1. CNN 개념
- CNN 알고리즘
CNN : Convolutional Neural Network
- 컨벌루션 뉴럴 네트워크(CNN 또는 ConvNet)는 모델이 직접 이미지, 비디오, 텍스트 또는 사운드를 분류하는 머신 러닝의 한 유형인 딥러닝에 가장 많이 사용되는 알고리즘.
- 이미지에서 객체, 얼굴, 장면을 인식하기 위한 패턴을 찾는 데 특히 유용 하고 데이터에서 직접 학습 특징 자동 추출
- CNN 특징
- 각 레이어의 입출력 데이터 형상 유지
- 이미지의 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식
3 .복수의 필터로 이미지의 특징 추출 및 학습 - 추출한 이미지의 특징을 모으고 강화하는 Pooling 레이어
- 필터를 공유 파라미터로 사용하기 때문에, 일반 인공 신경망과 비교하여 학습 파라미터가 적음
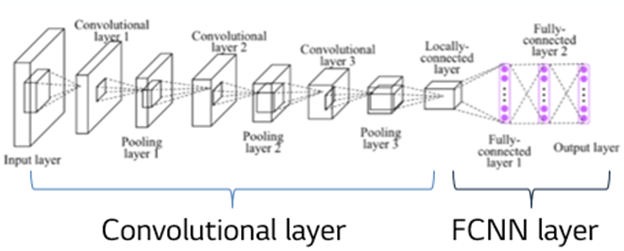
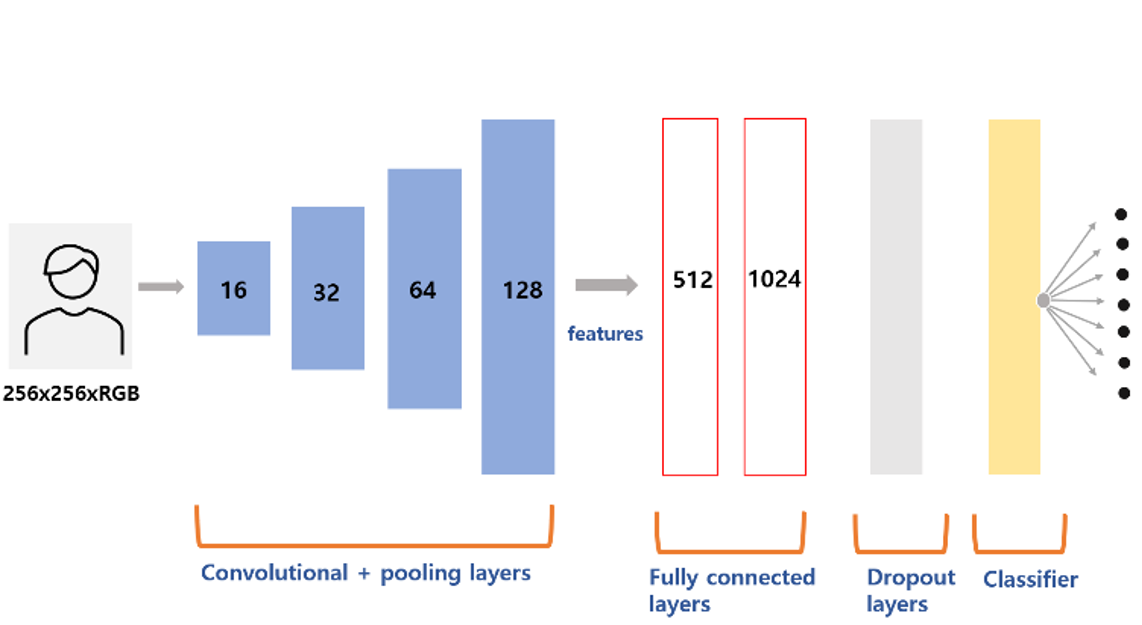
2. CNN 모델
- 구현에 사용한 전체 모델 모습
- 사용 라이브러리
1) 얼굴 분류 및 CNN : Tensorflow
2) 데이터 전처리 및 얼굴 감지 : OpenCV, Keras
- 구체적 구현 내용
1) Convolution layer
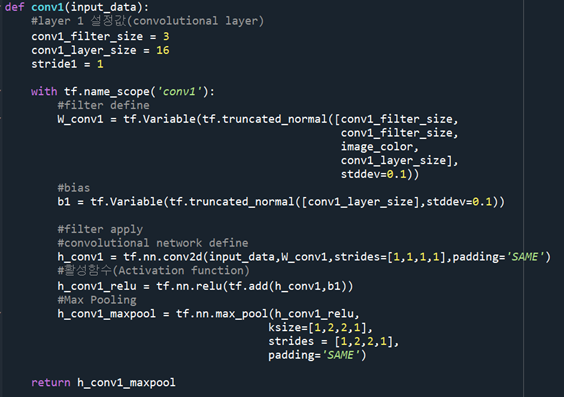
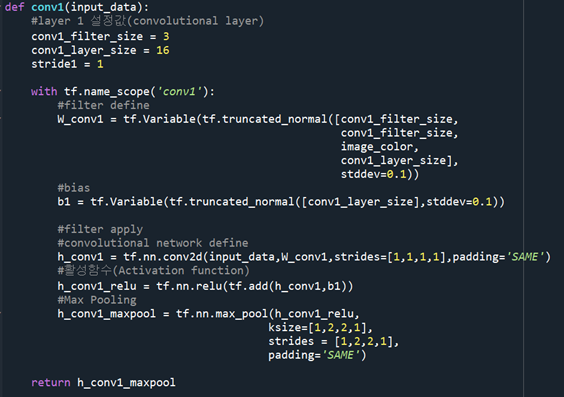
가중치, bias 등을 미리 정한 filter size와 layer size를 통해 설정해줌
활성함수 Relu를 사용하여 필터의 값을 비선형으로 조정해줌..
추출된 특징 activation map을 줄이는 작업을 max pooling 사용. 이는 특징의 값이 큰 값이 다른 특징을 대표한다는 개념을 기반으로 함.
2) Full connected layer
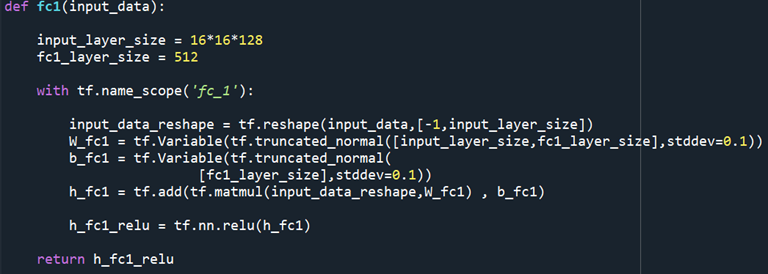
4개의 convolution layer에서 추출된 특징 값을 뉴럴 네트워크 (NN)에 넣어준다
3) Final layer
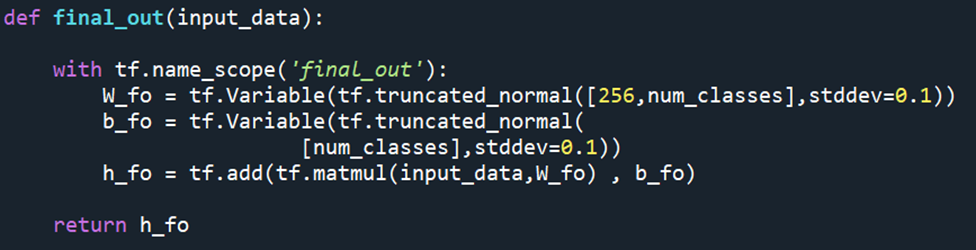
최종으로 drop out까지 시키고 완성되는 final layer
우리팀은 softmax를 이용하여 분류를 실행하였지만 final layer에 포함시키지 않고 main에서 처리해준다
3. CNN 학습
- CNN 학습
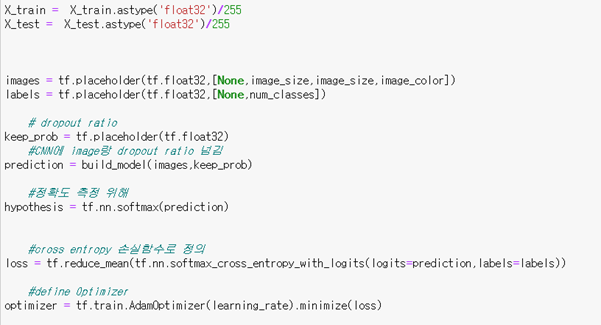
- build_model 함수를 호출하여 images값과 keep_prob값을 넘겨 컨볼루션 네트워크에 값을 넣도록 그래프를 정의하고 그 결과 값을 prediction으로 정의
- softmax cross entropy 함수를 이용해 모델에 의해 예측 된 값 prediction과 , 학습 파일에서 읽어드린 label 값을 비교하여 loss에 저장
- AdamOptimizer를 정의하여 loss 값을 최적화
- CNN학습 코드

- 변수 초기화와 세션을 준비하고, for 루프를 이용하여 총 100 스텝의 학습을 진행
- images와 labels 데이터를 피딩하고 keep_prob를 0.7로 하여 30% 값을 Dropout 진행
- 테스트용 데이터를 피딩하여 , 테스트용 데이터로 학습 모델의 정확도를 검증
- saver.save를 활용하여 학습된 모델을 저장
- 학습을 위한 데이터의 양 늘리기

- 컨볼루션 신경망 모델의 성능을 높이기 위해 이미지 데이터의 양을 증가
- 학습할 만큼의 충분한 양의 데이터를 만들기 위해 사용
- 기존의 이미지를 활용하여 크기, 좌우반전, 색상 등을 조절하여 새로운 이미지를 만드는 방법
- 훈련, 테스트 용 이미지 구분

- 제대로 된 학습 ,테스트를 위해 데이터를 랜덤으로 8:2 비율로 나누는 과정
- 각 카테고리 별로 나눠진 데이터의 순서를 섞어주고 이를 numpy array 타입으로 저장
4. webcam 얼굴 인식
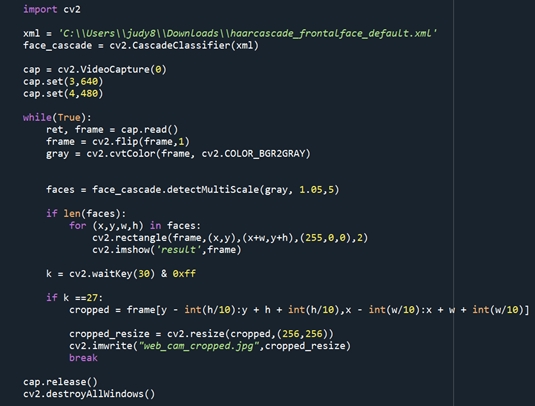
- 웹캠에서 얼굴 부분을 인식하는 것은 opencv사용 ( 얼굴이 누구인지 분류는 CNN사용)
- 웹캠으로 얼굴 부분이 인식되면 esc버튼을 눌러 해당 얼굴 캡쳐, 자동적으로 지정한 이름으로 사진파일 저장됨. 이때 사진의 크기는 cnn모델에 들어가야 하므로 resize함수를 사용하여 256 * 256으로 설정
- detectMultiScale 함수를 통해 얼굴을 검출, 검출된 위치를 (x,y,w,h) 튜플 형식으로 받아와 크롭
-test 부분
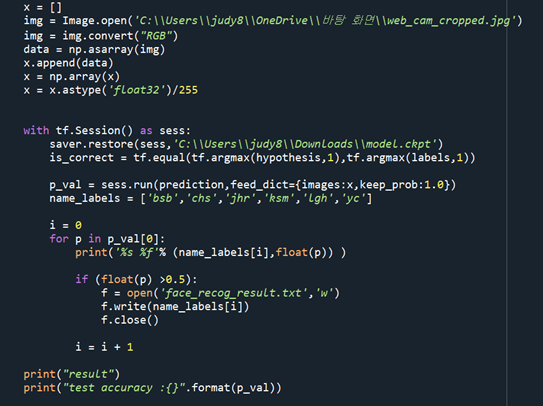
- 웹캠에서 캡쳐한 얼굴 사진을 불러온 뒤, numpy를 사용하여 array 형태로 변경. 타입을 float으로 설정해줌
- 미리 저장해둔 cnn학습 모델을 복구하여, 저장한 사진(웹캠으로 인식된 얼굴)을 input 데이터로 넣어 각 사람들에 대하여 어느정도 일치율을 보이는지 수치로 나타냄
- 그 수치가 0.5 이상일 시 , 해당 라벨의 사람이라고 결정. 그 사람의 이름이 적혀있는 텍스트 파일이 저장됨(이 파일을 자바 프로그램에서 접근하여 활용 예정)

기록용.