4. 다른 값으로 결측치 대체
df.select(
[F.count(F.when(F.isnull(c), c)).alias(c) for c in df.columns]
).show()
df.select("Category", "CategoryName").show()
# 결과값:
# +--------+--------------------+
# |Category| CategoryName|
# +--------+--------------------+
# | 1081317| GRAPE SCHNAPPS|
# | 1052010|IMPORTED GRAPE BR...|
# | 1031080| VODKA 80 PROOF|
# | 1032080| IMPORTED VODKA|
# | 1051010|AMERICAN GRAPE BR...|
# | 1082900|MISC. IMPORTED CO...|
# +--------+--------------------+Category는 CategoryName의 ID로 보인다. Category는 있는데, CategoryName이 없는 경우가 있을까?
(
df
.filter(F.col("Category").isNotNull()) # Category는 null이 아님
.filter(F.col("CategoryName").isNull()) # CategoryName은 null
).show()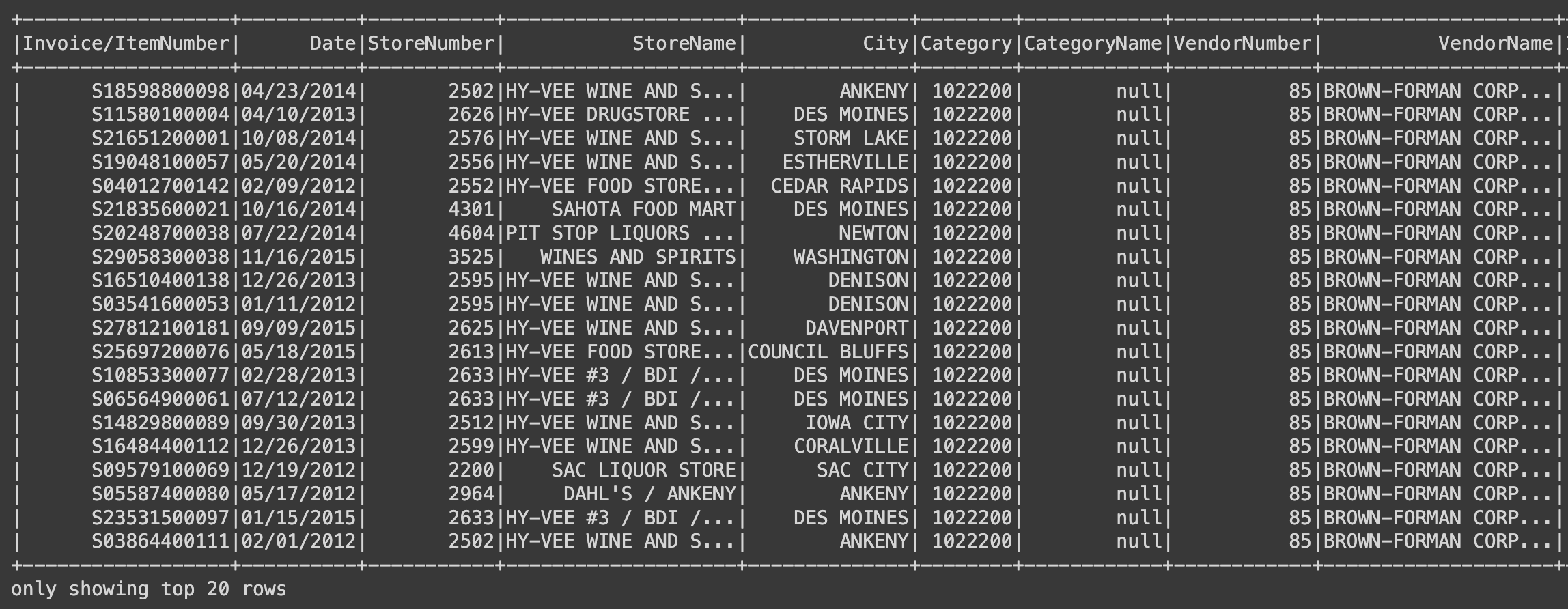
(
df
.filter(F.col("Category")==1022200) # 특정 카테고리 ID
.filter(F.col("CategoryName").isNotNull())
).show()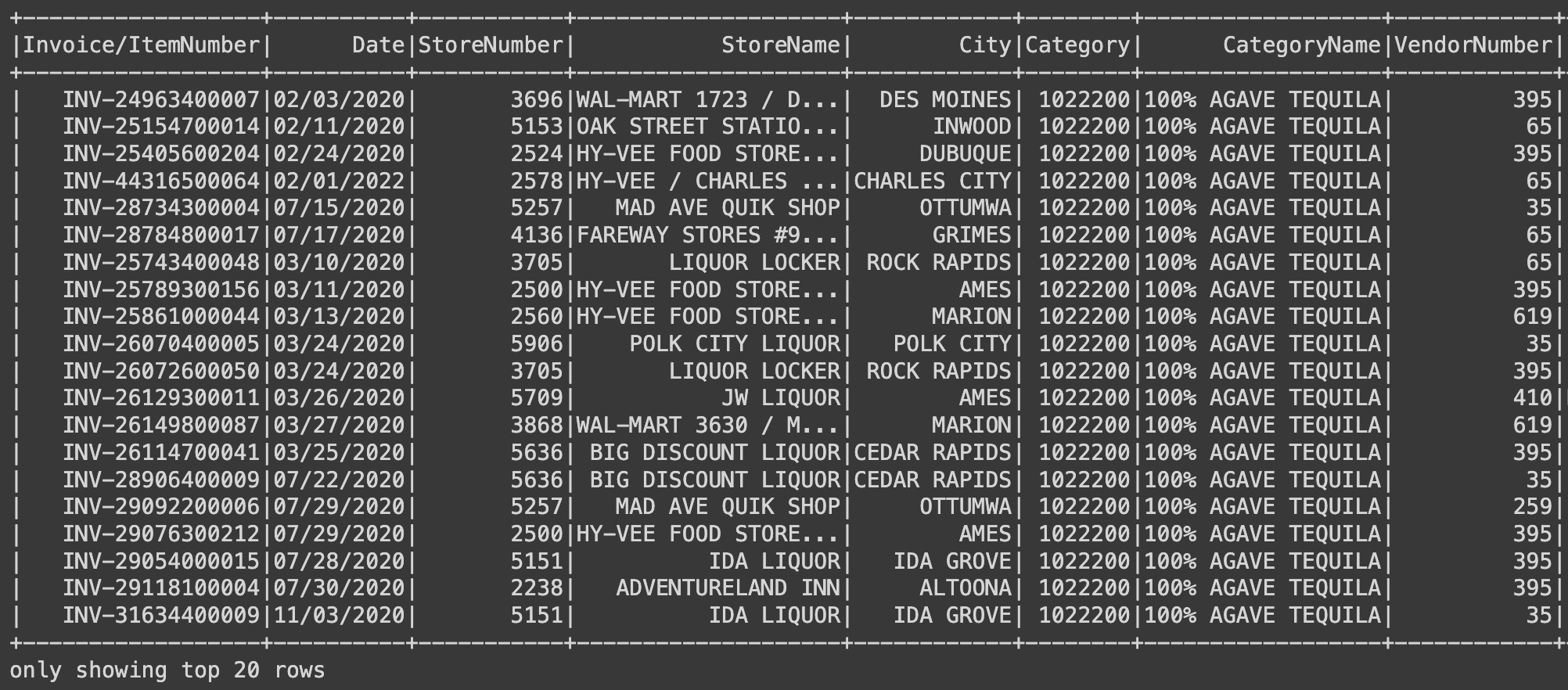
Category가 "1022200"이면 CategoryName은 "100% AGAVE TEQUILA"로 보인다.
하지만, Category가 같더라도 CategoryName이 다른 경우는 없을까?
from pyspark.sql import functions as F
from pyspark.sql import Window as W
(
df
.withColumn(
"CategoryName_cnt",
F.size(
F.collect_set("CategoryName").over(W.partitionBy("Category"))
)
)
.filter(F.col("CategoryName_cnt") >= 2)
).show()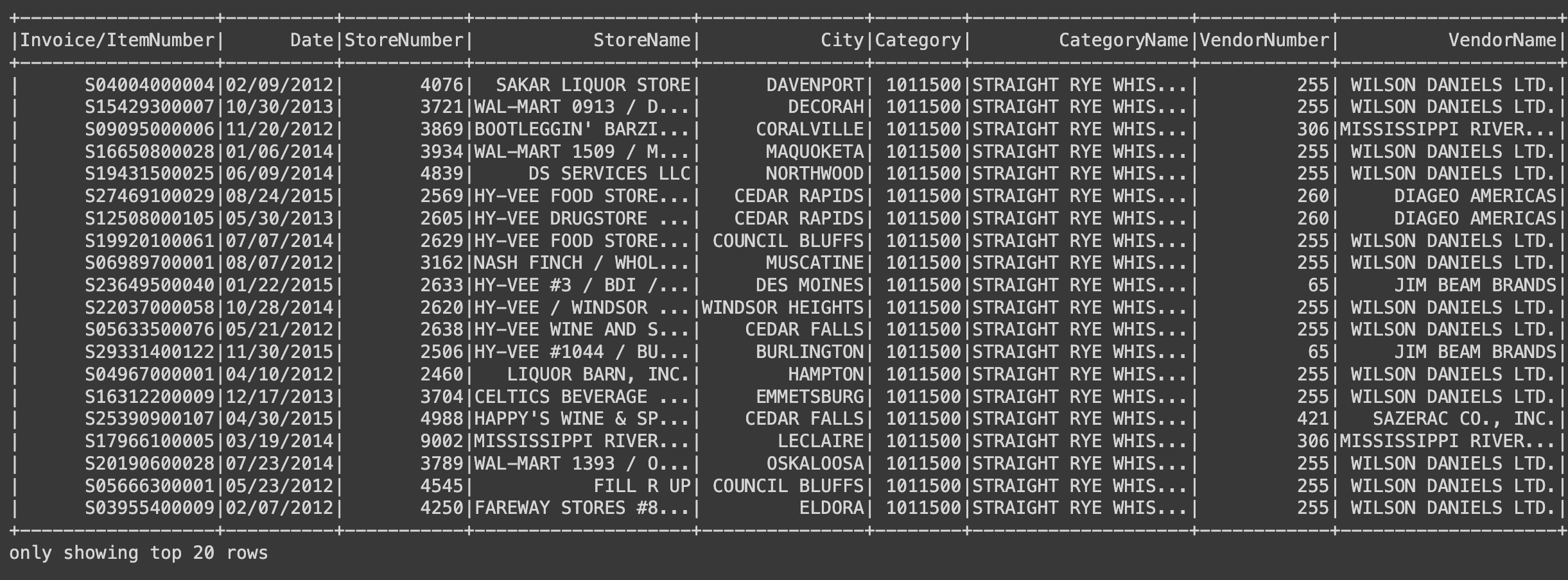
- withColumn
- 기존 컬럼의 업데이트, 타입 변경, 신규 컬럼 값 추가
- withColumn(신규 컬럼명, 신규 컬럼값)
- 컬럼명 변경은 withColumnRename() 메서드
- size
- 컬럼에 있는 array의 길이를 반환
- list 형태의 len과 유사한 기능
- collect_set
- object들의 고유 집합 (= distinct한)을 반환
- 요소를 set으로 묶음
- (자매품) collect_list
- object들의 집합을 반환
- 요소를 list로 묶음
- over
- 컬럼의 window를 정의
- window란: 일정한 기준으로 묶인 row들
- Window
- 위 window를 정의하기 하기위해 사용
- partitionBy
- window 중 그룹을 묶는 함수
- groupBy와 유사
예시:
sample_df = spark.createDataFrame(
[(2,), (5,), (5,)],
('age',)
)
sample_df.show()
# +---+
# |age|
# +---+
# | 2|
# | 5|
# | 5|
+---+sample_df.select(F.collect_set('age')).show()
# +----------------+
# |collect_set(age)|
# +----------------+
# | [5, 2]|
# +----------------+sample_df.select(F.collect_list('age')).show()
# +-----------------+
# |collect_list(age)|
# +-----------------+
# | [2, 5, 5]|
# +-----------------+sample_df.select(F.size(F.collect_set('age'))).show()
# +----------------------+
# |size(collect_set(age))|
# +----------------------+
# | 2|
# +----------------------+sample_df.select(F.size(F.collect_list('age'))).show()
# +----------------------+
# |size(collect_set(age))|
# +----------------------+
# | 3|
# +----------------------+예시 2:
sample_df = spark.createDataFrame(
[(1, "a"), (1, "a"), (2, "a"), (1, "b"), (2, "b"), (3, "b")],
["id", "category"]
)
sample_df.show()
# +---+--------+
# | id|category|
# +---+--------+
# | 1| a|
# | 1| a|
# | 2| a|
# | 1| b|
# | 2| b|
# | 3| b|
# +---+--------+(
sample_df
.withColumn("id_set",
F.collect_set("id").over(W.partitionBy("category"))
)
.withColumn("id_list",
F.collect_list("id").over(W.partitionBy("category"))
)
).show()
# +---+--------+---------+---------+
# | id|category| id_set| id_list|
# +---+--------+---------+---------+
# | 1| b|[1, 2, 3]|[1, 2, 3]|
# | 2| b|[1, 2, 3]|[1, 2, 3]|
# | 3| b|[1, 2, 3]|[1, 2, 3]|
# | 1| a| [1, 2]|[1, 1, 2]|
# | 1| a| [1, 2]|[1, 1, 2]|
# | 2| a| [1, 2]|[1, 1, 2]|
# +---+--------+---------+---------+Category를 기반으로 CategoryName 결측치를 채워보자.
df = (
df
.withColumn(
"CategoryName", # 원래 있는 컬럼과 동일한 이름으로 withColumn을 할 경우, 기존 컬럼에 덮어쓰기가 됩니다.
F.first(
F.col("CategoryName"), ignorenulls=True # null인 경우를 제외하고 가장 첫번째
).over(W.partitionBy(F.col("Category")).orderBy(F.col("Date").desc()))
# 다른경우가 존재하기 때문에 가장 최근 날짜 기준 이름으로 덮어쓰기
)
)
- first
- 가장 첫번 째 값을 반환
- orderBy
- 정렬을 위한 함수
- 기본적으로 오름차순 정렬
- 내림차순 정렬을 원한다면.desc()
예시:
sample_df = spark.createDataFrame(
[(1, "a"), (1, "a"), (2, "a"), (1, "b"), (2, "b"), (3, "b")],
["id", "category"]
)
sample_df.show()
# +---+--------+
# | id|category|
# +---+--------+
# | 1| a|
# | 1| a|
# | 2| a|
# | 1| b|
# | 2| b|
# | 3| b|
# +---+--------+(
sample_df
.withColumn("first_id", F.first("id").over(W.partitionBy("category")))
).show()
# +---+--------+--------+
# | id|category|first_id|
# +---+--------+--------+
# | 1| b| 1|
# | 2| b| 1|
# | 3| b| 1|
# | 1| a| 1|
# | 1| a| 1|
# | 2| a| 1|
# +---+--------+--------+(
sample_df
.withColumn(
"first_id",
F.first("id").over(
W.partitionBy("category").orderBy(F.col("id").desc())) # category 별로 id의 내림차순 순으로 windowing
)
).show()
# +---+--------+--------+
# | id|category|first_id|
# +---+--------+--------+
# | 3| b| 3|
# | 2| b| 3|
# | 1| b| 3|
# | 2| a| 2|
# | 1| a| 2|
# | 1| a| 2|
# +---+--------+--------+위에서 Category 기반으로 CategoryName의 결측치를 채웠지만 모든 결측치를 대체하지 않았을 수 있기 때문에 아래와 같이 Category와 CategoryName의 결측치 수를 다시 확인해보자.
category_cols = ["Category", "CategoryName"]
df.select(
[F.count(F.when(F.isnull(c), c)).alias(c) for c in category_cols]
).show()df = df.filter(F.col("Category").isNotNull()).filter(F.col("CategoryName").isNotNull())
df.count()소수의 결측치를 가지고 있는 컬럼의 결측치를 제거하자.
null_cols = ["VendorNumber", "VendorName", "StateBottleCost", "StateBottleRetail", "SaleDollars"]
for col_name in null_cols:
print(col_name, df.filter(F.col(col_name).isNull()).count())
df = df.filter(F.col(col_name).isNotNull())df.select(
[F.count(F.when(F.isnull(c), c)).alias(c) for c in df.columns]
).show()이제 모든 결측치가 제거되었다.
5. 데이터 타입 변환
위에서 데이터프레임을 확인했을 당시 "Date" 컬럼의 데이터 타입이 string이다.
df.select("Date").show(2)
# +----------+
# | Date|
# +----------+
# |12/31/2021|
# |12/31/2021|
# +----------+# 월/일/년 이라는 특이한 방식으로 저장되어있음
df = df.withColumn("Date", F.to_date(F.col("Date"), 'MM/dd/yyyy'))
- to_date
- string을 date 형태로 바꿔줌
- F.to_date(변형할 컬럼, format="현재 string이 어떤 형태로 써져있는지 명시")
- 시간 형태를 위한 또 다른 매서드
- to_timestamp
- string을 timestamp 형태로 변형
- F.to_timestamp(변형할 컬럼, format="현재 string이 어떤 형태로 써져있는지 명시")
- MM-dd-yyyy HH:mm:ss.SSS‘
- to_timestamp
df.select("Date").show(2)
# +----------+
# | Date|
# +----------+
# |2021-12-31|
# |2021-12-31|
# +----------+df.printSchema()
# root
# |-- Invoice/ItemNumber: string (nullable = true)
# |-- Date: date (nullable = true)
# |-- StoreNumber: integer (nullable = true)
# |-- StoreName: string (nullable = true)
# |-- Address: string (nullable = true)
# |-- City: string (nullable = true)
# |-- ZipCode: string (nullable = true)
# |-- County: string (nullable = true)
# |-- Category: integer (nullable = true)
# |-- CategoryName: string (nullable = true)
거북선통통통통