SQL & NoSQL의 등장
데이터를 컴퓨터 내에 보관하기 시작한 이후부터 불가피하게 발생한 여러 문제점들을 보완하다보니 파일시스템이 점차 발전하게 된다.
각각의 문제점들과 보완된 DB방식의 가장 큰 축에 1970년대에 만들어진 SQL과 2000년 이후의 NoSQL 방식이 있다.
File → SQL. file의 문제점들
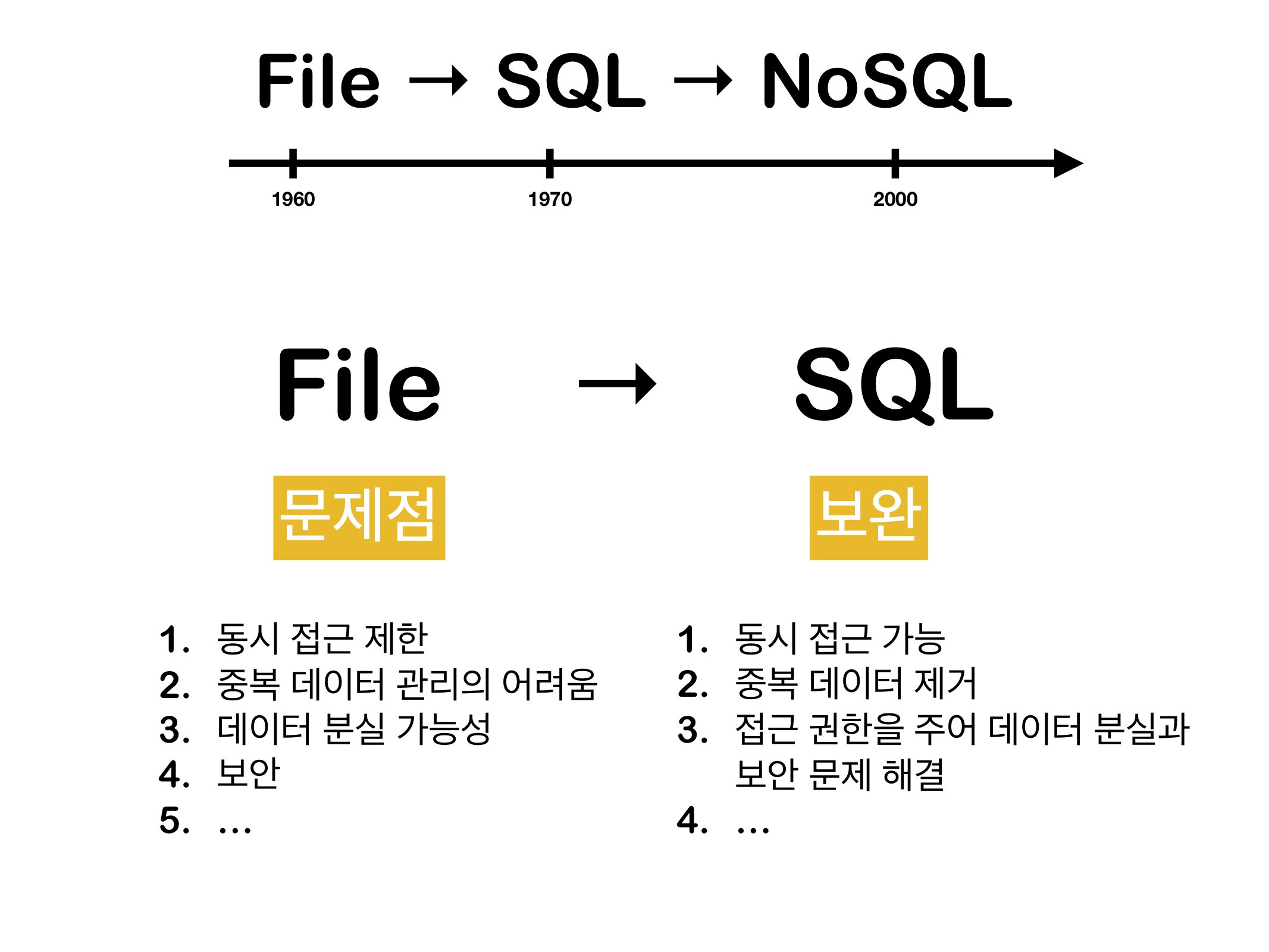
파일 시스템의 문제점
-
파일은 동시 접근이 불가능하다. 예를 들어 내 컴퓨터에서 생성한
index.js파일을 다른 컴퓨터에 보내서 수정을 해도 내 컴퓨터 파일이 자동으로 수정되지 않는다. 똑같은 이름의 똑같이 생긴 파일이라해도 같은 데이터를 참조하지 않기 때문이다. 즉, 파일시스템에서는 여러 사람들이 여러 컴퓨터로 하나의 파일에 동시 접근하는 것이 불가하다. -
중복 데이터 관리가 어렵다. 같은 데이터가 들어간 파일이 몇 백만개가 있다 하더라도 파일 시스템으로는 중복 데이터인지 아닌지 판별하지 못한다.
-
데이터 분실 가능성이 높다. 파일은 위치만 안다면 누구나 접근할 수 있기 때문에 데이터에 관한 보안이 거의 없다고 할 수 있다. 요즘엔 파일에 잠금을 걸어둘 수도 있는 것 같은데 근본적인 해결 방안은 아니지 않을까..?
-
보안이 약하다. 예를 들어 내가 생성한 파일이 여기 저기로 흩어지고 나면 각각 관리하는 것이 어려워진다.
등등.. 의 파일 문제점을 보안하기 위해서 만들어진 것이 SQL database 이다.
SQL이란?
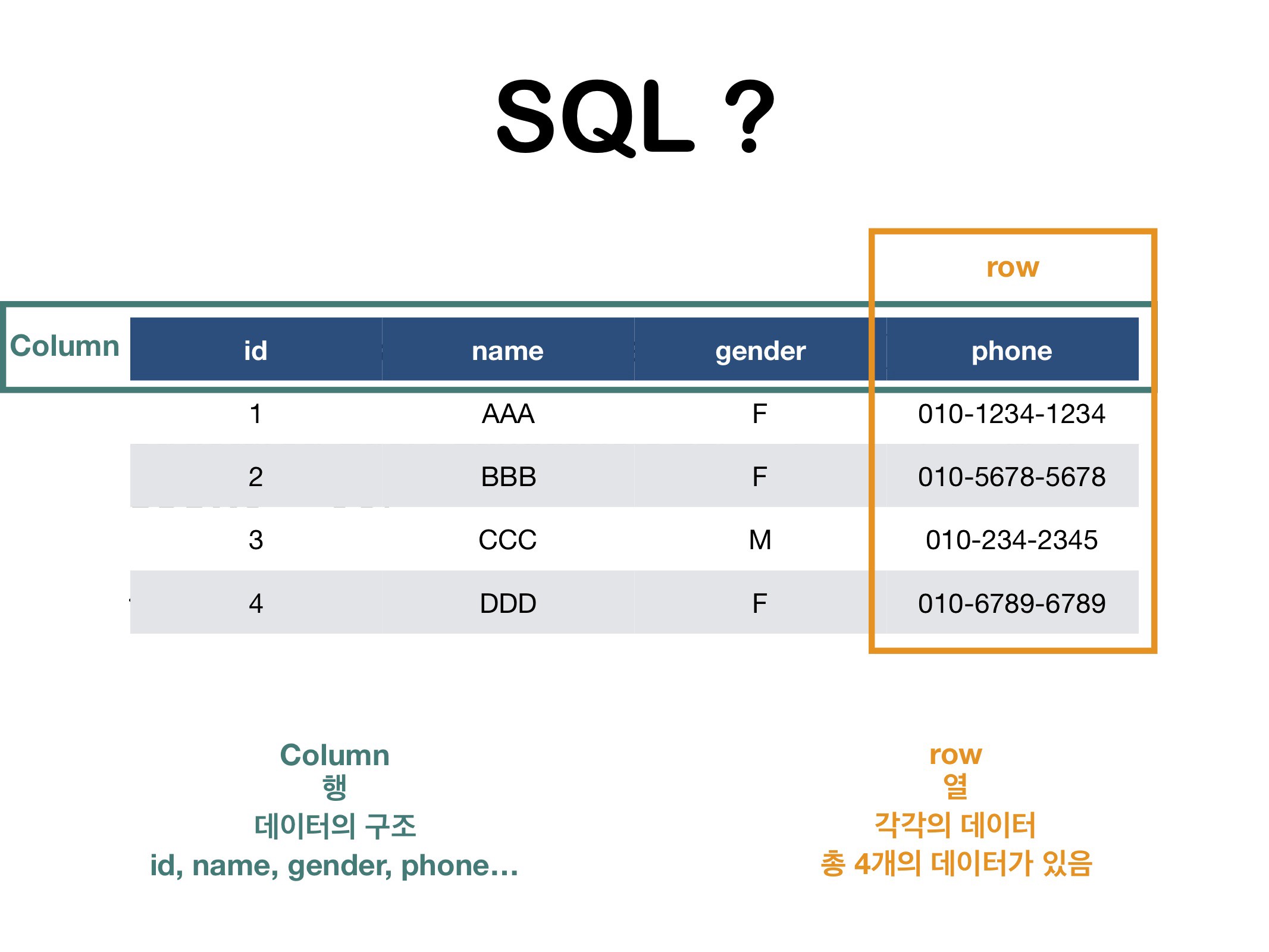
SQL은 Structured Query Language의 줄임말로 직역하자면 ‘구조화된 문의(?) 질의(?) 언어’인데, 여기서 질의란 데이터베이스에 특정 데이터를 요청하는 맥락으로 이해할 수 있다.
더불어 1970년 당시 파일 시스템의 문제를 보완하여 만들어진 여러 데이터베이스들( MySQL, Oracle.. 등)은 SQL을 마치 표준어처럼 사용하고 있기 때문에 익혀두면 여러 프로그램을 큰 어려움없이 사용할 수 있다.
SQL → NoSQL. SQL의 문제점
그러나 시간이 흘러 2000년대에 접어들며 웹 사용이 급증하게 되자 SQL의 또다른 문제점들이 발생하게 된다.
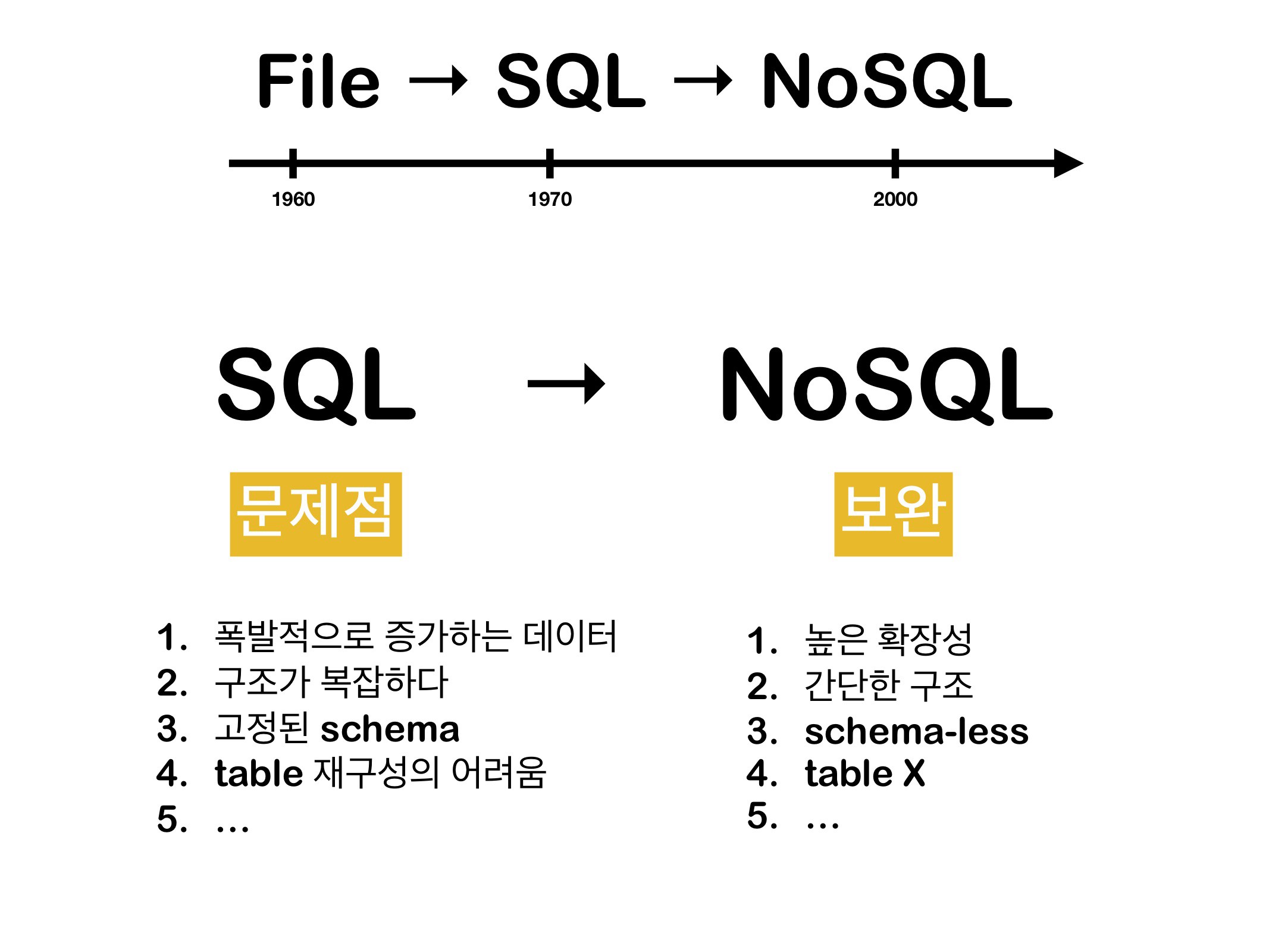
SQL의 문제점
-
데이터 분산이 불가하다. 정확히 어떤 방식으로 흘러가지는지 잘 모르겠지만 SQL은 여러 저장공간으로 데이터를 분산하는 것이 불가하다. 따라서 2000년대 웹이 크게 발전하며 데이터 양이 폭발적으로 증가하는 것을 감당하기 어려웠다.
-
고정된 스키마로 인해 테이블 재구성이 어렵고 구조가 복잡하다. 필요한 정보가 생겨서 테이블 column에 추가 구성을 해야 한다고 할 때 이전의 모든 정보들에도 영향을 미치게 된다. 한번 짜놓은 테이블을 변경하는 것이 매우 어렵기 때문에 데이터 구조가 자주 변한다면 sql 사용이 불편하다.
이러한 SQL의 문제점을 보완하여 등장한 것이 NoSQL이다.
NoSQL이란?

SQL이 아닌 데이터베이스를 통칭하는 단어로 가장 큰 특징으로는 데이터 분산 저장과 정해진 스키마가 없다는 점이다.
다시 말해 데이터의 양이 많아지면 저장공간을 하나 더 만들어서 분산할 수 있어 폭발적으로 증가하는 데이터를 다룰 수 있고, SQL처럼 테이블 구조를 정하고 저장하는 것이 아니므로 때에 따라 구조를 바꿔 데이터를 추가할 수 있는 구조를 가진다.
공통점과 차이점
공통점
SQL과 NoSQL의 공통점은 모두 데이터 저장을 목적으로 하고 있다는 점이다. NoSQL이 SQL의 문제점이 발생한 이후 등장하긴 했지만 그렇다고해서 더 좋은 성능을 가지고 있는 것만은 아니다. 실제로 현재까지 SQL의 사용량이 훨씬 더 높기도 하다.
자료를 찾아보며 계속해서 SQL과 NoSQL이 경쟁 상대가 아니라 각각의 부족한 부분들을 조금씩 보완한 버전 같다는 느낌을 받았다.
앞으로 말할 두 가지의 차이점이 주는 장단점이 꽤나 다르기 때문에 다뤄야 할 데이터가 어떤 구조이며 어떤 방식으로 자주 사용되는지에 따라 가장 효과적으로 사용할 수 있는 방법을 선택할 수 있는 두 가지 옵션이라고 보면 된다.
차이점
 geeksforgeeks 중..
geeksforgeeks 중..
1. 관계형인가?
관계형 데이터베이스는 특정 데이터의 제거가 다른 데이터에 영향을 주는지의 여부로 확인 할 수있다.
예를 들어 카페에서 커피 주문이 들어오는 것을 SQL과 NoSQL 방식으로 정리하면 아래와 같이 만들 수 있다.
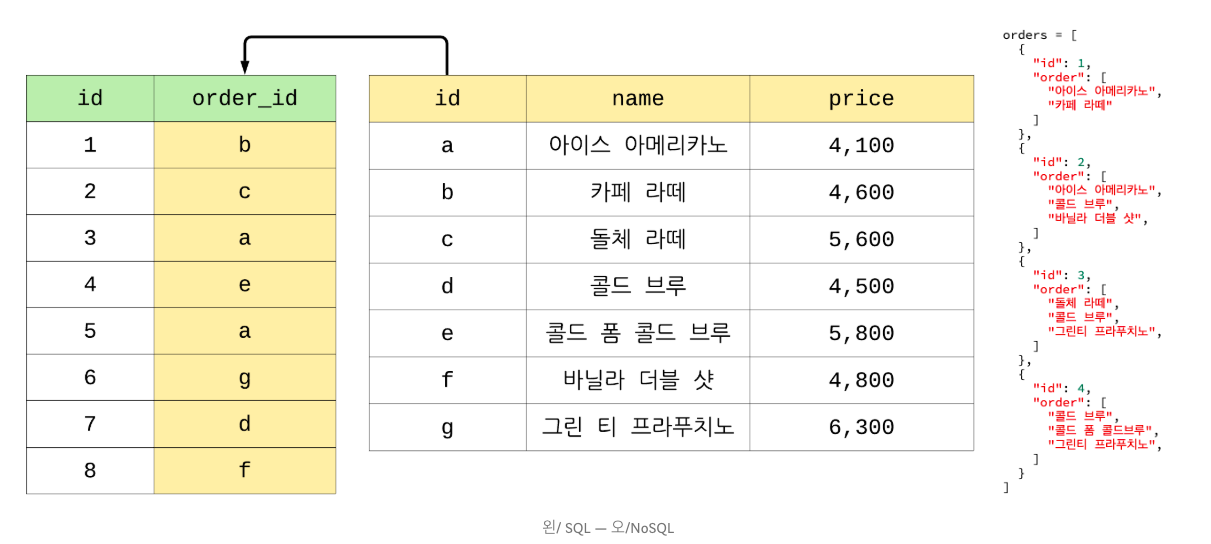
위의 데이터에서 특정 데이터를 제거한다면 아래와 같은 모습이 된다.
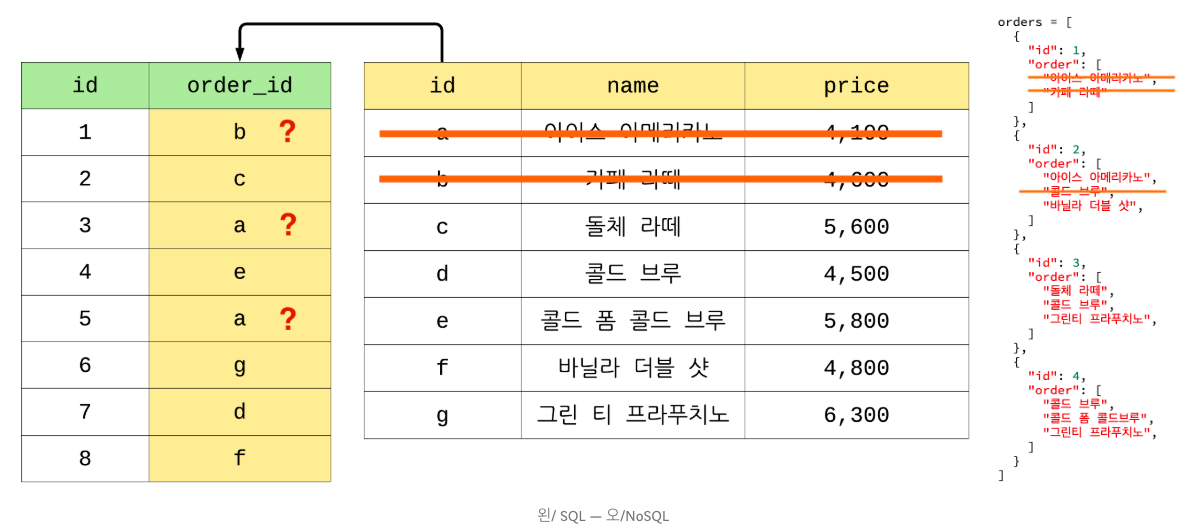
SQL은 애초에 파일 시스템의 중복 문제점을 해결하고자 했기 때문에 데이터 정규화를 통해 중복 데이터를 제거한다. order table과 menu table을 따로 만들어 id 값으로 참조하는 것이다. 다시 말해, 참조하는 데이터들끼리의 ‘관계'를 형성되는 것이다.
이와 달리 NoSQL은 각각의 데이터들이 다른 데이터와 관계없이 개별적으로 추가되므로 특정 데이터가 제거되어도 전혀 관계가 없다. 중복 데이터가 발생하긴 하나 각각 필요한 정보를 원하는 구조로 원하는만큼 넣을 수 있다 데이터 저장의 편리함이 있다.
SQL은 중복 데이터를 제거할 수 있지만 데이터가 커지거나 참조 값이 많아지면 구조가 복잡해질 수 있다.
NoSQL은 중복 데이터를 허용하긴하나 개별적으로 추가되는 데이터들이기 때문에 각각 필요한 정보들만 원하는 구조로 추가할 수 있다는 편리함이 있다.2. 정해진 스키마가 있는가?
정해진 스키마가 있는지는 구조에 없는 값을 포함한 데이터를 추가 가능 여부로 판별할 수 있다.
위의 예시를 계속해서 사용하여 주문 데이터에 “toGo”와 “customer” 정보를 추가한다면 어떻게 될까?
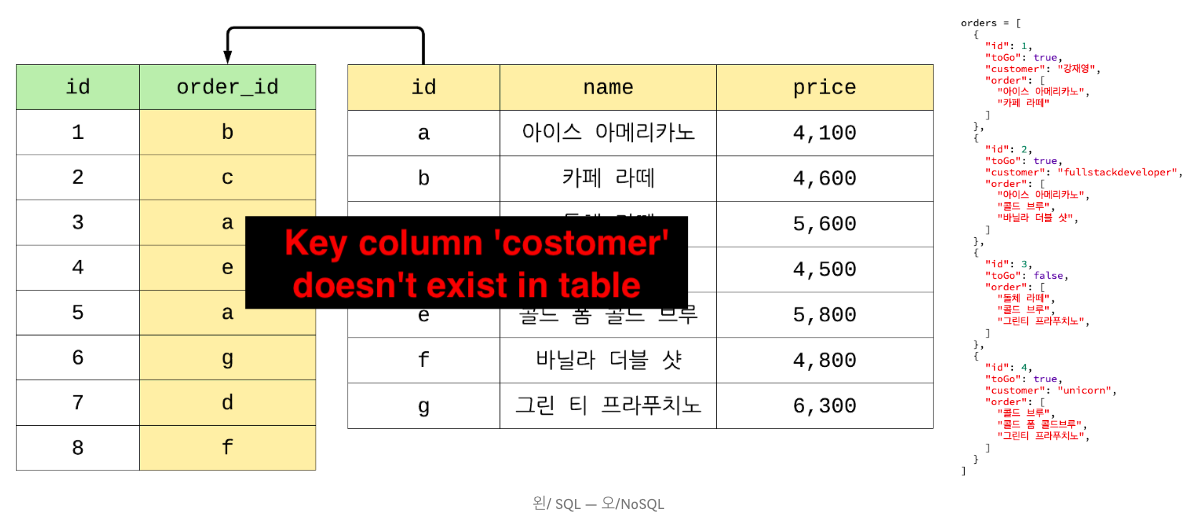
SQL은 데이터 구조 column에 설정되지 않은 값들을 저장하려고 할때 위와 같은 에러 메세지가 뜬다. 즉 구조에 없는 값들을 추가되지 않는다.
이와 달리 NoSQL은 애초에 정해놓은 값 Shema가 없기 때문에 마치 JSON파일처럼 구조를 직접 설계하여 추가하는 것이 가능하다.
SQL은 테이블 형성시 구조에 해당되지 않는 값들은 추가하지 않으므로써 원치 않는 데이터를 사전에 거르게 된다. 즉, 정해진 구조의 값만 추가되기 때문에 어느 정도 데이터의 모습을 예측할 수도 있다.
NoSQL은 정해진 구조가 없으므로 데이터 구조가 자주 추가, 삭제, 변경되는 경우 유연하게 적용시킬 수 있다.3. 계층 구조에 적합한가?
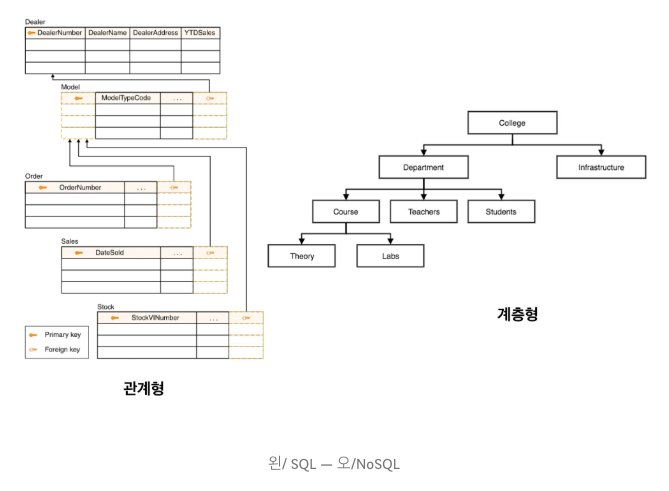
시각 자료만 보면 어떤 것이 계층구조에 적합한지 알 수 있지만 좀 더 나아가면 도대체 왜? 라는 의문이 많이 들어 이 부분은 개인적으로 이해하는 데에 좀 추상적이었다..
현재까지 이해한 것을 바탕으로 예시를 들어보자면
SQL와 NoSQL 로 각각 부서/ 직무/ 이름/ 이메일/ 보고자가 누구인지.. 등의 필요 정보를 가진 사내 조직도를 형성했을 때 아래와 같다.
- SQL 사내 조직도
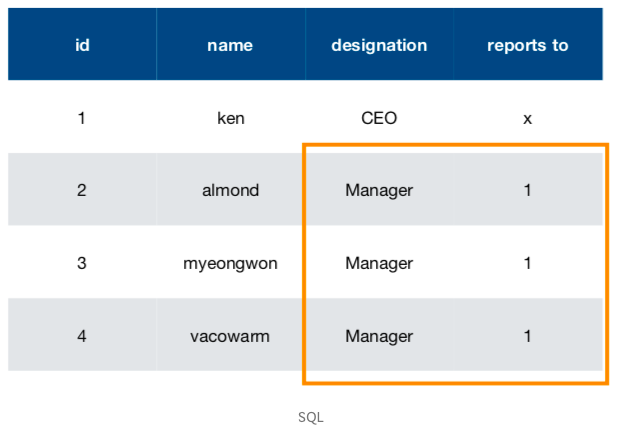
SQL의 경우 구조가 같은 테이블을 만들 필요가 없으니 사장님부터 신입사원까지의 계층구조를 가진 데이터가 모두 같은 테이블에 존재하게 될 것이다.
report to column을 보면 일반적으로 다른 column의 값을 참조할 때 사용되는 foreign key가 들어 있는데, 위의 테이블에서는 그 key값이 가리키는 곳이 같은 테이블에 있는 id값이다.
즉, 같은 테이블 내에서 계층 구조가 형성되어 같은 테이블 값들을 참조하고 있음을 알 수 있다.
- NoSQL 사내 조직도

이와 달리 NoSQL은 위에서도 언급했듯이 관계를 정의하지 않는다. 이는 곧 어떠한 관계도 형성할 수 있다는 뜻이기도 하다. 즉, 계층 구조를 만들고자 한다면 embed 내장 방식으로든, reference 참조 방식으로든 형성할 수 있다는 것이다.
SQL은 같은 데이터 구조를 가진 정보들이 같은 테이블에 추가되므로 같은 테이블 내에서 서로의 값들을 참조하며
계층구조가 형성될 수 있다.
NoSQL은 어떠한 관계도 형성될 수 있으며 원하는 모습으로 구조를 짤 수 있기 때문에 계층구조를 쉽게 형성할 수 있다.
그런데 이는 어디까지나 '계층구조 데이터에 무엇이 더 적합한가?'를 물었을 때 NoSQL이 좀 더 적합하다.고
말할 수 있는 것이고 반드시 계층구조에서는 NoSQL을 사용 해야한다! 라는 뜻은 아니다.4. 복잡한 요청에 적합한가?
SQL은 물론 복잡해지면 쉽지 않겠지만 테이블 구조를 명확히 알 수 있다면 원하는 데이터를 원하는 모양으로 뽑아낼 수 있다.
이와 달리 NoSQL은 embed하여 복잡한 계층구조로 컬렉션이 형성된다면 각각의 데이터 구조가 다르기 때문에 원하는 데이터를 한번에 추출하는 것이 어렵다.
SQL은 정해진 스키마가 있기 때문에 구조를 예측할 수 있다는 점도 복잡한 쿼리를 소화할 수 있게 도와준다.
즉, 여러 데이터를 합쳐서 자주 불러오는 경우에 용이하다.
NoSQL은 다양한 구조로 데이터 저장하는 편리함의 부작용으로 원하는 데이터를 한번에 추출하는 것이 쉽지 않다.
그러나 이 부분도 역시나 '적합성'에 관해 이야기할 때 SQL이 더 낫다고 할 수 있는 것이고
반드시 SQL이 좋다!는 뜻은 아니다. 5. 수직적 구조? 수평적 구조?

SQL은 하나의 저장 공간을 수직적으로 키워서 저장시킨다.
이와 달리 NoSQL을 이전에 언급했듯이 증가하는 데이터를 보완하기 위해 등장한 DB이므로 데이터를 분산시켜 저장시킨다. 즉, 폭발적으로 증가하는 데이터의 양을 계속해서 수용할 수 있는 것이다.
이와 관련하여 인구 증가를 예로 많이 드는데 SQL이 증가하는 인구를 수용하기 위해 하나의 아파트를 계속해서 높이 짓는 것이라면 NoSQL은 여러 개의 아파트를 지어 사람들의 주거 공간을 지속적으로 마련하는 것이라고 볼 수 있다. 즉, 증가하는 데이터를 근본적으로 해결하는 것이 NoSQL.
SQL은 하나의 공간에 데이터를 저장하기 때문에 보안이 철저하여 견고하다.
NoSQL은 데이터를 분산시켜 저장하기 때문에 확장 가능성이 높다. 6. 용어의 차이

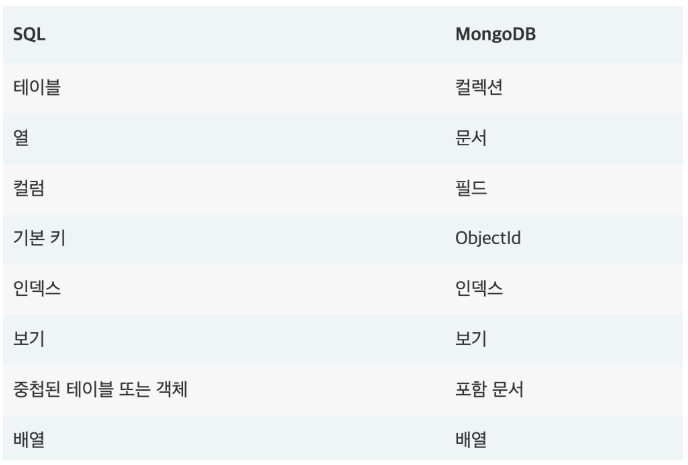
SQL만 있을 때에도 큰 문제없이 데이터 관리를 할 수 있었던 것을 고려해보면 SQL과 NoSQL은 상호 보완 관계에 있다고 할 수 있다.
각 차이점이 서로의 장단점을 보완하고 있기도 하고, 또 서로의 장점들을 사용할 수 있게끔 기능들을 추가하고 있기 때문에 본인이 다뤄야 할 데이터가 사용될 방향을 계획해보고 좀 더 ‘적합한 방식’을 찾는 것이 바람직 한 것 같다는 결론.


오오 차이점을 이해하는데 많이 도움이 되었습니다 감사해요!!!