Recap of Accomplishments
2023-08-23
- 논문 몇개 읽어봄
- 계절별로 나눠서 RMSE 계산
- 맑은날/흐린날 로 나눠서 RMSE 계산
- 시도하려고 했던 transformer는 시계열에서 성능이 낮다는 논문
- ERA5 dataset 다운받고 태양광 발전소 데이터와 합침
- 저번 주 사용했던 머신러닝 모델
- 앙상블이 결과가 좋았지만, GRU모델도 좋을것으로 예상, 같이 돌려보기로 했다.
2023-08-24
- 머신러닝 모델
- 데이터에서 교수님이 조언해주신 '구름 종류' 'MidLowCloudCoverage(1/10)' 등등을 빼고 머신러닝 돌려보니 -> RMSE가 늘어남... 칼럼에 대한 원인 분석
- 기존 asos 데이터로 GRU모델 돌림
- 모든 파라미터에 대해 최적의 파라미터를 학습하기엔 -> GPU 없음 너무 느림
-> 임의로 파라미터를 설정한 후, 간단한 모델로 학습
1-1. 정규화
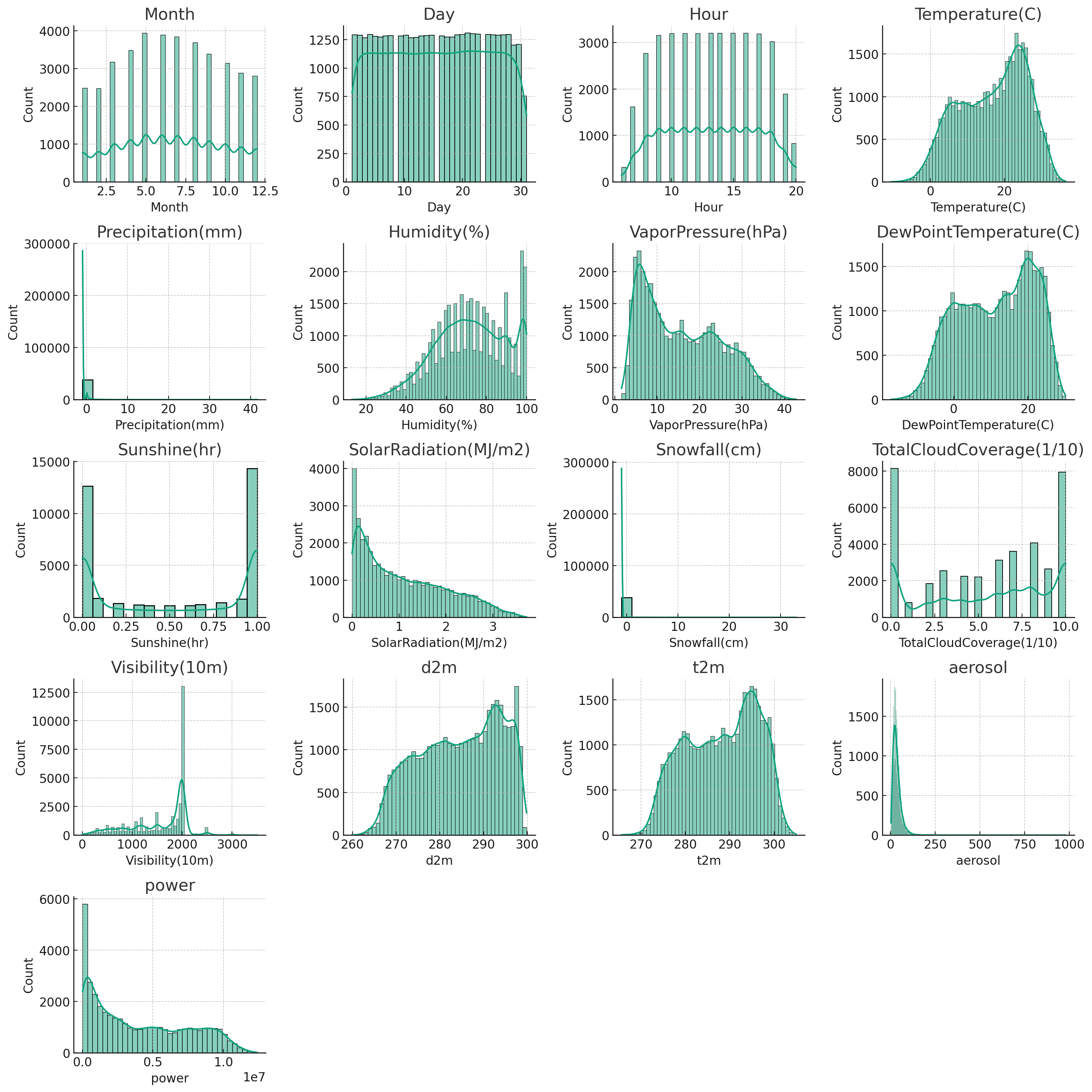
- 정규 분포를 따르지 않는 것 같아 보임
Sunshine(hr)나Snowfall(cm)과 같은 피처들은 왼쪽으로 치우쳐진 분포Precipitation(mm)에서는 몇몇 값들이 다른 값들에 비해 매우 높아 보임->이상치MinMaxScaler보다 이상치에 민감하지 않은 StandardScaler가 더 적합하다고 판단
1-2. 코드 정리
- 코드 쓰면서 최대한 깔끔하게 쓰려고 노력함...
1-2. 문제
- 실제값
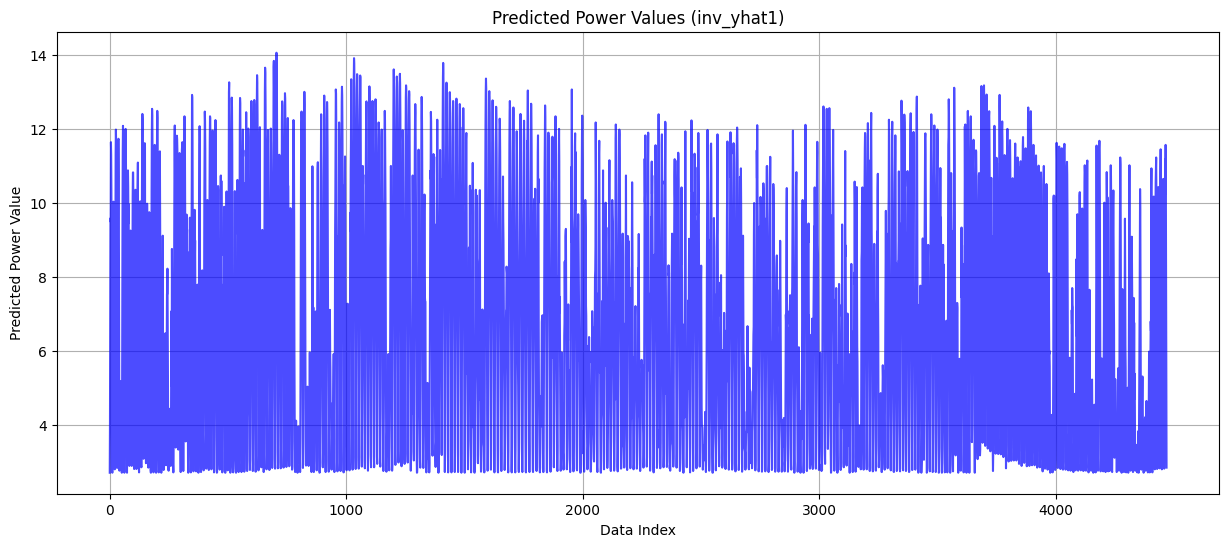
- 예측값
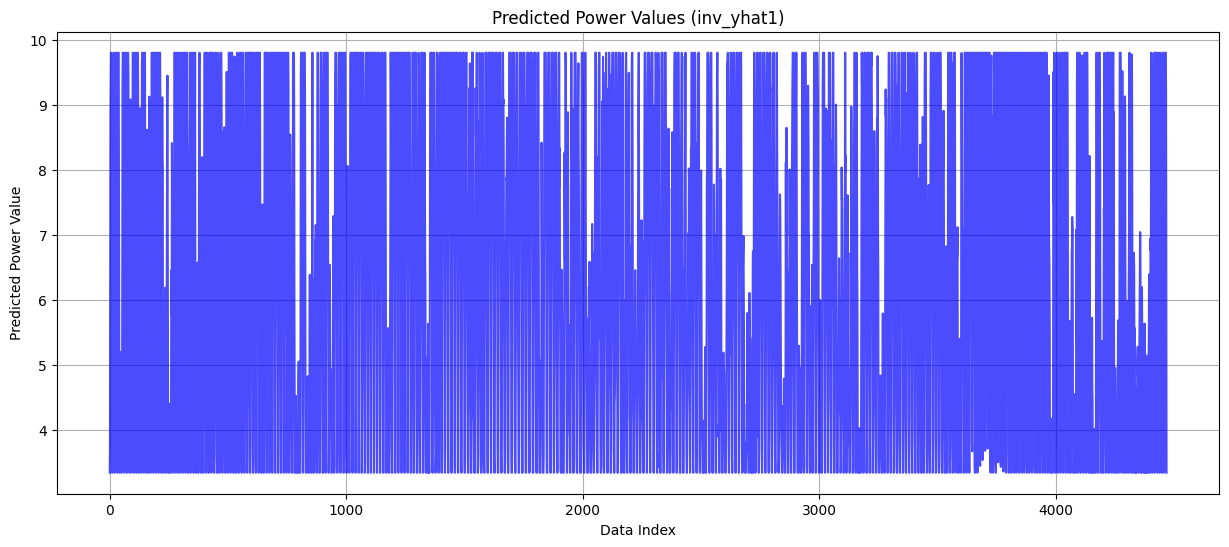
예측값에 윗부분이 짤림... 분명 어딘가에 문제가 있는데 뭘까
- 해결방법
모델 마지막에 tanh활성화 함수를 사용해서 출력값에서 제한이 걸린 것 같다.
linear로 다시 훈련시키니까 잘 나옴

1-3. 시각화
1) 계절별 오차 분석
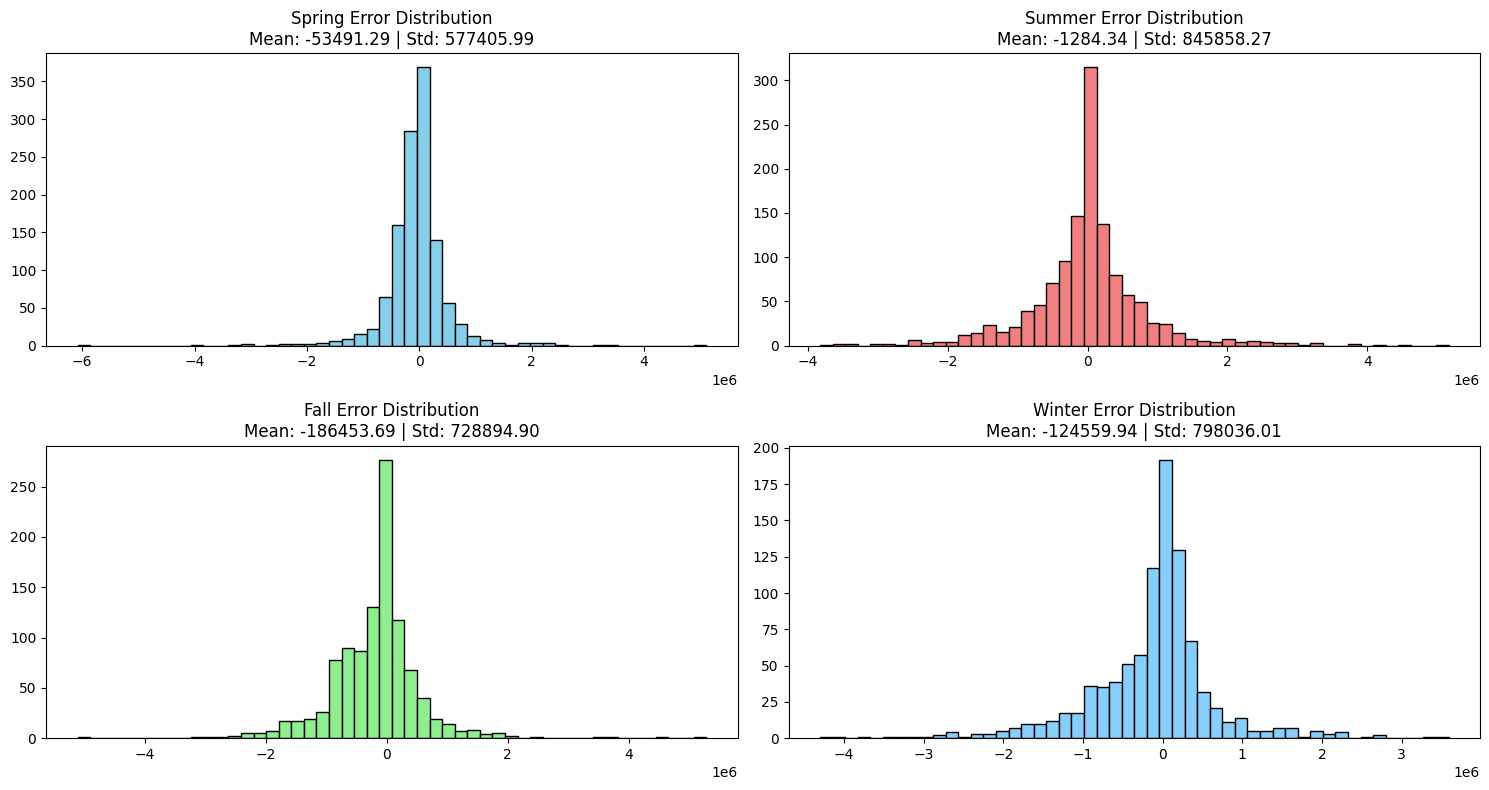
- 봄과 가을에서 정확한 예측을 보임
- 여름과 겨울에 오차가 크게 나타남
2) 시간별/일별 오차 분석
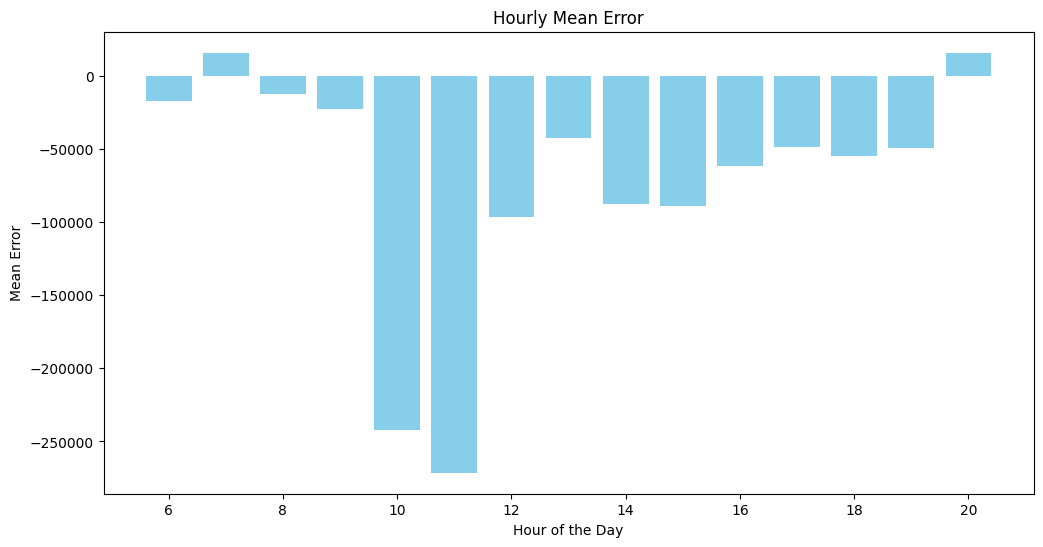
오전 특히 10시, 11시에 오차가 엄청 크게 나타남
3) 오차의 시계열 분석
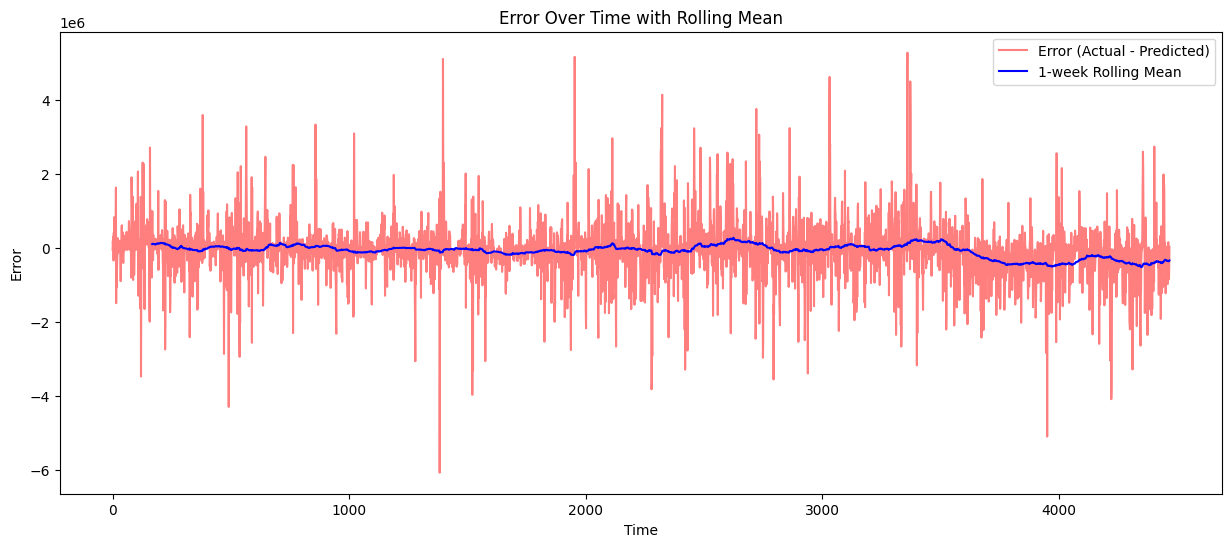
- 시간 순서대로 모든 개별 오차값 표시함
- 특정 시간대나 순간의 급격한 오차를 확인해보려고 했으나 확인이 조금 어려움
- ERA5 로 GRU 및 머신러닝 훈련
결과 : 둘다 asos데이터보다 결과가 안좋음
이유는 모르겠음...
2023-08-25
- 시각화
- 매일 발전량 실제값/예측값 확인
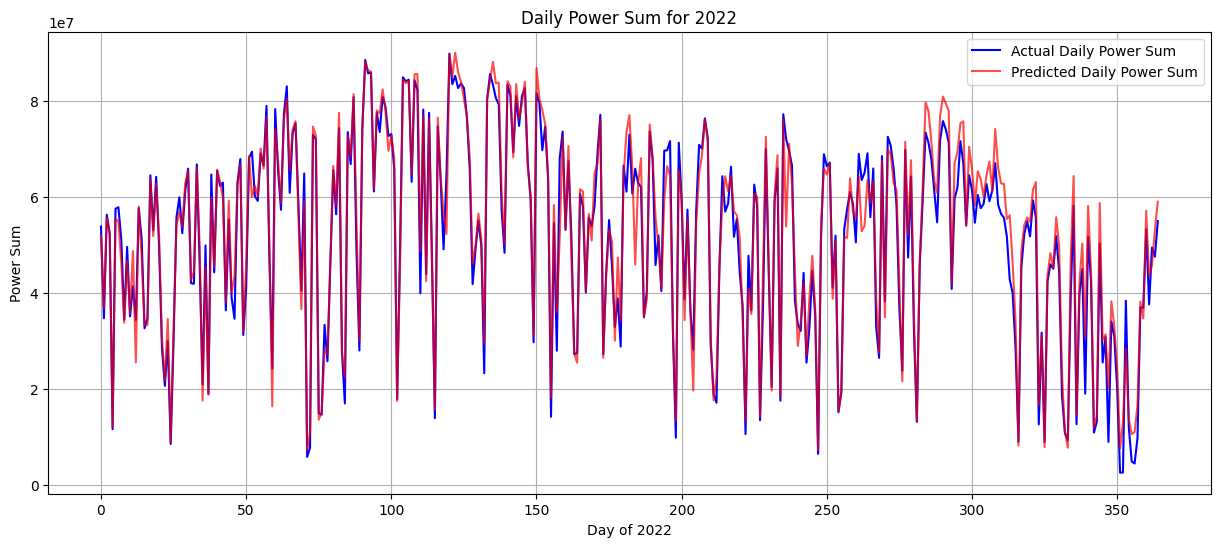
잘 안보여서 오차만 확인함 - 예측값-실제값
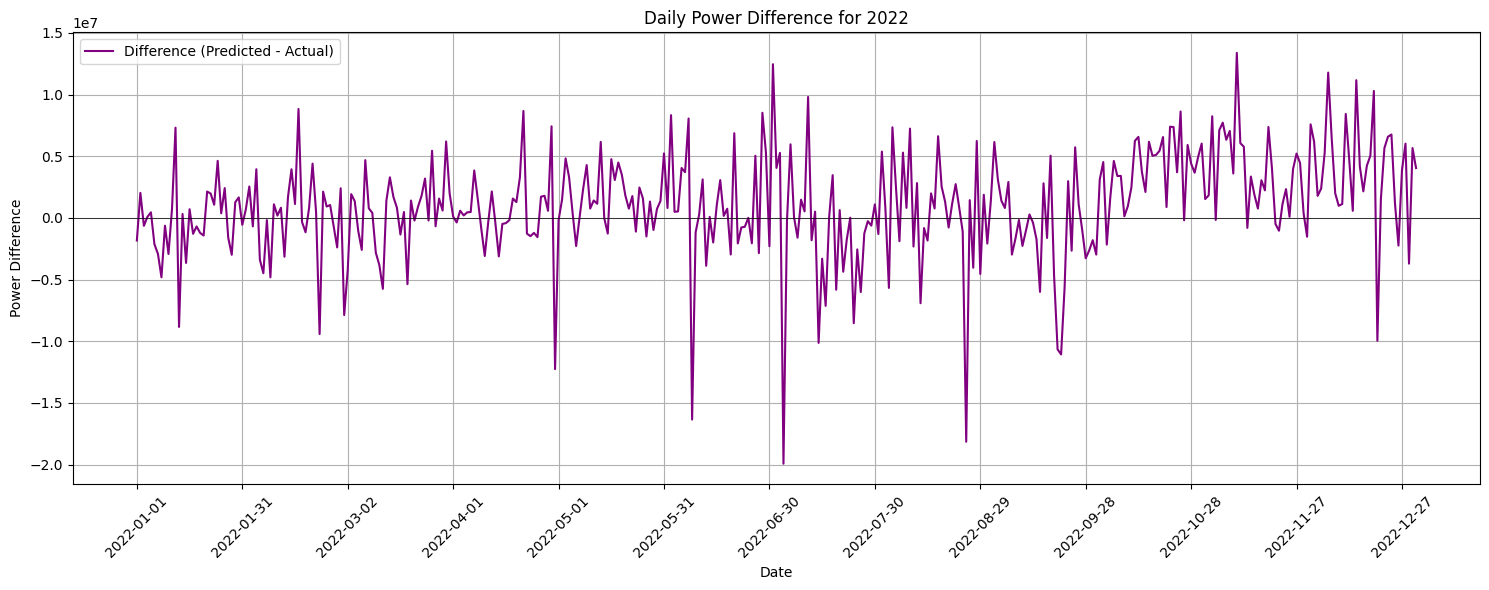
오차가 큰 날을 뽑아봄
['2022-09-20',
'2022-09-21',
'2022-12-14',
'2022-12-06',
'2022-04-30',
'2022-07-01',
'2022-11-10',
'2022-06-08',
'2022-08-25',
'2022-07-04']
점점 오차가 심해지는 날짜들임
제일 심한 2개 날짜를 살펴보니 비가 왔었음...
-
계절별 발전량 합계 확인

특이한 점 : 어제 확인한 그래프에서

여름과 겨울이 분포가 넓게 퍼져있는데 위에 그림을 보면 오히려 여름과 겨울의 합계가 실제합계값과 비슷함
=> 2022년 하나를 test set으로 보기에 너무 데이터가 작음...
=> 2020, 2021, 2022를 test set으로 하고 이전 데이터를 train으로 돌려보면 잘 확인할 수 있을 것같음. -
칼럼별 영향

의외로? Visibility가 영향이 크다...
흠 확실히 강수가 영향을 많이 안끼치는 것 같다.
강수를 좀 더 중요하게 생각하도록 전처리를 다시 해야할 듯 -
오차가 많이 나는 이유
- 장치의 고장 / 나쁜 기상 조건 등
- AI 서버
- 토치에서는 gpu사용이 가능한데 tensorflow에서는 gpu 인식이 잘 안된다....
sudo 명령을 사용할 수 없어서 conda 환경을 만들었는데 cuda 버전을 ... 모르겠고 라이브러리 하나가 없다는데 그 위치를 못찾겠다.... 일단 계속 해결중
Next Week's Agenda
- 고민 : 정확히 어떤 값을 예측하고 싶은지 알고싶다.
- 1년 통합? 월별 통합? 당연히 시간대(2025년 3월 18일 오전 10시)는 아닌 것 같아서... 통합이라면 통합값을 넣어서 다시 학습시켜야 할듯 or 지금처럼 시간대별로 학습 후 값 더하기해도 됨 (비교해봐야할듯)
- 데이터 개선 가능성
- 비오는 날에서 오차가 크니까 강수량에 대해서 전처리를 잘 하면 성능이 올라갈 것 같음
- 위에서 언급했던 칼럼을 빼니까 성능이 낮아진 문제 를 조금 살펴보면 답이 나오려나?
- 모델 개선 가능성
- GRU 모델 층을 더 쌓고 파라미터 개선(ai 서버 해결되면 가능할것같음) 하면 더 좋은 성능 가능
- 시계열에서 제일 좋은 모델 TimesNet써보고 싶음 궁금
추가내용
- 부스팅 모델을 고려해볼 것....
강수량이 영향을 많이 끼치는데 거의 90%에서 강수량이 없기 때문에 !!!!!! - 정형 데이터에 한해서는 부스팅 모델이 더 좋은 결과를 낼 수 있음
다만 feature가 많아지게 되면 GBM은 문제가 발생할 가능성이 높지만 여기서는 신경망이 더 좋을수도 있음 - 부스팅 모델은 신경망보다 훨씬 안정적이기 때문에 전체적인 디자인은 더 좋다.
한번 도전해봐도 나쁘지 않을 듯 오히려 전체적인 오차가 줄어들 수도...
- 부스팅 모델을 사용하여 데이터의 주요 특성이나 중요 변수를 파악하고,
- 이러한 정보를 바탕으로 신경망 모델의 아키텍처나 입력 특성을 결정하기로 !!!!

뜬금없지만 세계여행이 꿈입니다.