1. Spark
Spark는 범용적인 목적을 지닌 분산 클러스터 컴퓨팅 오픈소스 프레임워크이다.
분산 클러스트는 시스템의 전반적인 성능을 향상시키기 위해 계산 부하량을 여러 노드에서 분담하여 병렬 처리하도록 구성하는 방식이다.
1.1 Spark의 구조
여러 컴퓨터의 자원을 모아 하나의 컴퓨터처럼 사용하는 전반적인 구조이다.
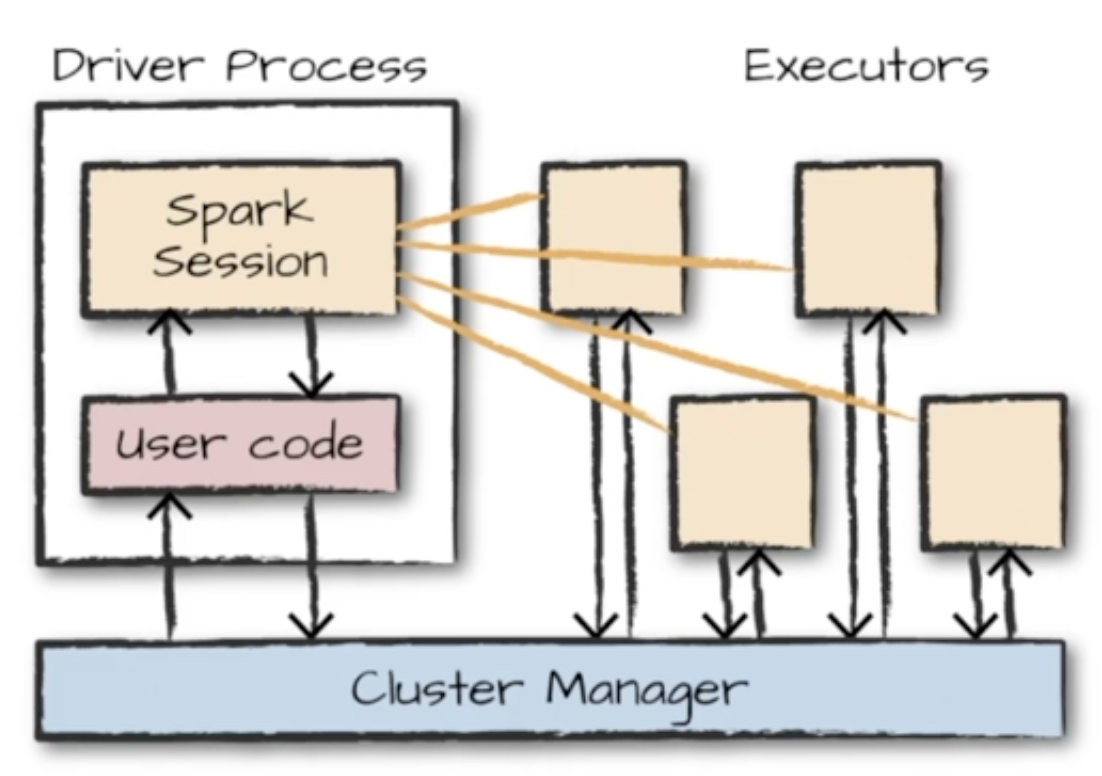
1) 클러스터 관리자(Cluster Manager)
- 사용 가능한 자원을 파악
- 클러스터의 데이터 처리 작업을 관리하고 조율
- 사용자는 클러스터 관리자에게 스파크 애플리케이션을 제출
2) 드라이버 프로세스(Driver Process)
- 클러스터 노드 중 하나
- 드라이버 프로그램의 명령을 Excutor에서 실행하도록 분석,배포, 스케쥴링
3) Executor 프로세스
- 각 Excutor는 드라이버 프로세스가 할당한 작업을 수행
- 진행 상황을 다시 드라이버 노드에 보고하는 역할
4) Spark Session
- 스파크 으용 프로그램의 통합 진입점
- 스파크의 기능들과 구조들이 상호작용하는 방식을 제공
1.2 Spark의 데이터 처리 방식
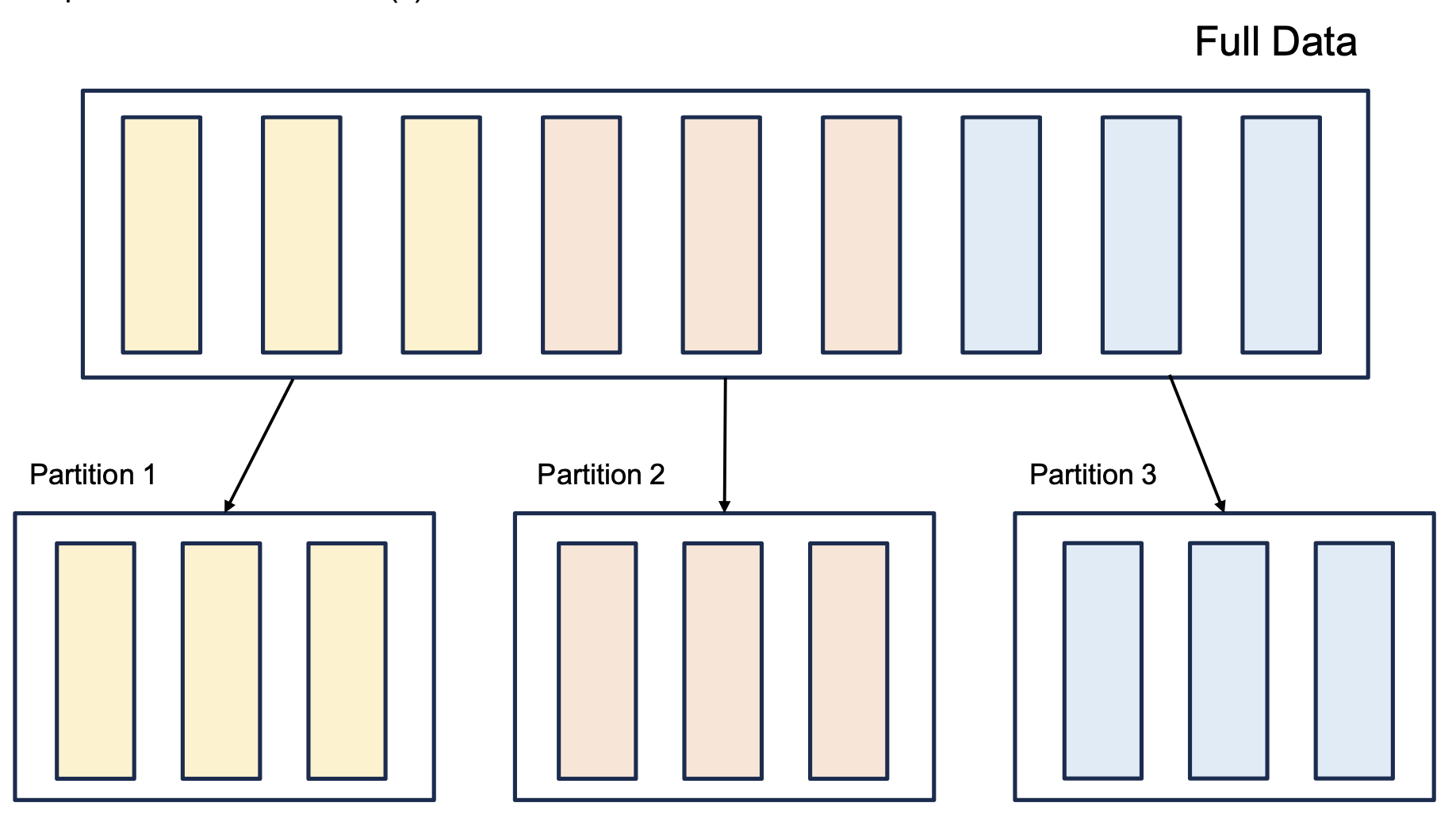
1) Partition
- 모든 Executor가 병렬로 작업을 수행할 수 있도록 '파티션'이라고 불리는 청크 단위로 데이터를 분할
- 파티션은 크러스터의 물리적 머신에 존재하는 row의 집합
위에서 데이터 분할이 데이터프레임(Dataframe)이 되는게 많다.
Dataframe:
- 테이블의 데이터 행과 열로 단순하게 표현
- 데이터프레임의 파티션은 실행 중에 데이터가 컴퓨터 클러스터에서 물리적으로 분산되는 방식
∴ Spark의 병렬성은 파티션과 Executor의 갯수로 결정된다.
2) Transformation
- Spark의 핵심 데이터 구조는 불변성을 가짐
- 쿼리를 날리는 식으로 변경을 원할 때 변경 방법을 Spark에게 알려주는 Transformation
- 논리적 실행 계획을 세우게 됨
- 즉, 실제 연산이 일어나는 것은 아님
3) Lazy Evaluation & Action
Lazy Evaluation
- 특정 연산 명령이 내려진 즉시 데이터를 수정하지 않고, 원시 데이터에 적용할 트랜스포메이션만 실행
- 액션 전까지 전체 데이터 흐름을 최적화하는 강점을 지님
Action
- 실제 연산을 수행하기 위한 사용자 명령 (트랜스포메이션으로부터 결과를 계산하도록 지시)
예시: 카운트, 콘솔에서 데이터를 보는 액션, 출력 데이터 소스에 저장하는 액션
1.2.1 Spark의 카탈리스트
- 트랜스포메이션을 적용할 때, 스파크 SQL은 논리 계획이 담긴 트리 그래프를 생성
- 해당 Optimizer에 의해 최적의 논리를 받아와 데이터를 반환해주기 때문에 성능이 더욱 좋음
1.2.2 카탈리스트의 논리 계획 4단계
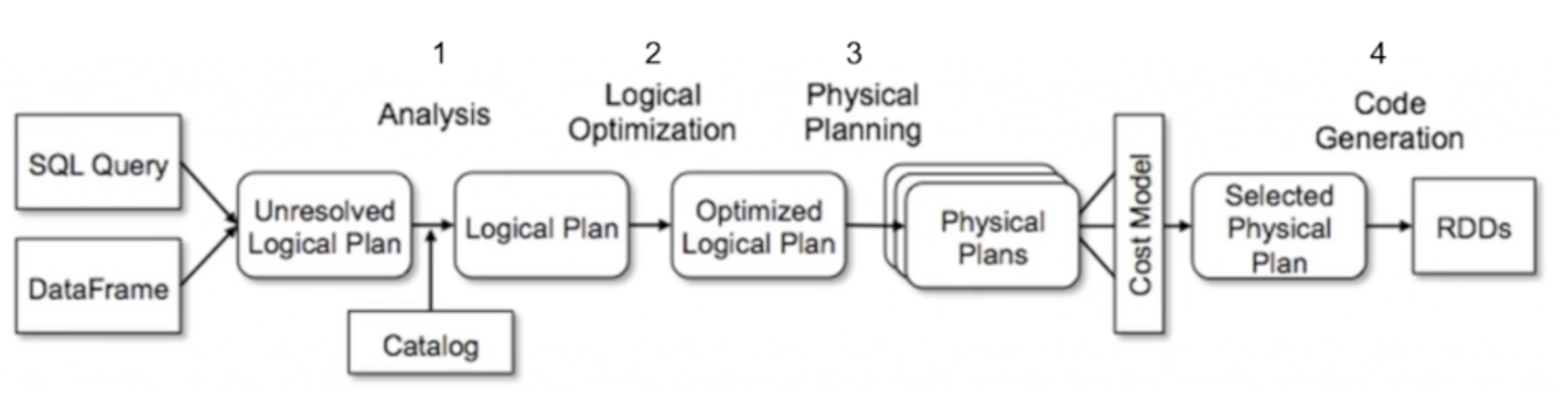
데이터프레임을 가지고 SQL 쿼리를 날리면 카탈로그가 개입을 해서 첫번째 단계인 분석(Analysis) 단계를 수행한다. 데이터프레임 객체에 relation을 연산하여 추가적으로 데이터 특성을 분석하고 컬럼의 타입 또는 컬럼이 valid한지 기본적인 분석을 진행한다.
두번째 단계인 Logical Optimization은 논리 연산을 수행하는데 있어 최적화를 시켜주게 된다. 예를 들어, 필요한 연산을 줄이기 위해 연산의 순서 배치를 바꾼다던가 연산에 필요한 컬럼만을 데이터프레임에서 불러오는 식으로 논리 계획을 최적화하는 플랜을 짠다.
세번째 단계인 Physical Planning은 논리 계획을 이용해서 수행할 Pysical plan을 한개 이상 반환하는 단계를 거치게 된다. 이 단계에서 가장 적은 비용으로 연산할 수 있는 최적화도 함께 진행을 한다.
네번째 단계인 Code Generation으로 Spark로 보낸 SQL 쿼리를 각 Executor에서 실행할 수 있도록 spark는 자바 기반의 프레임워크이기 때문에 실제로 실행이 될 수 있도록 Java bite 코드로 변환을 해주게 된다.
1.2.3 카탈리스트의 장점
- Spark에서 파티션은 부분으로 나눈다는 의미
- 데이터를 shuffling하고 파티션하여 나뉜 데이터에서 연산을 처리하는 경우, 네트워크 연산(node들의 통신)이 일어나게 된다.
연산 속도는 인메도리 >> 디스크 I/O >> 네트워크 순으로 빠르다.
그런데 shuffling은 네트워크 연산이기 때문에 앞에서 데이터가 어느 정도 정리가 된 후에 해야한다. - 데이터가 정리된 부분을 카탈리스트가 계획적으로 자동 최적화
2. PySpark
PySpark는 Python 환경에서 Apache Spark를 사용할 수 있는 인터페이스
즉, PySpark는 Spark용 API

2.1 PySpark 기능 및 라이브러리

1) Spark SQL and DataFrames
- 대용량 정형 데이터 처리를 위해 SQL 인터페이스를 지원하는 PySpark
- SQL 쿼리 사용 가능
- 데이터 표현 형식은 Dataframe이며, 이는 RDBMS(관계형 데이터 베이스 관리 시스템)의 table과 유사한 2차원 구조

2) Pandas API on Spark
- Pandas API를 지원
- Pandas와 같은 문법을 사용할 수 있다는 장점
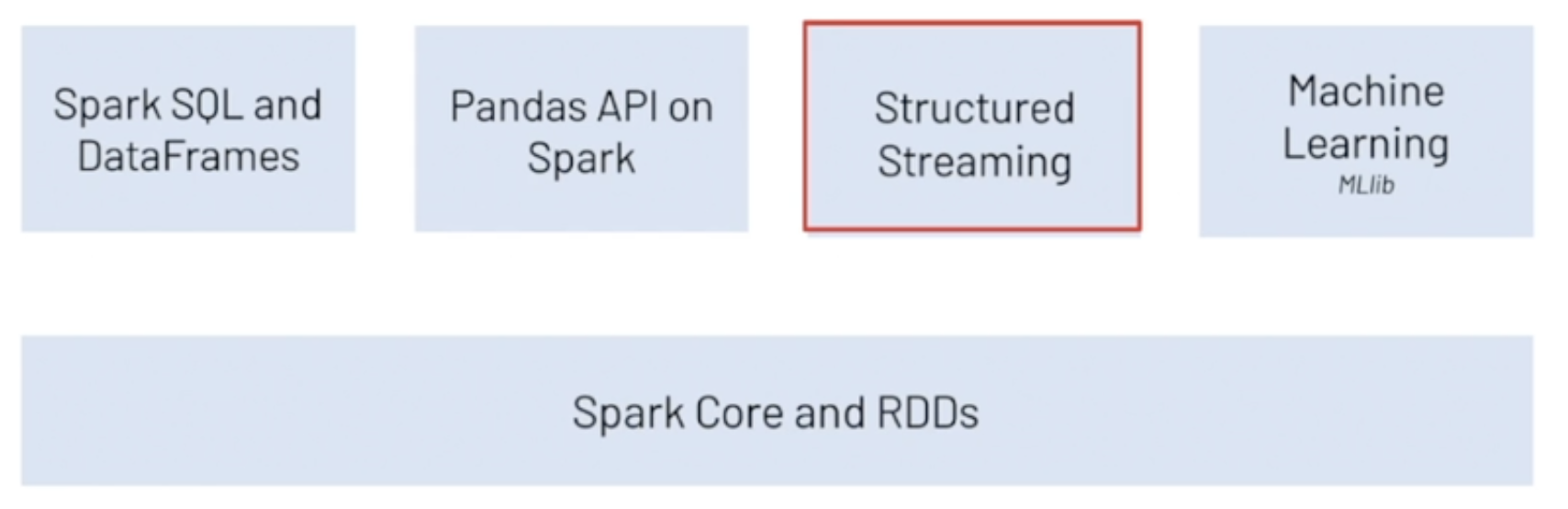
3) Structured Streaming
- Spark SQL 엔진에 구축된 스트림 처리 엔진
- 정적 데이터에 배치 계산을 하는 것과 같은 방식으로 스트리밍 계산을 표현할 수 있는 장점

4) Machine Learning
- Spark의 머신런닝 라이브버리
- 데이터 병렬 처리 방법론을 활용해 모델링이 가능
- Classification, Regression, Clustering, Dimension Reduction, Optimization 등 다양한 활용처
