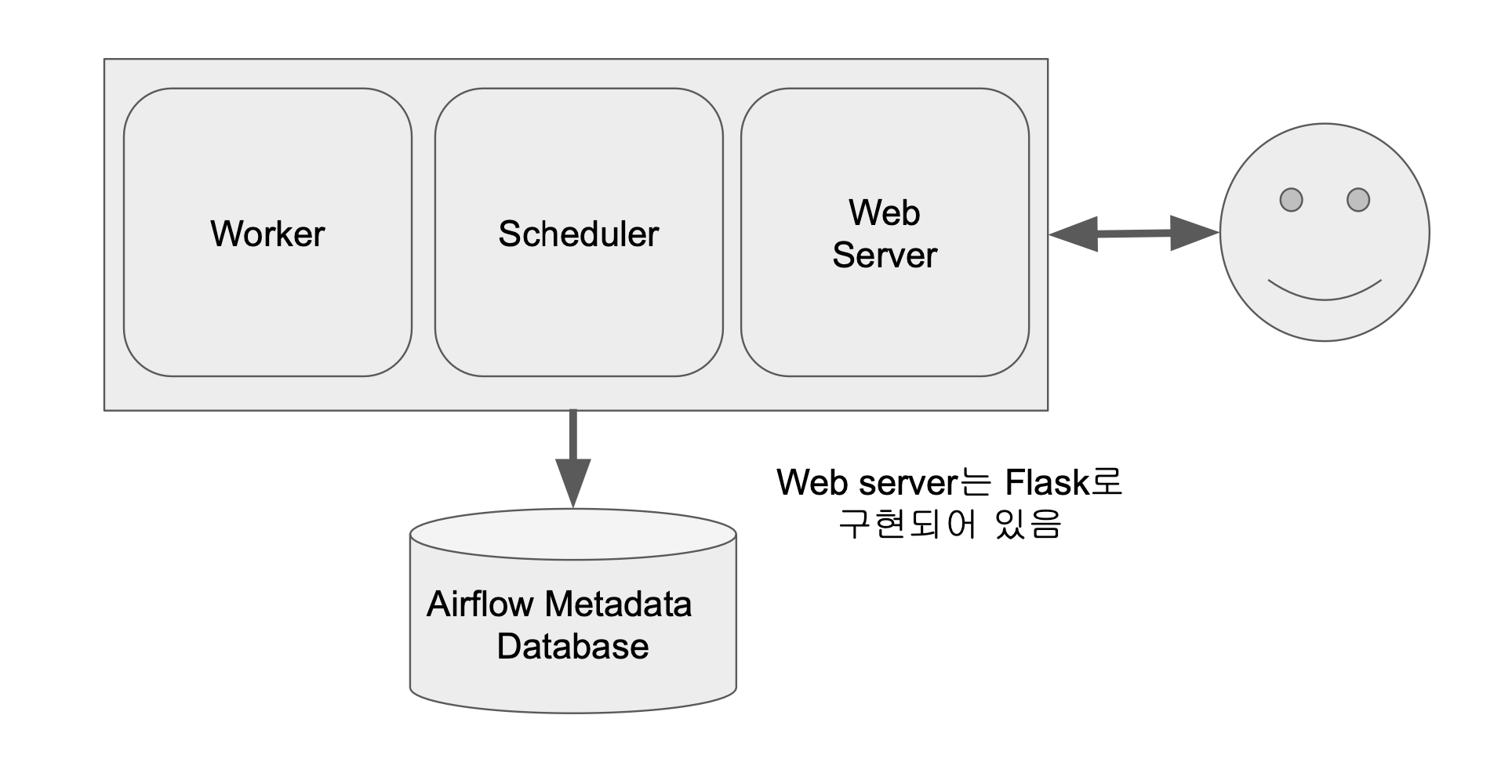
- 웹 서버
- Flask
- 웹 UI는 스케줄러와 DAG의 실행 상황을 시각화해준다.
- 스케줄러 - Master
- 파이프라인을 정해진 순서로 실행
- 스케줄러는 DAG(Task의 집합) 안에 있는 Task를 Worker에게 배정한다.
- 워커
- DAG(Task)를 실행
- 스케일링은 워커의 수를 늘리는 것
- 메타 데이터 데이터베이스
- Sqlite가 default
- 싱글스레드
- 파일기반 데이터베이스
- MySQL이나 Postgres를 쓰는게 일반적이다.
- 스케줄러와 각 DAG의 실행결과가 저장된다.
- Sqlite가 default
- 큐
- 워커가 다수가 되는 경우, 먼저 큐에 Tasks를 쌓고 Queue에 있는 Tasks를 워커에 할당한다.
- Airflow가 Executor를 쓰느냐에 따라 달라진다.
서버 한 대
서버 여러 대
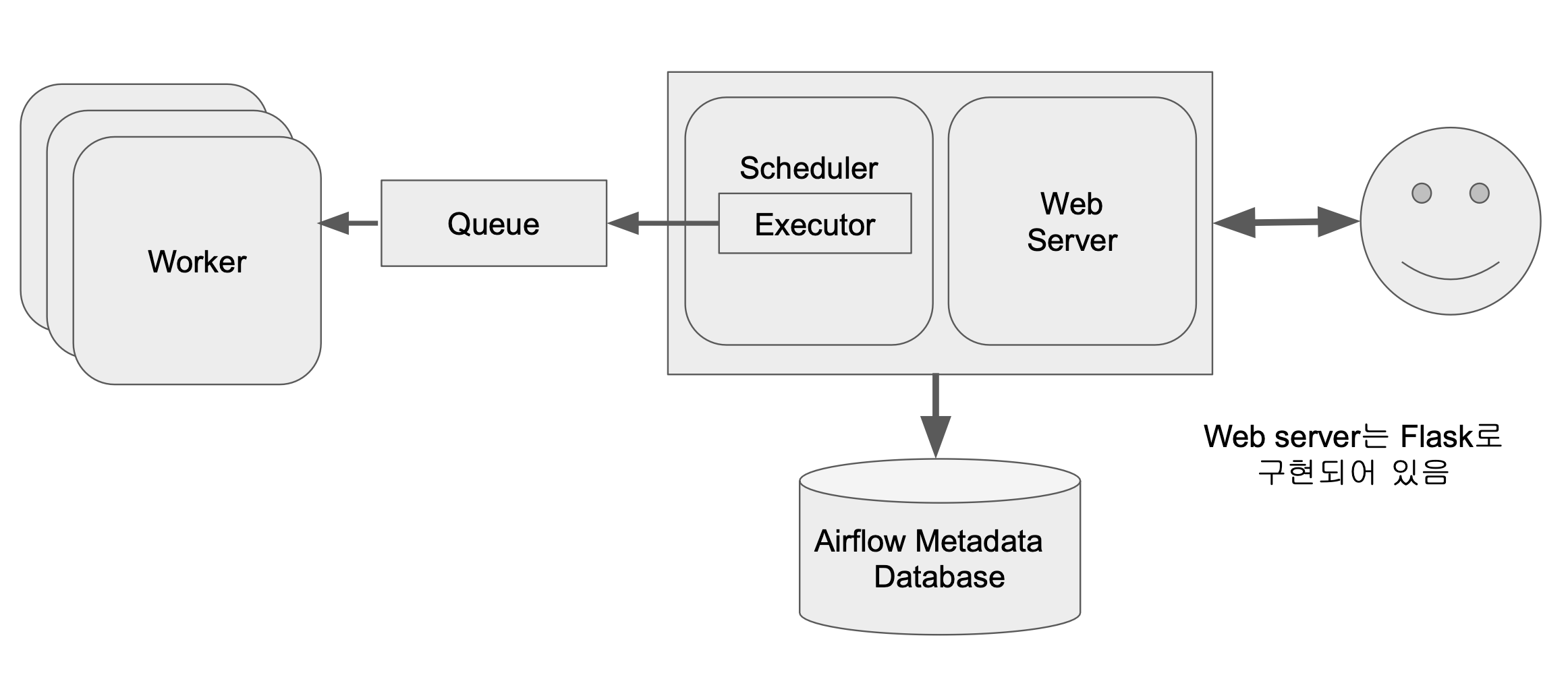
Executor의 종류
- Sequential Executor (Default, SQLite와만 돌아간다.)
- Local Executor (많이 사용한다.)
- Celery Executor
- Kubernetes Executor
- Celery Kubernetes Executor
- Dask Executor
장단점
장점
- 데이터 파이프라인을 세밀하게 제어 가능
- 다양한 데이터 소스와 데이터 웨어하우스 지원
- Backfill
단점
- 러닝커브
- 개발환경
- 직접 운영이 쉽지 않아서 클라우드 버전 사용이 선호된다.
- GCP: Cloud Composer
- AWS: Managed Workflows for Apache Airflow
- Azure: Data Factory Managed Airflow
DAG
DAG는 Task로 구성되고 Task는 Operator로 만들어진다?
