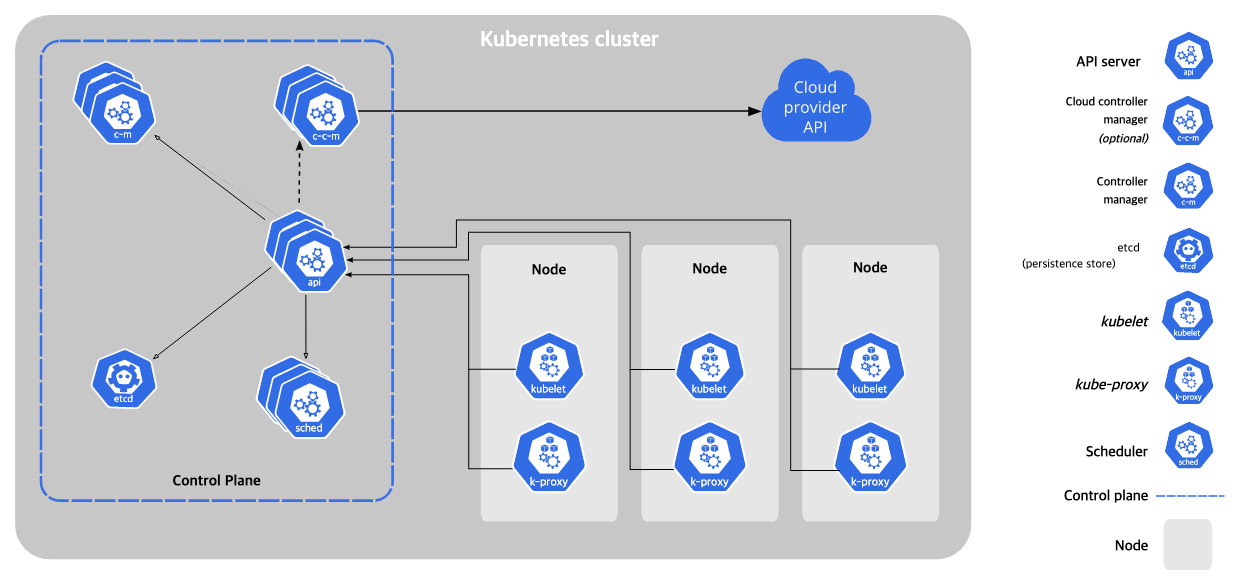
쿠버네티스 클러스터의 구성요소

쿠버네티스 클러스터는 컨트롤 플레인(마스터 노드)과 컴퓨팅 머신(워커 노드) 두 개의 부분으로 구분할 수 있다. 노드는 자체 리눅스 환경을 가진 물리 혹은 가상머신 자체로 k8s의 물리적인 단위이다. (이와 비교하여 쿠버네티스의 논리적인 단위에는 pod, service 등이 있을 것이다)
쿠버네티스 컨트롤 플레인
컨트롤 플레인은 k8s클러스터를 제어하는 중추 역할을 한다. 컨트롤 플레인은 노드와 연결되어 있으며 서로 통신한다. (어떻게 통신하는지는 이어서 다룬다)
아래에 설명된 컴포넌트들은 기본적으로 도커 컨테이너로서 실행되고 있으므로, 마스터 노드에 ssh로 접속해 docker ps 명령어를 실행해 보면 실제로 확인할 수 있다.
kube-apiserver
apiserver 라는 이름 그대로 k8s클러스터와 사용자와의 접점 역할을 한다. 쿠버네티스는 클러스터의 제어를 위한 기능들을 rest api로 제공하는데, 쿠버네티스 api를 직접 호출하거나 kubectl cli를 통해서 클러스터에 요청을 보낼 때 얘가 받는다.
kube-scheduler
보통 스케줄러라는 이름이 붙은 애들은 job들을 예약하고 실행시키는 역할을 하는데 얘도 비슷한 것 같다. k8s에서 추상화된 리소스들의 요구사항이 있을 것 같은데, (어떤 파드는 ~만큼의 cpu와 메모리가 필요하다든가) 클러스터의 상태를 체크하며 파드를 적절한 노드에 예약하는 역할을 한다.
kube-controller-manager
k8s에는 다양한 기능을 하는 컨트롤러가 있다. (스케줄러를 보고 적절한 수의 파드를 실행시키거나, 파드에 문제가 생겼을 때 감지하고 대응하고, 요청을 적절한 엔드포인트로 이동시키거나) (Replica controller, Service controller, Volume Controller, Node controller 등) 컨트롤러 매니저는 이러한 여러 컨트롤러 기능이 하나로 통합되어 있다.
etcd
분산 key-value 저장소로, 설정과 관련된 데이터나 클러스터의 상태 관련 정보가 저장된다.
노드
노드란?
= 쿠버네티스의 파드가 실행되는 가상 또는 물리머신.(ex. minikube 환경에서는 로컬에 설치된 하나의 가상머신, eks 에서는 ec2 인스턴스)
= 워커 노드 (cf. 마스터 노드, 컨트롤 플레인)
= kubelet + 컨테이너 런타임 + kube-proxy
- kubelet : 노드가 컨트롤 플레인과 통신하기 위한 매우 작은 어플리케이션
- 컨테이너 런타임 : 파드 통해 배포된 컨테이너가 돌아가는 환경
- Kube-proxy : 클러스터 외부-내부 네트워크 통신 처리하기 위한 k8s 네트워킹 서비스 프록시
status
- 주소 : HostName, ExternalIP, InternalIP
- Condition : Ready, DiskPressure, MemoryPressure, PIDPressure, NetworkUnavailable
heartbeat
클러스터는 개별 노드가 보내는 heartbeat 를 통해 개별 노드가 이용가능한 상태인지 판단, 장애 발경되면 조치를 취한다
노드 컨트롤러의 역할
1. 등록 시점에 노드에 CIDR 블럭을 할당한다
2. 내부 노드 리스트를 최신 상태로 유지한다 (클라우드 vendor 에 노드가 사용가능한지 물어보고 사용 불가능하면 리스트에서 제거...)
3. 노드의 동작 상태를 모니터링
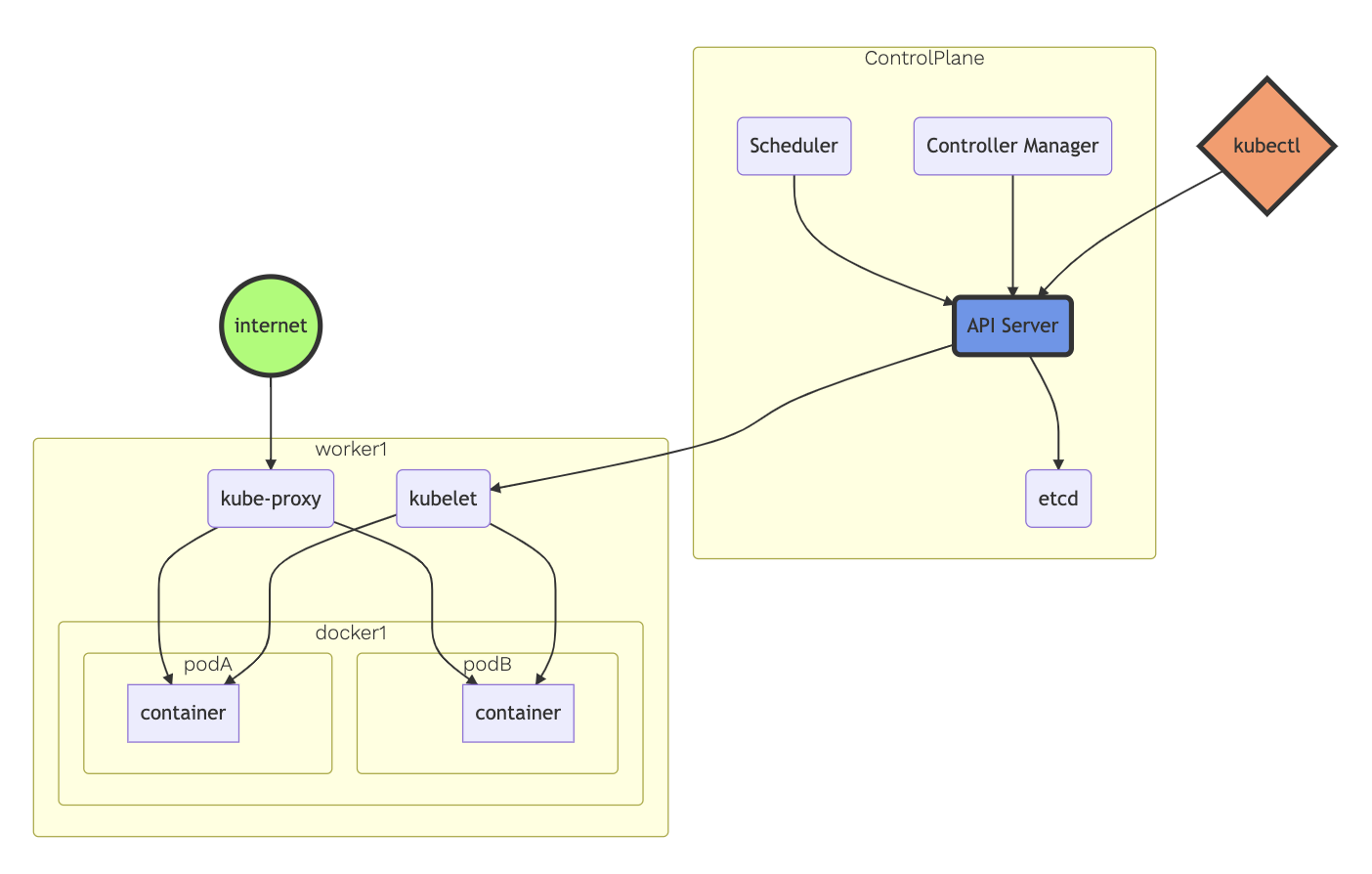
컨트롤 플레인-노드 간 통신
컨트롤 플레인, 주로 kube-apiserver와 k8s의 노드는 서로 통신하며 클러스터를 제어하고, 사용자가 클러스터 외부에서 클러스터를 실행할 수 있도록 네트워크를 구성한다.
노드에서 컨트롤 플레인으로
k8s는 허브 앤 스포크(hub-and-spoke) api 패턴을 가지고 있다.
(이해못함. 나중에 다시 볼 것)
컨트롤 플레인에서 노드로
kube-apiserver에서 kubelet으로의 통신
apiserver에서 각 노드의 kubelet프로세스와 통신하는 경우이다. kubelet의 HTTPS 엔드포인트와 연결이 이루어지며, 다음과 같은 용도로 사용된다.
- 파드의 로그 가져오기
- 실행 중인 파드에 kubectl을 통해 접근해야 할 때
- kubelet의 포트-포워딩 기능을 제공할 때
kube-apiserver에서 노드, 파드 및 서비스로의 통신
apiserver에서 노드, 파드, 및 서비스로의 연결은 HTTP로 이루어지므로 인증되거나 암호화되지 않는다. (안전하지 않다)
컨트롤러
쿠버네티스는 하나의 모놀리틱 컨트롤러가 아닌 작고 간단한 컨트롤러를 여러 개 사용하도록 디자인됨
컨트롤러는 종료되지 않고 계속 돌아가면서 클러스터 상태를 의도한 상태에 맞게 만듦.
ex) job을 생성 > 의도한 상태=job이 완료되는것 > job 컨트롤러가 잡이 생성된 것 확인하고 잡을 완료시키기 위한 작업들을 api 서버로 요청함
클라우드 컨트롤러 매니저

클라우드 컨트롤러 매니저(c-c-m)는 컨트롤 플레인에서 실행됨.
내부 컨트롤러: 노드/라우트/서비스 컨트롤러
