
메모리는 CPU만큼 중요한 자원입니다. 메모리가 커지긴 했디만 프로그램의 크기와 처리해야 하는 데이터의 크기가 더욱 빠르게 커져왔습니다. 메모리를 최대한 효율적으로 사용하기 위해 여러 방법들이 연구중이고 운영체제 기능에서도 매우 중요한 위치에 있습니다.
메모리에 프로그램 할당
메모리는 기본적으로 주소(Address)와 데이터(Data)로 구성되어 있습니다.
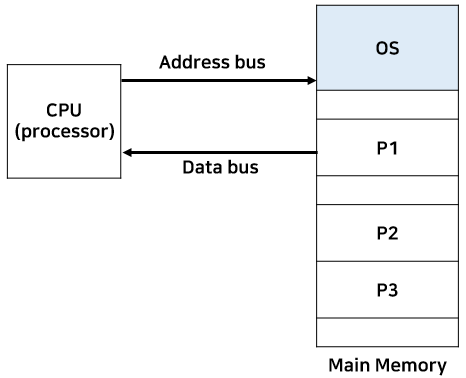
CPU는 주소를 가지고 메인 메모리에 요청을 하거나 해당 주소에 계산 결과를 저장합니다. 메모리는 요구하는 주소에 저장되어 있는 데이터를 CPU에게 전달합니다.
프로그램 빌드
컴퓨터는 근본적으로 0과 1밖에 모릅니다. 사용자들이 작성하는 코드는 거의 대부분 고급언어를 사용하기 때문에 컴퓨터(CPU)가 이해할 수 있도록 번역해주어야합니다.
컴퓨터가 이해하는 언어를 기계어라고 하는데 사용자가 만든 소스 코드를 기계어(Machine Code)로 번역해서 실행 가능한 파일로 만드는 과정을 빌드(Build)라고 합니다.
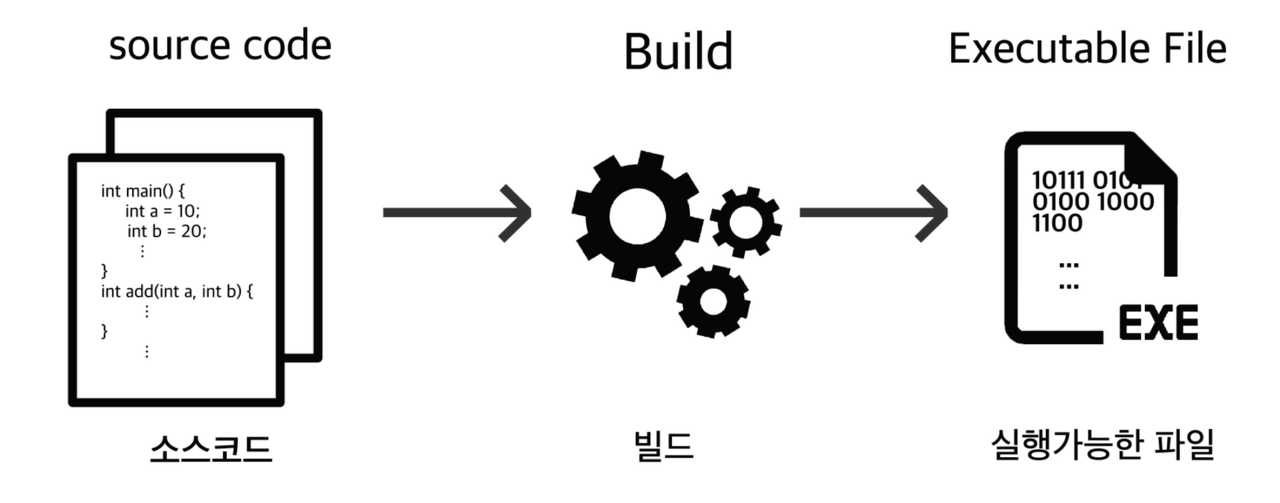
빌드에는 3가지 유형이 있는데 따로 포스팅해서 다루도록 하겠습니다.
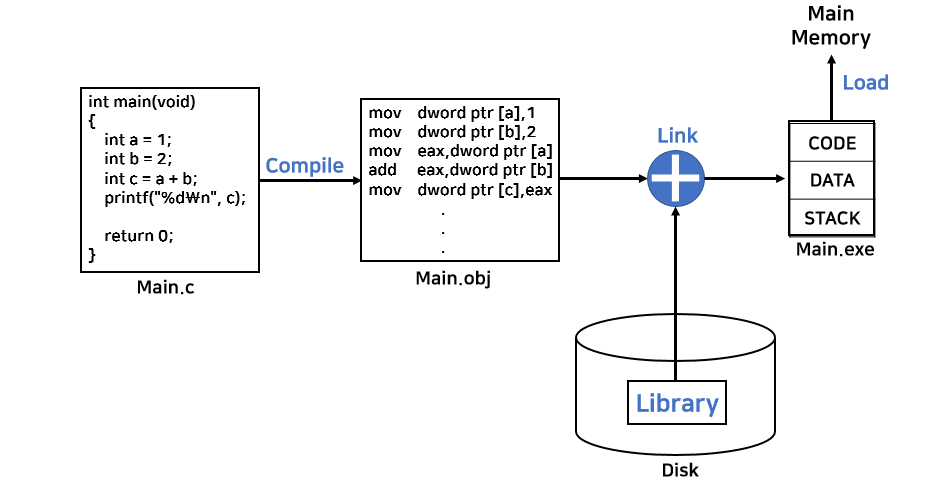
- Compile
소스파일은 컴파일러에 의해 목적 파일을 생성합니다. - Link
링커(Linker)는 디스크에서 프로그래머가 추가한 라이브러리를 찾아 정보를 추가하여 실행 파일을 생성합니다. - Load
실행 파일을 실행하면 프로그램이 로더(Loader)에 의해 메인 메모리에 할당됩니다.
주소 할당
운영체제는 이 프로그램 메모리의 몇 번지에 할당될지 처리해주기 때문에 프로그래머는 메모리에 올라가는 주소를 고려하지 않고 프로그래밍이 가능합니다.
그리고 여러 프로그램이 메모리에 할당되고 해제되고를 반복하는 환경에서는 한 프로그램이 고정적인 공간을 사용할 수 없습니다. 이를 해결해주는 것이 MMU입니다. 프로그램이 메모리에 할당될 때마다 다른 주소공간을 사용하기 때문에 MMU에는 재배치 레지스터(Relocation register)가 별도로 존재합니다.
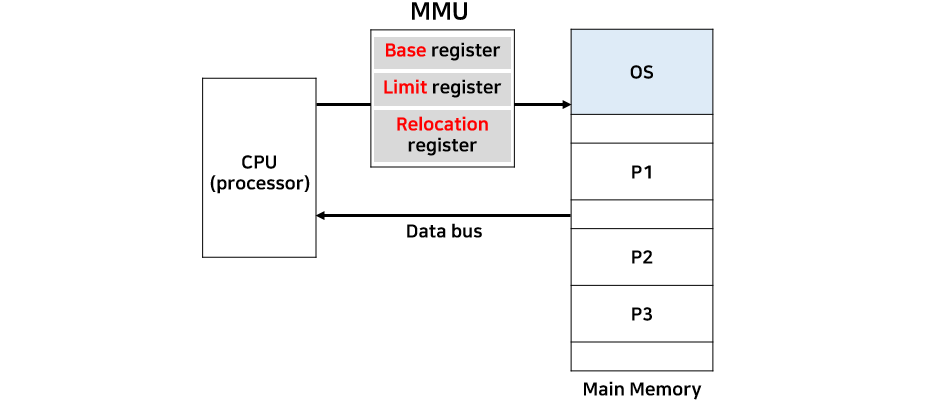
CPU에서 사용하는 주소를 논리적 주소(Logical Address), 메모리가 사용하는 주소를 물리적 주소(Physical Address)라고 합니다.
주소를 할당하는 시점에 따라 분류가 됩니다.
- Compile Time
프로그램의 물리적 주소가 컴파일할 때 결정됩니다. 프로그램이 메모리의 어느 위치에 할당될지 미리 알고 있다면 컴파일러가 절대 주소를 생성합니다. 프로그램 내부에서 사용는 논리적 주소와 물리적 주소가 동일합니다.
주소가 고정되어 있기 때문에 메모리의 빈 공간이 생길 수 있어 비효율적이고 로드하려는 위치에 이미 다른 프로세스가 존재할 수 있습니다. - Load Time
프그램이 메모리의 어느 위치에 할당될지 미리 알 수 없다면 컴파일러는 Relocatble code를 생성해야 합니다. 이 코드는 어느 메모리의 어느 위치에서나 수행될 수 있는 기계 언어 코드입니다. 로더가 프로그램을 메모리에 로드하는 시점에 물리적 주소를 결정합니다.
프로그램 내의 메모리를 참조하는 명령어들이 많아서 이들의 주소를 전부 바꿔줘야하기 때문에 로딩의 시간이 매우 길어질 수 있습니다. - Excution Time (Run time)
프로그램이 실행될 때 메모리 주소를 바꾸는 방법입니다. 실행 도중에 주소가 바뀔 수도 있습니다. 프로그램이 CPU에서 수행되면서 생성해내는 모든 주소값에 base register의 값을 더하여 물리적 주소를 생성하는 방식입니다.
MMU는 CPU가 생성하는 프로그램의 논리적 주소를 메인 메모리의 물리적 주소로 변환합니다. 이 변환이 재배치 레지스터에서 이루어집니다.
MMU의 Limit Register는 논리적 주소의 범위이며, 잘못된 메모리를 참조하지 않도록 막아주는 기능을 합니다. Base Register(Relocation Register)는 접근할 수 있는 물리적 주소의 최솟값을 나타냅니다.
만약 커널 모드인 경우에는 MMU가 물리적 주소로 변환하지 않고 논리적 주소를 그대로 사용합니다. 따라서 커널 모드인지 확인하는 과정도 포함되어 있습니다.
메모리 낭비 방지
동적 적재 (Dynamic Loading)
프로그램이 실행하는 데에 반드시 필요한 루틴/데이터만 로드하는 것입니다. 프로그램의 전체 코드에서 모든 루틴이 다 사용되는 것은 아닙니다. 대표적인 예시가 오류 처리 구문입니다. if문과 같이 오류가 발생할 때만 구문이 실행됩니다. 프프로그램의 실제 메모리에는 이러한 오류 구문을 제외하고 로드합니다. 오류가 발생하면 해당 오류 구문을 찾아 메모리에 올립니다.
데이터도 비슷합니다. 모든 데이터가 반드시 사용되는 것은 아닙니다. 배열과 클래스의 경우, 필요한 부분만 메모리에 올려놓고 실행 도중 필요할 때마다 해당 부분을 찾아 메모리에 올립니다.
반면에 모든 루틴과 데이터를 적재하는 것을 정적 적재(Static Loading)이라고 합니다.
현대 운영체제에서는 대부분 동적 적재를 사용합니다.
동적 연결 (Dynamic Linking)
여러 프로그램에 공통으로 사용되는 라이브러리를 중복으로 메모리에 올리는 것이 아니라 하나만 올리는 것입니다.
같은 라이브러리가 중복으로 메모리에 올라가는 것을 방지하기 위해 프로그램이 메모리에 적재된 후에 링크를 수행합니다.
기존에는 실행 파일이 만들어지기 전에 링크를 수행하였는데 이것을 정적 연결(Static Linking)이라고 합니다.
Swapping
프로세스가 현재 메모리에서 다른 저장공간(Backing Store)으로 옮겨졌다가 돌아오는 것을 의미합니다.
- Swap Out
메모리 -> Backing Store - Swap In
Backing Store -> 메모리
Backing Store
프로그램이 메모리에 적재된 후에 실행되면서 데이터를 추가하거나 변경하는 과정을 거치는데, 이 때 데이터의 상태를 프로세스 이미지라고 합니다. 단순히 하드디스크에 존재하는 프로그램과는 전혀 다른 데이터이기 때문에 따로 저장해야합니다. 이 프로세스 이미지를 저장하기 위한 하드디스크의 일부분을 Backing Store라고 합니다.
Contiguous Memory Allocation
연속 메모리 할당은(Contiguous Memory Allocation) 각 프로세스들이 연속적인 메모리 공간을 차지하게 되는 것을 의미합니다. 각 프로세스를 메모리에 담기 위해 메모리는 미리 공간을 나눠놓게 됩니다. 고정된 크기로 나누는 고정 분할 방식과 프로세스의 크기를 고려해서 나누는 가변 분할 방식이 있습니다.
고정 분할 방식은 분할의 크기가 모두 동일하거나 혹은 다를 수 있습니다. 분할 당 하나의 프로세스가 적재되기 때문에 메모리에 Load되는 프로세수의 수가 고정됩니다. 또한 수행 가능한 프로세스의 최대 크기가 제한됩니다.
가변 분할 방식은 프로세스의 크기를 고려해서 할당하기 때문에 분할의 크기가 개수가 가변적입니다. 이 방식을 위해서는 기술적인 관리 기법이 필요합니다.
연속 메모리 할당에서 메모리를 분할하는 단위는 Block이고 프로세스가 사용할 수 있는 Block을 Hole이라고 합니다. 다양한 크기의 Hole들이 메모리 여러 곳에 흩어져 있고 프로세스가 도착하면 수용 가능한 Hole을 할당시킵니다.
연속 메모리 할당 방식에는 세 가지 방식이 있습니다.
- First-fit
크기가 n 이상인 Hole 중 최초로 발견한 Hole에 할당. - Best-fit
크키가 n 이상인 가장 작은 Hole을 찾아 할당. Hole이 크기 순으로 정렬된 게 아니라면 모든 Hole을 탐색해야할 수 있습니다. - Worst-fit
가장 큰 Hole에 할당. 결국 모든 Hole을 탐색해야 합니다.
속도 측면에서는 First-fit이 가장 좋은 효율을 냅니다. 메모리 이용률 측면에서는 Worst-fit에 비해 First-fit과 Best-fit이 비슷하게 좋은 효율을 낸다고 알려져 있습니다. 하지만 Best-fit도 앞으로 설명한 외부 단편화로 인해 메모리를 낭비하는 문제가 있습니다.
결국 전체적으로 효율적이지 않습니다.
Fragmentation
단편화(Fragmentation)는 프로세스들이 메모리에 적재되고 제거되는 일이 반복되면서 프로세스들이 차지하는 메모리 틈 사이에 사용하지 못할 만큼의 작은 공간들이 늘어나게 되는 현상입니다.
외부 단편화
외부 단편화는 메모리의 남은 Hole의 총 공간에는 프로세스가 충분히 들어갈 수 있지만 Hole들이 연속적이지 않아 사용할 수 없는 경우를 말합니다.
내부 단편화
내부 단편화는 프로세스가 사용하는 메모리 공간보다 분할된 공간이 커서 메모리가 남는 경우를 말합니다.
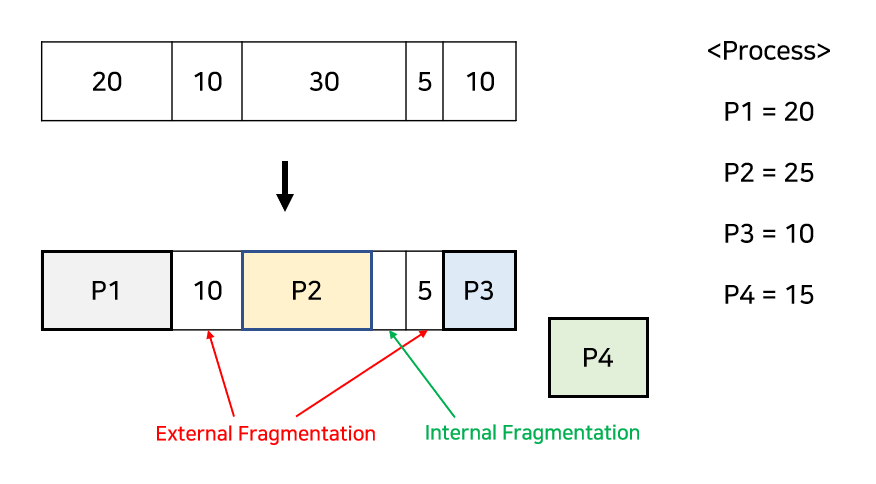
고정 분할은 두 단편화 모두 발생할 수 있고 가변 분할은 외부 단편화가 발생할 수 있습니다.
Compaction
외부 단편화를 해결할 수 있는 방법입니다. 압축(Compaction)은 프로세스가 사용하는 공간들을 몰아서 공간을 확보하는 방법입니다. 하지만 비용이 매우 많이 드는 작업이므로 효율이 좋지 않습니다.
