- 분류: Video Generation, Multi-modal
- 저자: Zhe Kong, Feng Gao, Yong Zhang†, Zhuoliang Kang, Xiaoming Wei, Xunliang Cai, Guanying Chen, Wenhan Luo†
- 소속: Shenzhen Campus of Sun Yat-sen University, Meituan, Division of AMC and Department of ECE, HKUST
- paper: https://arxiv.org/pdf/2505.22647v1
키워드: Audio-driven animation, multi-person video generation, video diffusion model, L-RoPE, instruction-following capability
| 프롬프트와 멀티 스트림 음성 입력으로 다중 인물의 대화 영상 생성 |
|---|
 |
1. 연구 배경
기존의 오디오 기반 휴먼 애니메이션 기술은 주로 한 사람의 얼굴(talking head)이나 몸체(talking body) 애니메이션에 집중되어 있었으며, 여러 명이 참여하는 대화 영상 생성에는 한계가 있었다. 특히 다중 오디오 입력을 처리하지 못하거나, 오디오와 사람 간의 매핑이 부정확하여 프롬프트에 따른 복잡한 동작 지시를 제대로 따르지 못하는 문제가 있었다. 이 연구는 이러한 한계를 극복하고자 다중 인물의 대화 영상을 오디오로부터 생성하는 새로운 과제를 제안한다.
2. 핵심 아이디어 및 방법론
본 연구는 MultiTalk이라는 새로운 프레임워크를 제안하여 오디오 기반 다중 인물 대화 영상 생성 문제를 해결한다.
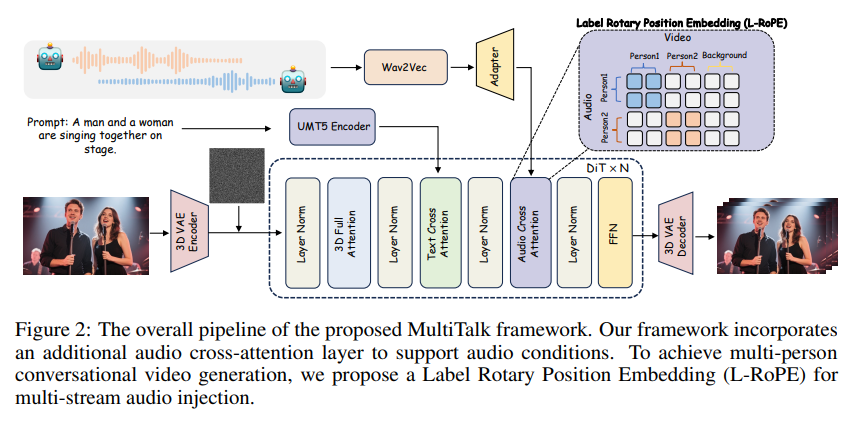
- Label Rotary Position Embedding (L-RoPE)
다중 오디오 스트림과 다중 인물을 정확히 매핑하기 위해 설계된 기법으로, 오디오 임베딩과 비디오 라텐트에 동일한 라벨을 할당하여 특정 영역의 오디오 cross-attention을 활성화 - 훈련 전략
- Partial Parameter Training: 오디오 cross-attention 및 오디오 어댑터 레이어만 학습하고 나머지 네트워크는 고정
- Multi-task Training: 오디오 + 이미지 - 비디오(AI2V) 훈련과 이미지-비디오(I2V) 훈련을 혼합하여 모델의 지시 수행 능력 유지
- Autoregresive Long Video Generation: 이전 프레임을 조건으로 사용하여 긴 영상 생성 가능
3. 실험 및 핵심 작업
- 사용 데이터
1. 약 2k 시간 분량의 단일 인물 얼굴/상체 영상 데이터
2. 100시간 분량의 2인 대화 영상 데이터
(+) 20만 개의 다중 이벤트 및 인간-객체 상호작용 영상 클립 사용- 전처리 및 모델
Wav2Vec로 오디오 임베딩 추출
DiT(Diffusion-in-Transformer) 기반 비디오 디퓨전 모델 사용
* 3D VAE로 시공간 압축

- 하드웨어: 64 NVIDIA H800-80G GPU 사용
- 하이퍼파라미터
| Parameter | Value |
|---|---|
| learning rate | 2e-5 |
| optimizer | AdamW |
| (stage 1) batch size | 64 |
| (stage 2) batch size | 32 |
4. 결과 및 분석
-
정량적 평가
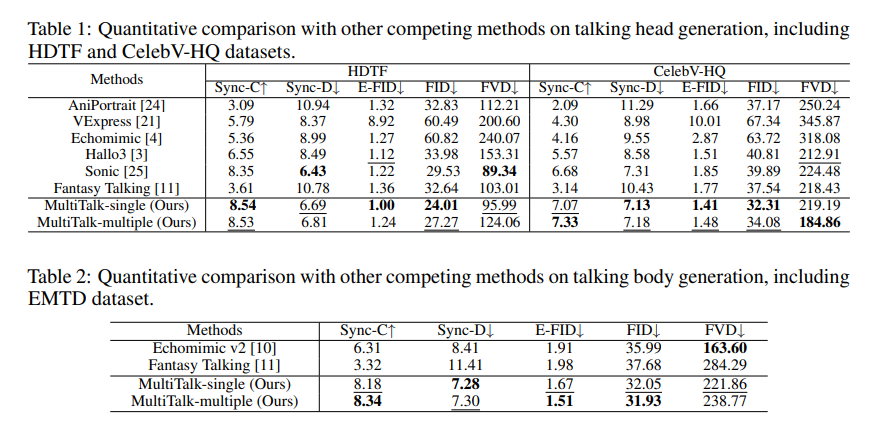
* 기존 방법들(AniPortrait, VExpress, Echomimic 등) 대비 HDTF, CelebV-HQ, EMTD 데이터셋에서 우수한 Sync-C, Sync-D, FID, E-FID, FVD 성능 달성 * 다중 인물 데이터셋(MTHM)에서 최초로 평가 진행 -
정성적 평가
- 지시 수행 능력이 우수하여 텍스트 프롬프트에 따라 더 자연스러운 인터렉션 생성
- artifacts 및 영상 일관성 문제 감소
-
Ablation Study
- L-RoPE의 라벨 범위 변화에 민감하지 않음
Partial Parameter Training이 instruction-following 유지에 효과적임

- L-RoPE의 라벨 범위 변화에 민감하지 않음
5. 결론 및 향후 연구 방향
- 결론
MultiTalk는 다중 오디오 입력과 다중 인물의 자연스러운 대화 영상을 생성할 수 있는 최초의 프레임워크, 정확한 오디오-인물 매핑과 강력한 지시 수행 능력을 보였다. - 의의
영화 제작, 라이브커머스 등 다양한 응용 가능성을 가진 혁신적인 기술 - 한계점
합성 오디오보다 실제 오디오 사용 시 더 나은 성능을 보이며, 합성 오디오와의 성능 격차가 존재 - 향후 연구
- 합성 오디오의 성능 향상 방안 탐색
- 더 긴 영상 생성 및 다양한 인물 수 확장

넓고 얕게? 좁고 깊게?