공모전에 나갔을 때 불균형 데이터 처리를 위해 시도했던 방법들을 정리해보려 한다.
불균형 데이터란?
타겟 변수가 범주형일 때, 각 클래스가 갖고 있는 데이터의 양에 차이가 큰 경우이다.
이번 공모전에서는 13진 분류였는데 제일 데이터 수가 많은 건 대략 4만개가 넘었지만 제일 데이터의 수가 적은 건 1개였다.
이번에 총 3가지 기법을 사용하여 처리했다.
1. 오버 샘플링 (oversampling)
소수 범주 데이터를 다수 범주 데이터 수에 맞게 늘리는 샘플링 방식
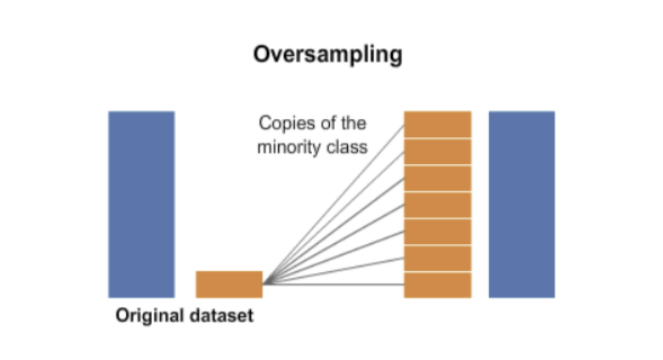
소수 범주 데이터를 다수 범주 데이터 수에 맞게 늘리는 샘플링 방식
SMOTE
소수 범주에서 가상의 데이터를 생성하는 방법
- 먼저 소수 클래스에서 각각의 샘플들의 knn(k-nearest neighbors)을 찾는다.
- 그리고 그 이웃들 사이에 선을 그어 무작위 점을 생성한다.
이렇게 생성하면 샘플들 사이의 특성들을 반영한 데이터가 생성된다. 하지만 존재하지 않은 데이터를 생성하는 것이기 때문에 overfitting 문제가 발생할 수 있다.
from imblearn.over_sampling import SMOTE
X_resampled, y_resampled = SMOTE(random_state=0).fit_resample(X, y)2. 클래스에 가중치 부여하기
oversampling이나 undersampling 모두 데이터를 생성하거나 버리는 방법이기 때문에 overfitting이 발생한다거나 데이터가 낭비되는 문제가 발생할 수 있다. 그래서 데이터는 그대로 냅두고 클래스별 개수를 계산하여 개수가 적은 것에 가중치를 더 많이 부여하게 하여 학습을 진행한다.
from sklearn.utils import class_weight
# 클래스 가중치 계산
class_weights = class_weight.compute_sample_weight(class_weight='balanced', y=y_train)
# 학습에 적용
SVM = svc(class_weight = class_weights)3. StratifiedKFold
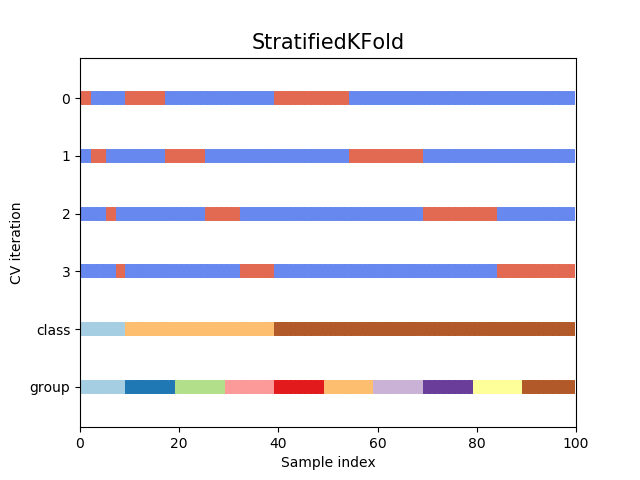
이 방법은 overfitting을 방지하기 위해 사용되는 방법이다. 그러나 데이터 불균형도 그대로 학습시키면 overfitting이 발생할 수 있다.
StratifiedKFold는 훈련 세트와 검증 세트를 무작위로 분할하는 대신, 각 분할이 원래 데이터의 레이블 분포를 반영하도록 분할한다.
➡️ 즉, target에 속성값의 개수를 동일하게 하여 데이터가 한 곳으로 몰리는 것을 방지한다.
from sklearn.model_selection import StratifiedKFold
stf = StartifiedKFold(n_splits=10, shuffle=True)4. Voting
서로 다른 알고리즘을 가진 모델을 병렬로 결합한다. 최종 output이 continuous value이면(회귀) 각 모델의 예측값을 더해 평균을 냄으로써 앙상블 모델의 출력을 얻을 수 있다. 반면 최종 output이 class label이면(분류) 다음과 같은 두 방식 중 하나를 선택해서 결과값을 도출한다.
1) Hard voting
다수의 classifier 들이 예측한 값들 중 많은 것을 선택한다.
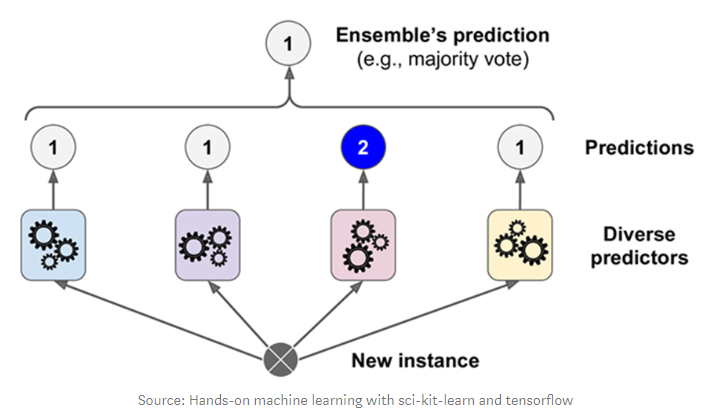
2) soft voting
서로 다른 종류의 알고리즘들을 결합하여 다수결 방식으로 최종 결과 출력하는 방식이다. 다수의 추정기에서 각 레이블 별 예측한 확률들의 평균을 내서 높은 레이블값을 결과값으로 선택한다.
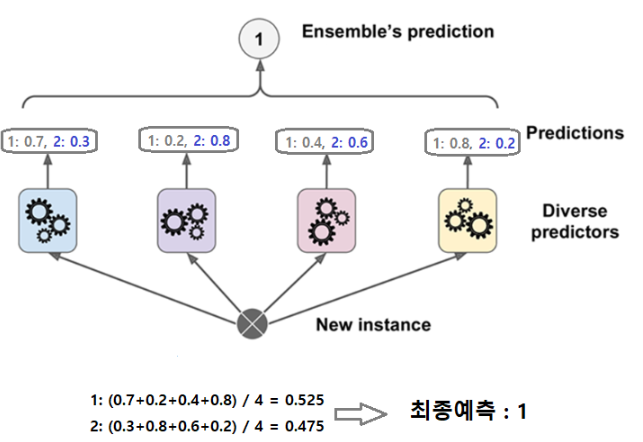
그 중 soft voting이 성능이 조금 더 좋아기에 사용했다. Soft Voting은 모델들의 레이블 값 결정 확률을 모두 더하고, 이를 평균내서 이들 중 확률이 가장 높은 레이블 값을 최종 voting 결과값으로 선정하는 방식이다.
from sklearn.ensemble import VotingClassifier
estimators = [
('rf', rf),
('xgb',xgb),
('lgbm',lgbm)
]
voting = VotingClassifier(estimators, voting='soft')
voting.fit(x_train, y_train)해당 4가지 기법들은 ,train, test 셋으로 분리한 후 train data에만 적용해야 한다 !
