[논문 읽기] VGGNet: Very Deep Convolutional Networks for Large-Scale Image Recognition(2015)
논문 읽기
목록 보기
10/12
- 분류: Vision Model
- 저자: Karen Simonyan, Andrew Zisserman
- 소속: University of Oxford
- paper: https://arxiv.org/pdf/1409.1556
- 키워드: Classfication, Localization, Transfer Learning
1. 연구 배경
이미지 분류에서는 딥러닝 기반의 합성공 신경망(ConvNets)가 두각을 보임
- ImageNet 같은 대규모 데이터셋에서 증명됨
- 비교적 얕은 구조
본 논문에서는 모델의 깊이(depth)가 인식 성능에 미치는 영향 분석
2. 핵심 아이디어 및 방법론
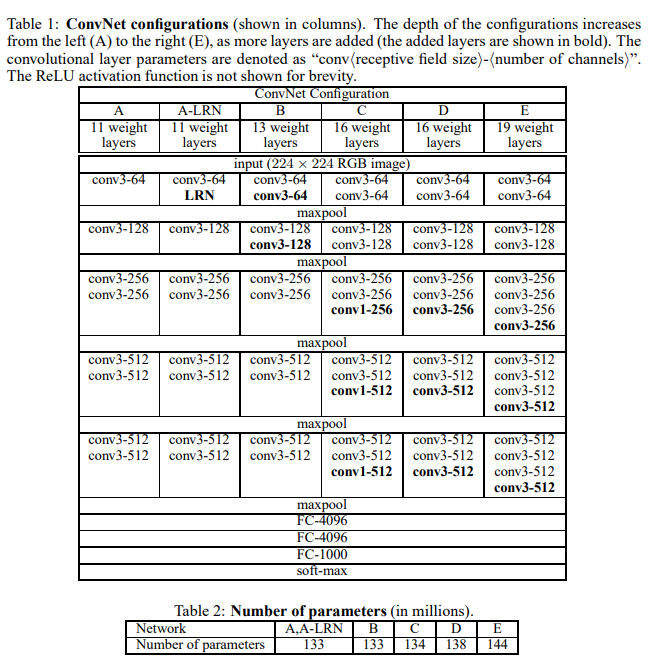
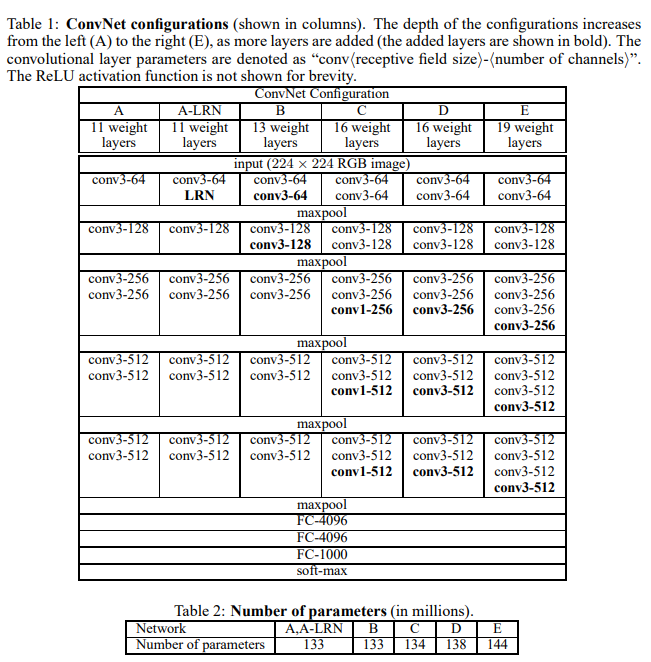
- 작고 일관된 3x3 필터 사용, 네트워크 깊이를 16 ~19개 층으로 증가시키기
- 비선형성: 1x1 필터도 일부 구성에 사용
- 표현력 강화: 1) 파라미터 수 줄이기(필터 크기를 작게 유지) 2) 연산 효율성 유지 3) 깊이 증가
- ConvNet 구성을 A ~ E로 분류하여 실험 (A: 11층, E: 19층)
3. 실험 및 핵심 작업
- 데이터셋: ImageNet ILSVRC 2012(1.3M training, 50K validation, 100K test)
- 전처리 및 증강
- 입력 이미지는 224x224로 고정
- 평균 RGB값 제거, 좌우 반전, 색상 조절 등으로 데이터 증강
- Scale jittering() : 다양한 크기의 이미지를 학습에 사용
- 학습 방식
- 미니배치 SGD, 배치 크기 256, 모멘텀 0.9, L2 Weight decay, dropout 적용
- lr 0.01, 성능 정체 시 10배씩 감소
- 기존 얕은 네트워크(A)를 학습 후, 이를 기반으로 깊은 네트워크 초기화
- 테스트 방식
- FC 레이어를 컨볼루션 레이어로 변환, 전체 이미지에 dense evaluation 수행
- 다중 스케일(Q) 테스트, 다중 crop 평가 등 다양한 기법으로 성능 향상
4. 결과 및 분석
- 깊이가 증가함에 따라 성능 향상, 19층 구성(E)이 최고 성능 달성
- 단일 네트워크 기준: 7.0% (E 모델, multi-crop & dense)
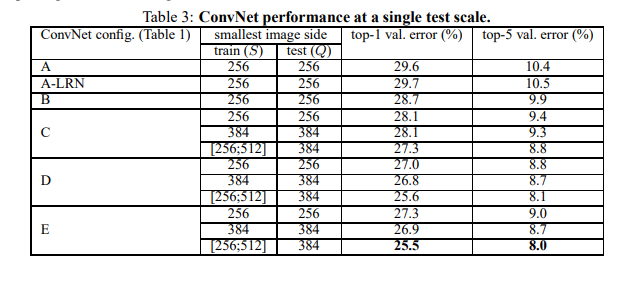
- 앙상블 구성(D+E)
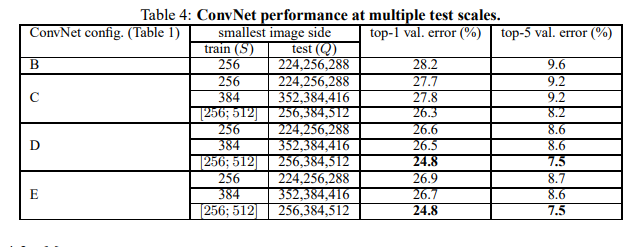
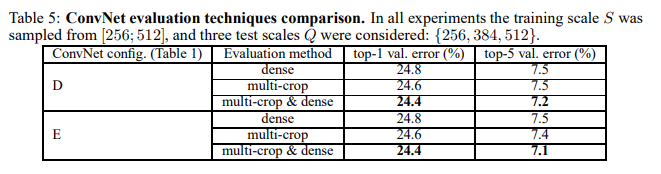
- 기존 모델(Krizhevsk, Zeiler 등) 대비 큰 폭의 성능 향상
- 다른 네트워크(GoogLeNet 등)보다 구조는 단순, 성능은 경쟁력 이음
5. 결론 및 향후 연구 방향
의의
- 기존 ConvNet 구조를 유지하면서 단순히 깊이를 증가시키는 것만으로도 성능 향상 가능함 입증
- 복잡한 구성 없이도 학습 가능
- ImageNet 외 다양한 데이터셋(VOC, Caltech)에서도 우수한 전이 성능
한계 및 향후 방향
- 계산 비용 및 학습 시간 증가(단일 네트워크 학습에 2~3주 소요)
- 이후 연구에서는 효율성 및 구조적 혁신(ResNet, DenseNet 등)이 주요한 과제로 이어짐
(+) 부록
Localization: 객체 위치 추정
Localization ConvNet
- 목표: ILSVRC의 localization track은 이미지마다 객체 클래스 + 객체 위치를 예측하는 과제
- 방법: 기존 Classification ConvNet에서 마지막 FC layer를 bbox regression layer로 교체
- bounding box: [center_x, center_y, width, height]
- Regression 방식
- SCR(Single-Class Regression): 클래스 무관하게 bbox 예측 (4차원)
- PCR(Per-Class Regression): 클래스마다 bbox 예측 (1000 classes -> 4000차원)
- 사용 네트워크: VGG-D(16층)
- 학습 방식
- Loss: L2 loss
- Pretraining된 classification 모델을 fine-tuning
- 두 가지 실험
- FC 레이어만 fine-tuning
- 전체 레이어 fine-tuning
- 테스트 방식
- 간단: center crop 하나만 사용 + ground-truth 클래스만 대상으로 bbox 예측
- 완전: 이미지 전체에 dense하게 localization network 적용 + 다수 bbox 예측 -> greedy merging
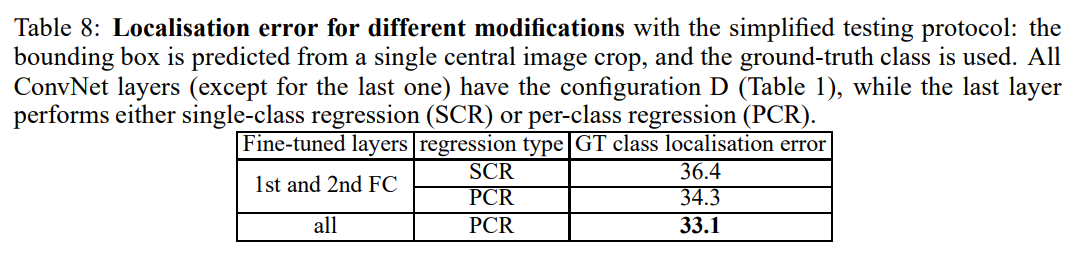
Localization 실혐 결과
- fine-tuning 전체 레이어 + PCR이 가장 높은 성능을 보임

Generalisation: 전이 학습 성능
VGGNet이 ImageNet 외 다양한 데이터셋에서 고정된 feature extractor로 얼마나 잘 작동하는지 실험
실험 방식
- FC7(4096 차원) 출력 벡터를 feature로 사용
- 다양한 이미지 크기(Q)에서 dense하게 feature 추출 -> average pooling
- RGB 이미지 + 좌우 반전
- 여러 scale(Q) 사용해 multi-scale feature 생성 -> average or stacking
- classifier: linear SVM
결과
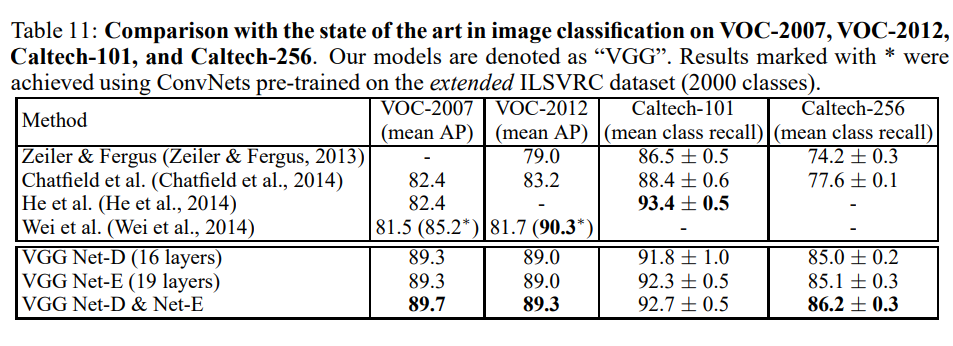
시사점
- VGGNet은 사전 학습만으로도 강력한 범용 feature extractor 역할을 함
- 단순한 linear classifier만으로도 SOTA 수준 결과 달성
- 추후 다양한 task에서 VGGNet이 널리 사용되는 기반이 됨

넓고 얕게? 좁고 깊게?