Recap of Accomplishments
2023-09-04
- 논문 Why do tree-based models still outperform deep learning on tabular data?를 참고하여 Tree 모델의 가능성 살펴봄
- 데이터 정규화
- 대부분의 변수에 Standardization 정규화 방법 적용
- 대부분의 값이 결측치인 강수량에 대해 log scaling 적용
- Catboost model 에 대해 파라미터 학습
- optuna이용
- 상관계수가 큰 "d2m(C)", "VaporPressure(hPa)"을 지웠더니 성능이 18%정도 좋아짐.
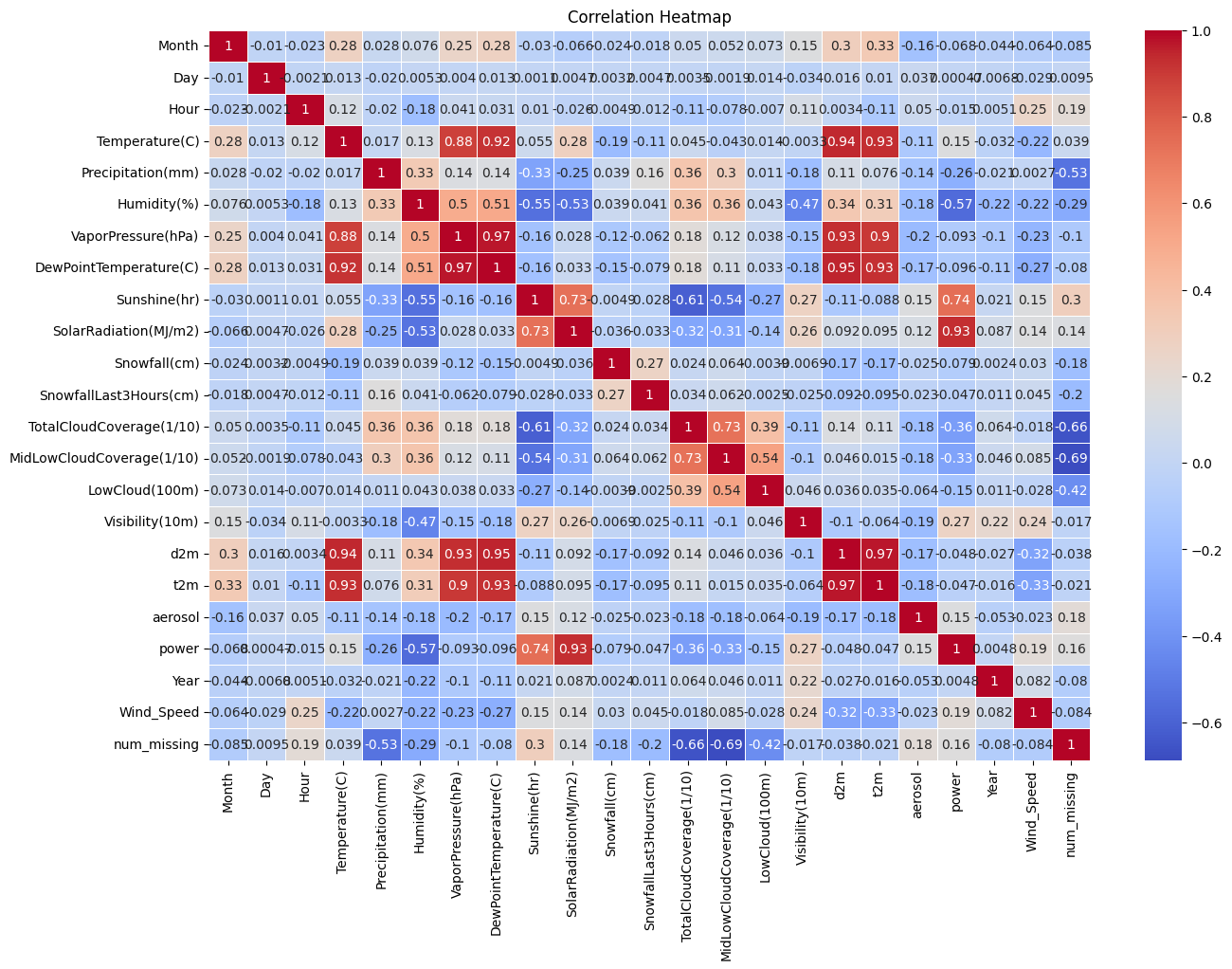
해당 피겨에서 d2m, t2m, temp, dewpointtemp 변수가 중복되어 둘 중 하나만 사용하기로 하고
VaporPressure는 d2m, t2m와 공통적으로 Corr값이 높기 때문에 drop하기로 결정하였다.
- 내일 할 일
- 코드 이상한 점 없나 살펴보기
- 에러 크게 나는 날짜 확인하기
- test 다른 지역 데이터로 실험하기
- 교수님과 면담
2023-09-05
-
교수님과 면담
- d2m -> dewpoint 값으로 교체 1.28% -> 1.19% ✅
- windpoint 값 넣기 1.19% -> 1.27% ❌
- 눈에 log값 취하기 1.19% -> 1.20% ❌
- 상관계수 값 뽑기 ✅
- 초록 작성하기(2가지 버전)
- 다른 지역 날씨값 넣어서 발전량 test해보기
- 3번까지는 안해도됨
-
에러 크게 나는 날짜 확인하기
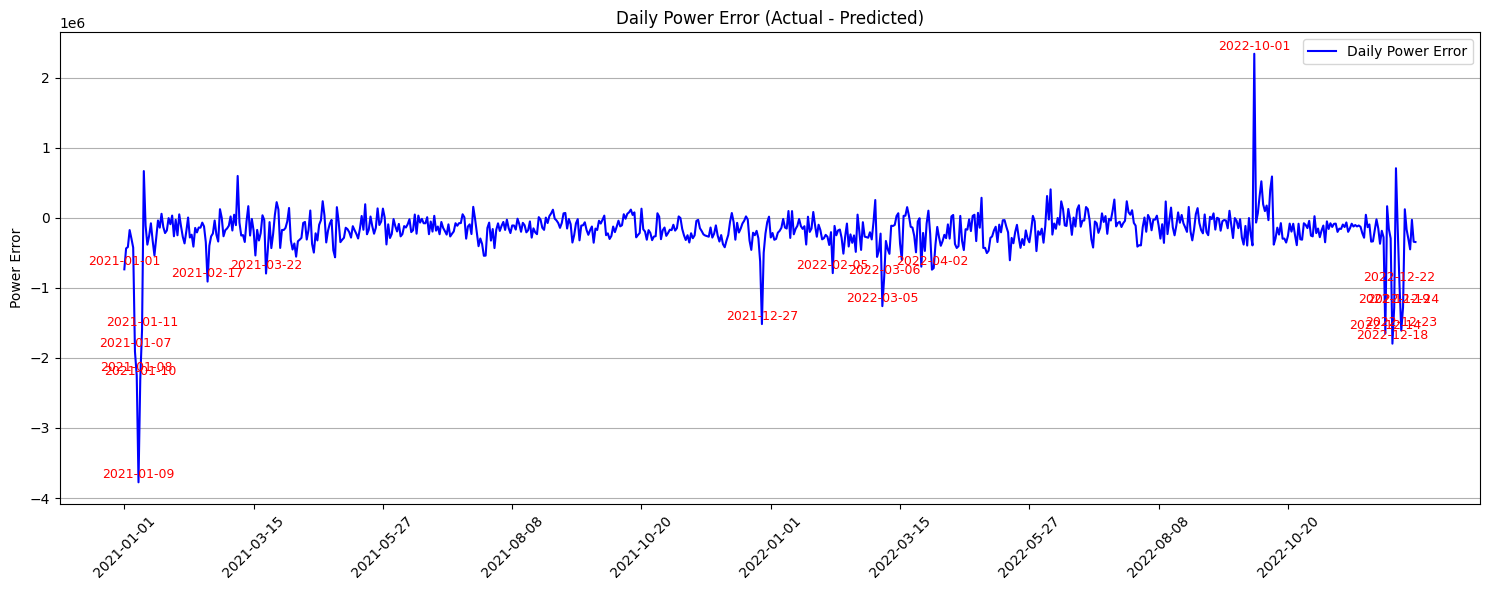
날짜들에 대해 주변 데이터들을 확인한 결과 주로 눈이 오는 날에 오차가 컸고, 데이터가 잘못 기입된 날짜(2022-10-01)를 확인하였다.
-> 추후에 모든 변수의 데이터들에 대해 이상값이 있어서 확인하는 알고리즘을 만들어도 좋을 듯.(하지만 사소함) -
강수와 눈이 power칼럼에 얼마나 영향을 주는지 확인
'Snowfall(cm)'에 따른 'power'의 평균값:- 영향이 거의 없는 범위 (Low): 약 2.7748×1062.7748×106
- 적당한 영향이 있는 범위 (Medium): 약 2.1270×1062.1270×106
- 매우 큰 영향을 주는 범위 (High): 약 1.9261×1061.9261×106
-
'Precipitation(mm)'에 따른 'power'의 평균값:
- 영향이 거의 없는 범위 (Low): 약 1.6415×1061.6415×106
- 적당한 영향이 있는 범위 (Medium): 약 1.3566×1061.3566×106
- 매우 큰 영향을 주는 범위 (High): 약 8.2621×1058.2621×105이 결과를 기반으로 강수/눈 영향을 3 level로 분류하여 새로운 컬럼을 생성해서 학습하였으나 학습 error percentage가 1.27% -> 1.28%로 증가하였다.
2023-09-06
- 오전 수업
- 변수들을 하나씩 빼보기 시작했다.
- 전체 변수 다 넣었을 때 1.28% (| Month | Hour | Temperature(C) | Precipitation(mm) | DewPointTemperature(C) | Sunshine(hr) | SolarRadiation(MJ/m2) | Snowfall(cm) | SnowfallLast3Hours(cm) | TotalCloudCoverage(1/10) | MidLowCloudCoverage(1/10) | LowCloud(100m) | power | num_missing |)
- +wind_spped추가 1.28%
- "Humidity(%)", "Visibility(10m)"추가 1.51%
- MidLowCloudCoverage(1/10) | LowCloud(100m) | Humidity(%)", "Visibility(10m) 삭제 1.23%✅
- 논문에서 사용한 변수 확인
- downwelling shortwave irradiance (rsds)
- surface wind speed (sfcWind)
- near-surface air temperature (tas)
- 논문에서 사용한 변수만 사용하여 학습
- XGBoost 모델에서 가장 낮은 에러율 27.4%
- 여기서 시간변수 추가했더니 살짝 높아짐 24.8%
- 논문에서 사용한 선형 함수를 내 데이터에 적용
- 에러율 39%
2023-09-07
- 교수님과 미팅
1) 논문에서 사용한 변수 + 선형함수 39%
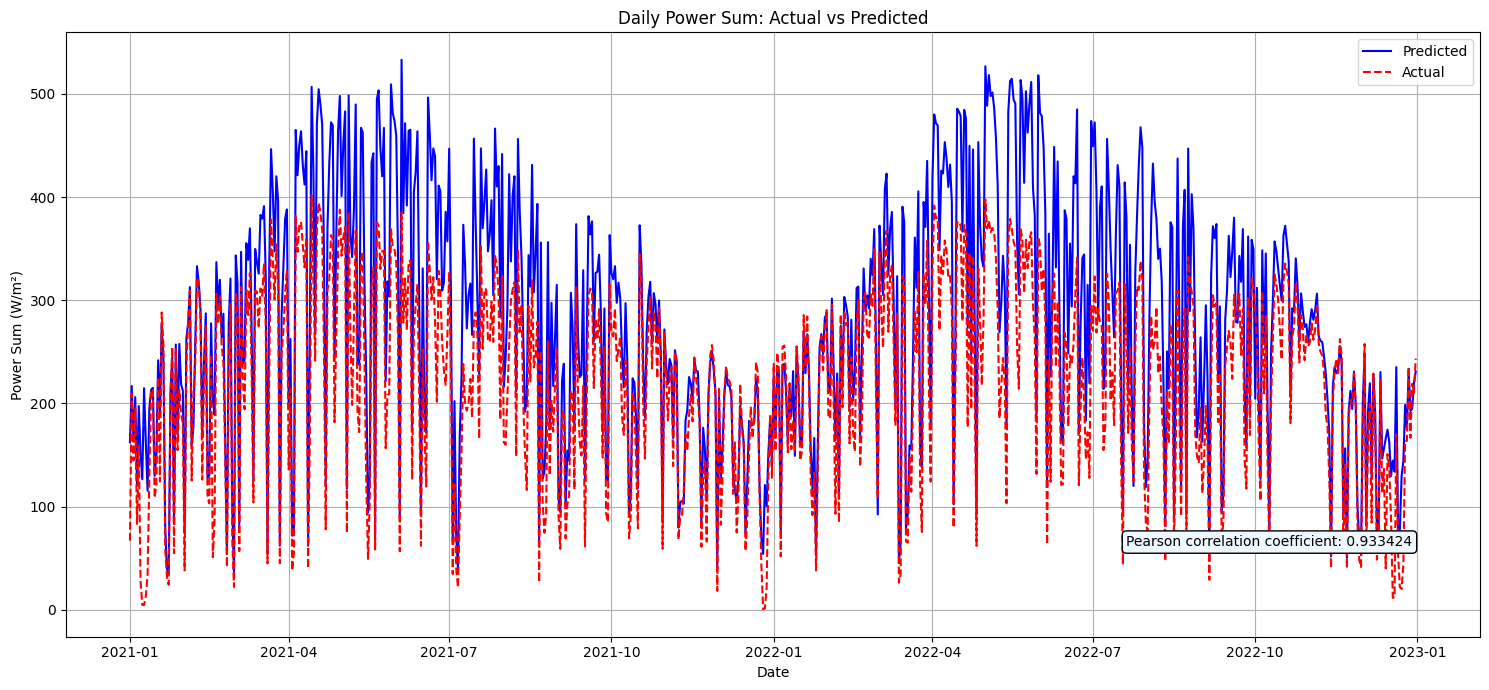
2) 논문에서 사용한 변수 + 내 모델 27.4%

3) 온도, 풍속, 태양 복사, 날짜와 시간, 강수량, 이슬점온도, 일조, 적설 그리고 전운량 변수 + 최적화 모델 1.28%

4) 여기까지 학회에서 발표하는걸로.
5) 외국 논문 포함 내가 사용한 모델로 태양광 발전량 예측한 논문 있는지 찾아보기.
6) 지금 내가 가지고 있는 결과가 [변수3개로 만든 결과][변수 10개로 만든 엄청 좋은 결과] 이 두개가 있는데,이 사이에 [어떤 데이터에도 적용가능한 최적화 변수로 학습한 모델] 이 있었으면 좋겠다고 하셨음
7) 이 모델을 찾으면 ERA5에서 0.25도 해상도의 한반도에 맵핑해서 그림을 그려보고
8) 미래기후(SSP5-8.5)에서 적용하여 10년후, 20년후, 50년후까지의 발전량 증가/감소/유지 확인하기
- 2)에 대해서 3개 변수에 대한 모델 파라미터 학습
-> 결과가 더 안좋게 나와서 이전 파라미터 사용
2023-09-08
- 오전 수업
- 초록 완성
- catboost 모델에 대해 변수 최적화 -> 다른 지역에 대해서도 test
- 외국 논문 포함 내가 사용한 모델로 태양광 발전량 예측한 논문 있는지 찾아보기
4. Tree모델 써보기
Next Week's Agenda
- 초록 제출하기
- catboost 모델 최적화
- 최적화 된다면 ERA5에서 0.25도 해상도의 한반도에 맵핑해서 그림 그려보기
