✔️ 관계 데이터 모델의 개념
수학의 집합 이론이 근거 → 타 모델 이론적 토대가 탄탄
SQL 언어는 비절차적 언어로 원하는 데이터를 원하는 때에 쉽게 표현할 수 있는 장점 !

도서의 도서번호 -> PK(기본키)
주문의 도서번호 -> FK(외래키)
고객의 고객번호 -> PK(기본키)
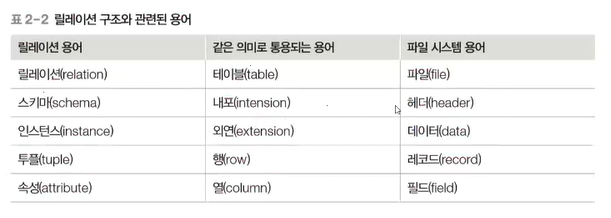
✔️ 릴레이션 스키마와 인스턴스
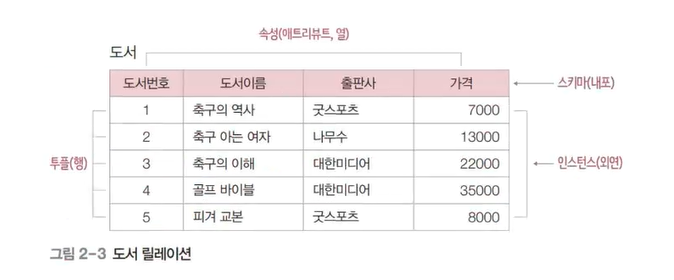
스키마 : 관계 데이터 베이스의 릴레이션이 어떻게 구성되는지 정보를 담고 있는지에 대한 기본 구조를 정의
인스턴스 : 정의된 스키마에 따라 테이블에 실제로 저장되는 데이터의 집합

🔹 릴레이션 스키마
- 속성 : 릴레이션 스키마의 열
- 도메인 : 속성이 가질 수 있는 값의 집합
- 차수 : 속성의 개수
- 열이름 : 스키마
- 도메인 -> 자료형과 유사하다! ex) 도서이름의 도메인 : char
✔️ 릴레이션 인스턴스
튜플(tuple) : 릴레이션의 행
카디널리티(cardinality) : 튜플의 수 -> 튜플의 삽입 삭제 수정에 따라 수시로 변경
-> 튜플이 가지는 속성의 개수는 릴레이션 스키마의 차수와 동일하고, 릴레이션 내의 모든 튜플들은 서로 중복되지 않아야 함!
✔️ 릴레이션의 특징
- 속성은 단일 값을 가진다
각 속성의 값은 도메인에 정의된 값만을 가지며 그 값은 모두 단일 값이어야 함.
- 속성은 서로 다른 이름을 가진다.
속성은 한 릴레이션에서 서로 다른 이름을 가져야 함.
- 한 속성의 값은 모두 같은 도메인 값을 가진다.
한 속성에 속한 열은 모두 그 속성에서 정의한 도메인 값만 가질 수 있음.
- 속성의 순서는 상관없다.
속성의 순서가 달라도 릴레이션 스키마는 같음.
ex) 릴레이션 스키마에서 (이름, 주소) 순으로 속성을 표시하거나(주소, 이름)순으로 표시하여도 상관없음.
- 릴레이션 내의 중복된 투플은 허용하지 않는다.
하나의 릴레이션 인스턴스 내에서는 서로 중복된 값을 가질 수 없음. 즉 모든 튜플은 서로 값이 달라야 함.
- 튜플의 순서는 상관없다.
튜플의 순서가 달라도 같은 릴레이션임. 관계 데이터 모델의 실제적인 값을 가지고 있으며 이 값은 시간이 지남에 따라 데이터의 삭제, 수정, 삽입에 따라 순서가 바뀔 수 있음.
✔️ 관계 데이터 모델

관계 데이터 모델을 컴퓨터 시스템에 구현 -> 관계 데이터 베이스 시스템
관계 데이터베이스 시스템은 SQL 기반으로 표(릴레이션)생성, 구현/ 데이터추출, 연산 되고 있다.
✔️ 관계대수
릴레이션에서 원하는 결과를 얻기 위해 수학의 대수와 같은 연산을 이용하여 질의하는 방법을 기술하는 언어
- 관계대수와 관계해석
관계대수 : 어떤 데이터를 어떻게 찾는지에 대한 처리 절차를 명시하는 절차적인 언어이며 DBMS 내부의 처리 언어로 사용됨
관계해석 : 어떤 데이터를 찾는지 명시하는 선언적인 언어로 관계대수와 함께 관계 DBMS의 표준 언어인 SQL의 이론적인 기바능ㄹ 제공함
-> 관계대수와 관계해석은 모두 관계 데이터 모델의 중요한 언어이며 실제 동일한 표현 능력을 가지고 있음.
✔️ 관계의 수학적 의미

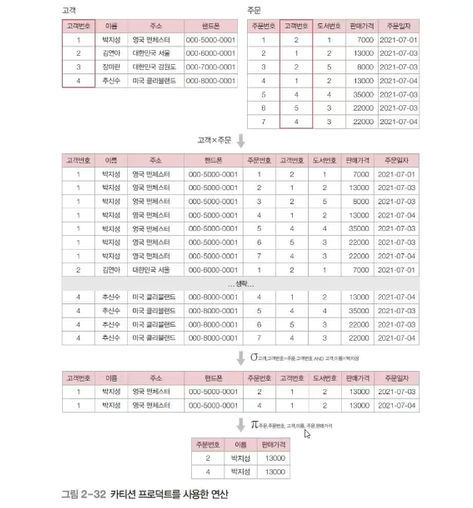
카티전 프로덕트 : 두개 이상의 집합을 조합하여 생성 가능한 집합을 만드는 연산
ex) 2의 (2x3)승 ! = 64

✔️ 관계대수 연산자
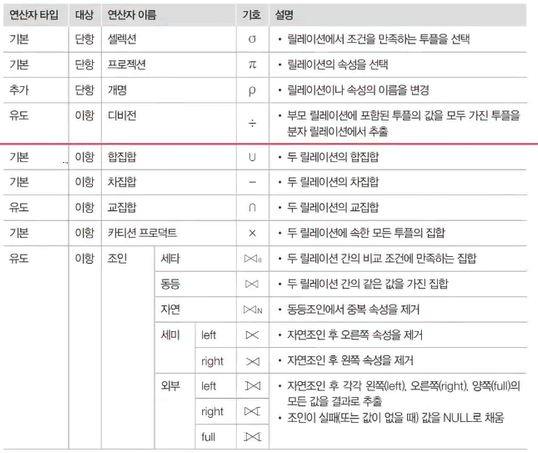
윗 부분 순수관계 연산 : 관계 데이터 모델을 위해 고안
아랫 부분 일반 집합 연산 : 수학 집합(set)에 존재하는, 기존의 연산 기호
✔️ 관계대수식
관계대수는 릴레이션 간 연산을 통해 결과 릴레이션을 찾는 절차를 기술한 언어로, 이 연산을 수행하기 위한 식을 관계대수식이라고 한다!
관계대수식은 대상이 되는 릴레이션과 연산자로 구성되며, 결과는 릴레이션으로 반환된다. 반환된 릴레이션은 릴레이션의 모든 특징을 따른다.
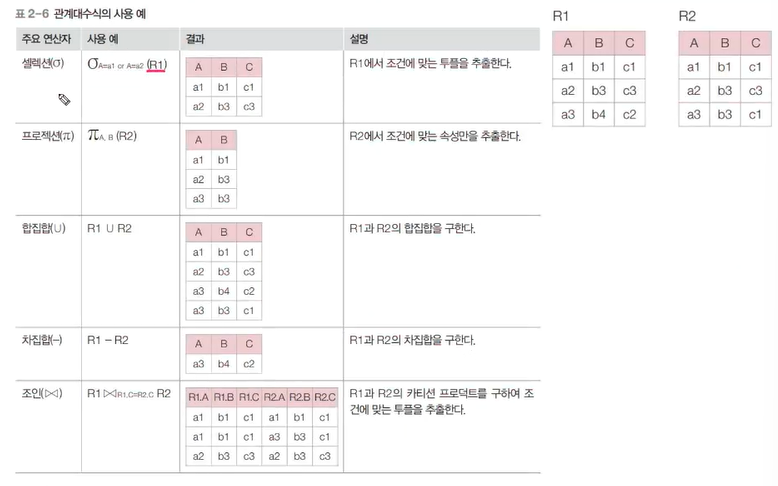
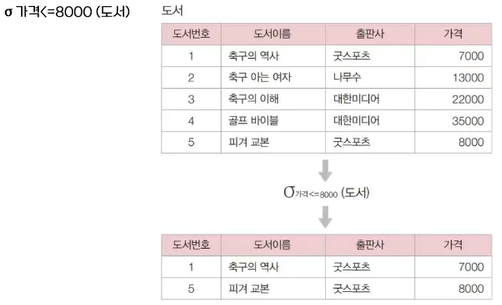
✔️ 셀렉션(selection)
-> 튜플 추출
- 릴레이션의 튜플을 추출하기 위한 연산임. 하나의 릴레이션을 대상으로 하는 단항 연산자이며, 찾고자 하는 튜플의 조건(predicate)을 명시하고 그 조건에 만족하는 튜플을 반환함.
마당서점에서 판매하는 도서 중 8,000원 이하인 도서를 검색

✔️ 프로젝션(projection)
-> 열을 추출
- 릴레이션의 속성을 추출하기 위한 연산으로 단항 연산자임.
신간도서 안내를 위해 고객의(이름, 주소, 핸드폰)이 적힌 카탈로그 주소록

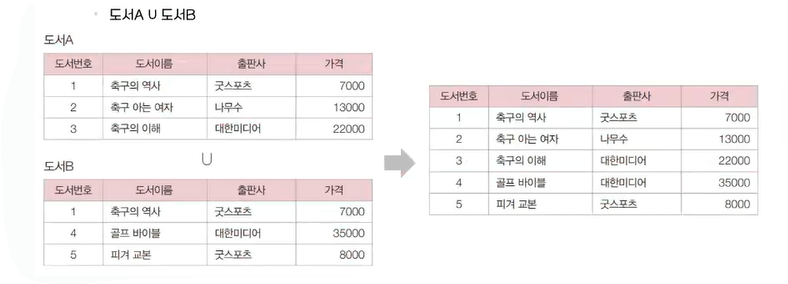
✔️ 합집합
- 두 개의 릴레이션을 합쳐서 하나의 릴레이션을 반환함. 이 때 두 개의 릴레이션은 서로 같은 속성 순서와 도메인을 가져야 함.
마당서점은 지점A와 지점B가 있다. 두 지점의 도서는 각 지점에서 관리하며 릴레이션 이름은 각각 도서A, 도서B다. 마당서점의 도서를 하나의 릴레이션으로 보이면!
✔️ 교집합
- 합병가능한 두 릴레이션을 대상으로 하며, 두 릴레이션이 공통으로 가지고 있는 튜플을 반환함.
형식


✔️ 차집합
- 첫 번째 릴레이션에는 속하고 두 번째 릴레이션에는 속하지 않은 튜플을 반환함

✔️ 카티션 프로덕트(cartesian product)
- 두 릴레이션을 연결시켜 하나로 합칠 때 사용함. 결과 릴레이션은 첫 번째 릴레이션의 오른쪽에 두 번째 릴레이션의 모든 튜플을 순서대로 배열하여 반환함.
결과 릴레이션의 차수는 두 릴레이션의 차수의 랍이며, 카디날리티는 두 릴레이션의 카디날리티의 곱임.

✔️ 조인(join)
- 두 릴레이션의 공통 속성을 기준으로 속성 값이 같은 튜플을 수평으로 결합하는 연산임. 조인을 수행하기 위해서는 두 릴레이션의 조인에 참여하는 속성이 서로 동일한 도메인으로 구성되어야 함. 조인 연산의 결과는 공통 속성의 속성 값이 동일한 튜플만을 반환함.

✔️ 디비전(division)
- 릴레이션의 속성 값의 집합으로 연산을 수행함.

✔️ 관계대수 사용 예제