[CVPR 2022] TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation
Paper Review
TopFormer: Token Pyramid Vision Transformer
여러 scale의 token을 입력으로 pyramid 형태의 vision transformer
1. Introduction
Vision Tranformer (ViT)가 엄청난 성능을 보여주고 있지만, 이 아키텍처의 full-attention mechanism은 강력한 연산자원을 요구함
이 연구에서는 semantic segmentation에 설계된 Mobile-friendly ViT를 explore하는 것을 목표로 함
최근에 PVT (ICCV 2021), CvT (arXiv 2021), LeViT (ICCV 2021), MobileViT (arXiv 2021)와 같은 대부분의 Vision Transformer들은 CNN을 사용하는 hierarchical architecture를 도입했음
이러한 아키텍처들은 global self-attention과 그것의 변형을 high-resolution의 token에 사용하는데 이는 token의 갯수에 제곱으로 복잡도가 올라가게 됨
efficiency를 올리기 위해 Swin Transformer (ICCV 2021), Shuffle Transformer (arXiv 2021), Twins (arXiv 2021), HR-Former (arXiv 2021) 들은 local/windowed region에 안에서 self-attention을 계산하는데, window하는 부분이 모바일 기기에서는 굉장히 시간이 오래 걸린다
Token slimming (arXiv 2021), Mobile-Former (arXiv 2021)는 token의 갯수를 줄임으로서 capacity를 감소시켰는데, 성능의 저하를 감수한다.
이러한 Vision Tranformer들중에서도 MobileViT (arXiv 2021)와 Mobile-Former (arXiv 2021)이 특히 모바일 기기에 맞 설계되었는데, CNN과 ViT의 강점을 결합했다.
MobileViT는 parameter수에 효율적이고 Mobile-Former는 FLOPs에서 효율적이고
그렇다면, MobileNet보다 적은 latency로 semantic segmentation task에서 더 좋은 성능을 달성하는 mobile-friendly network를 설계하는 게 가능할까? 라는 질문이 생긴다
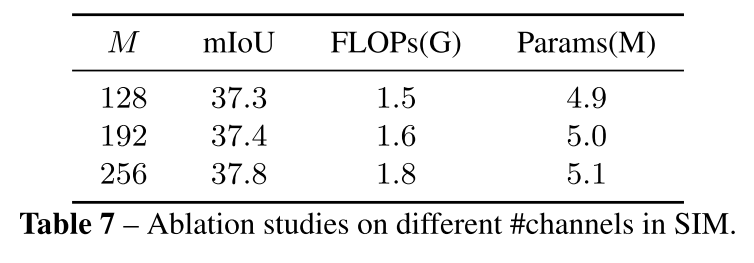
MobileViT랑 Mobile-Former에서 감명을 받아서 저자들도 CNN와 ViT의 장점을 사용할 건데, high-resolution 이미지들을 처리해 local feature들의 pyramid를 빠르게 제공할 수 있는 Token Pyramid Module이라는 CNN 기반 모듈을 사용한다
Token Pyramid Module
: local features pyramid를 빠르게 얻기 위해 고해상도 이미지를 처리하기 위한 CNN-based 모듈
Downsampling with MobileNetV2 blocks
: token pyramid를 build하기 위한 빠른 down-sampling 전략으로 경량화된 MobileNetV2 block들을 사용
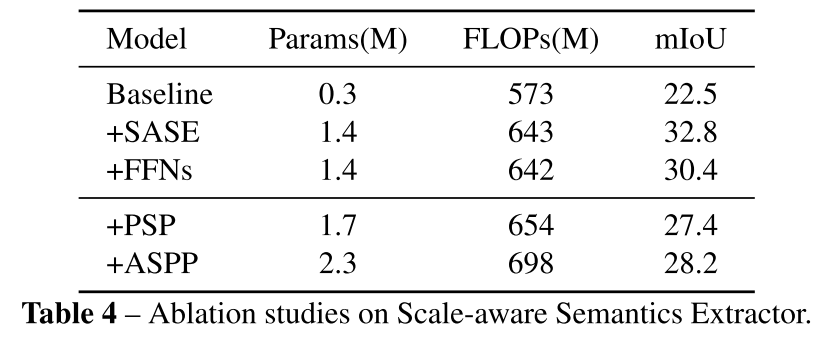
Semantic Extractor
: 풍부한 semantics와 넓은 receptive field를 얻기 위한 ViT-based 모듈, token들이 입력
Average Pooling Operator
: token을 아주 작은 size, input의 1/(64x64)로 줄이기 위한 모듈로 사용
embedding layer의 마지막 output을 token으로 사용하는 ViT, T2T-ViT, LeViT와 다르게, different scales (stages)에서 token을 아주 작은 size로 pool하고 channel dimension으로 concatenate한다
새로운 token들은 global semantic을 제공하는 Transformer block에 입력되는데, Transformer block의 residual connection으로 인해 token들의 scale과 연관된 semantic을 배우기 때문에, scale-aware global semantics라고 명명함
dense prediction tasks를 위해 강력한 hierarchical features들을 얻기 위해, scale-aware global semantics은 서로 다른 scale에서 온 token들의 channel에 따라 split되고 representation을 증강하기 위해 해당하는 token에 결합된다. 증강된 token들은 segmentation head의 입력으로 사용된다.
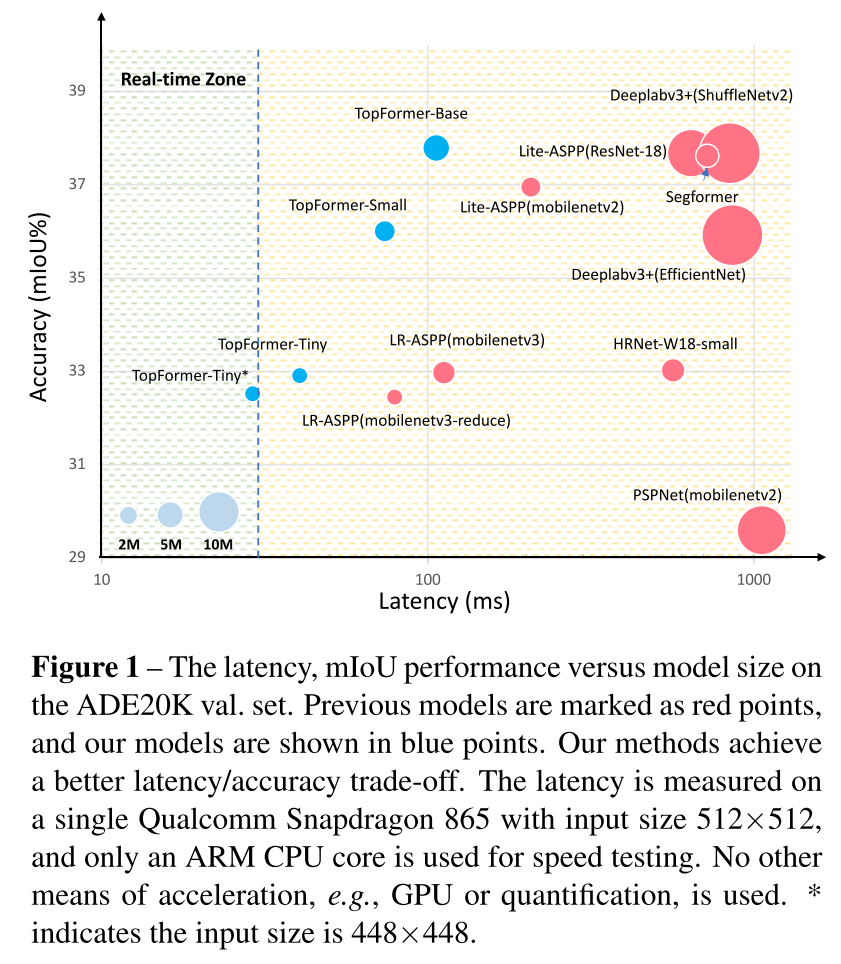
2. Architecture
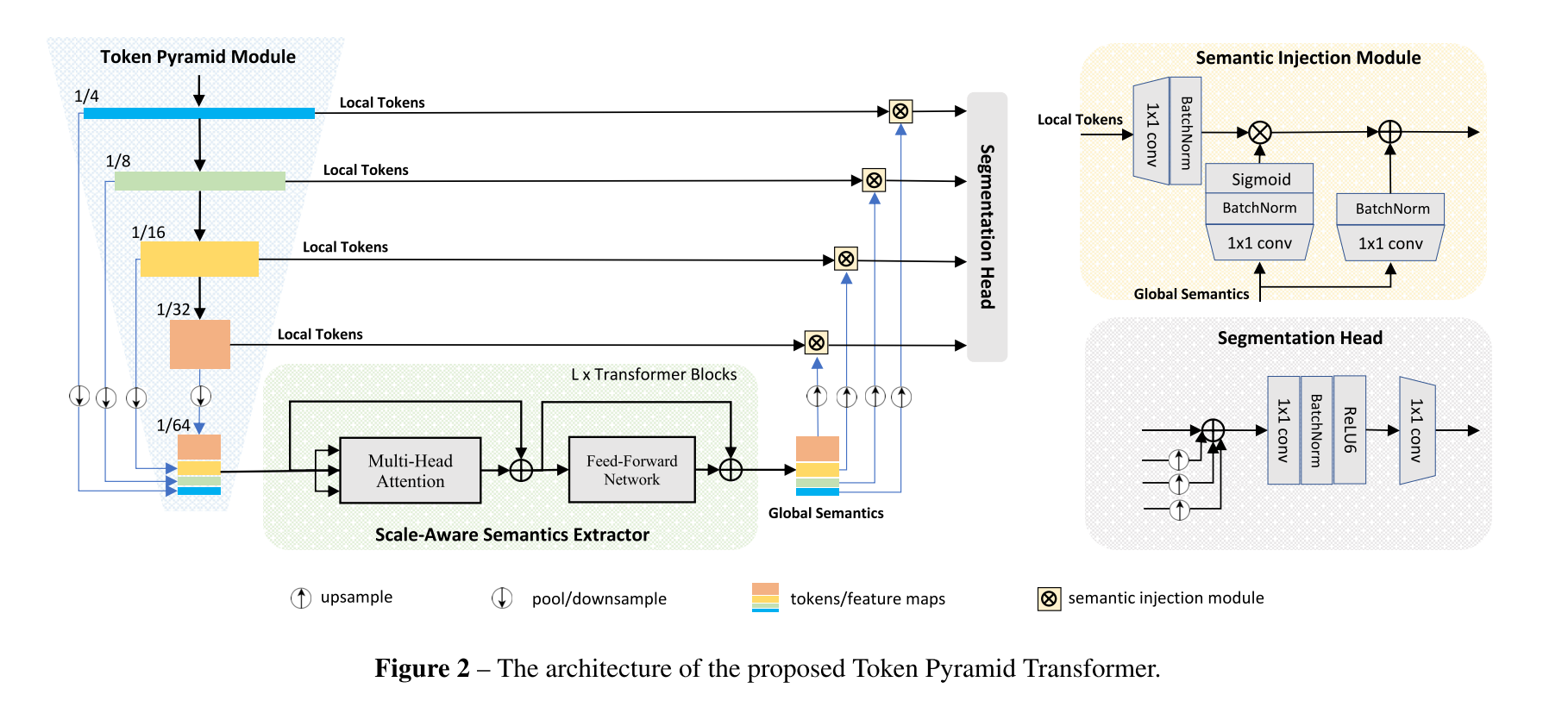
2.1. Token Pyramid Module
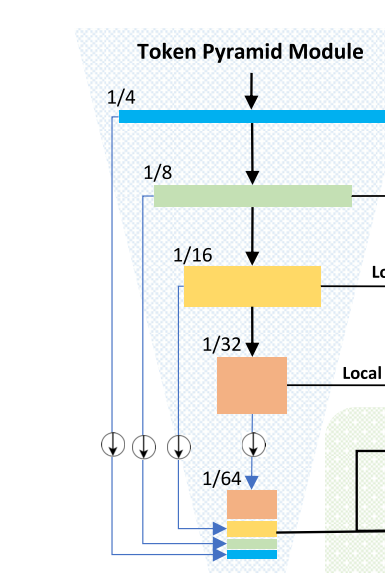
rich semantics와 large receptive field를 얻기 위한 게 아니라 token pyramid를 구축하기 위한 적은 block들을 사용한다
target size 1/(64x64)로 서로 다른 stage (scale)에서 pool하도록 하고 그렇게 channel 방향으로 concat한 것을 scale-aware semantics이라고 부르겠음
2.2. Vision Transformer as Scale-aware Semantics Extractor
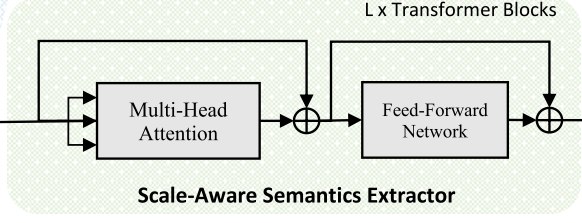
Multi-head Attention은 LeViT의 setting을 따라서 함 K, Q의 head dimension은 D = 16, V의 head dimension은 2D = 32. LayerNorm말고 BatchNorm을 사용하는데, inferenece에서 앞선 convolution과 결합했을 때 더 빠르다고 함..
Feed-Forward Network에선, 2개의 1x1 conv 사이의 depth-wise conv를 삽입해서 Vision Transformer의 local connection을 강화하는 Shuffle Transformer, CeiT를 참고함. FFN의 expansion factor는 computational cost를 줄이기 위해 2로 함
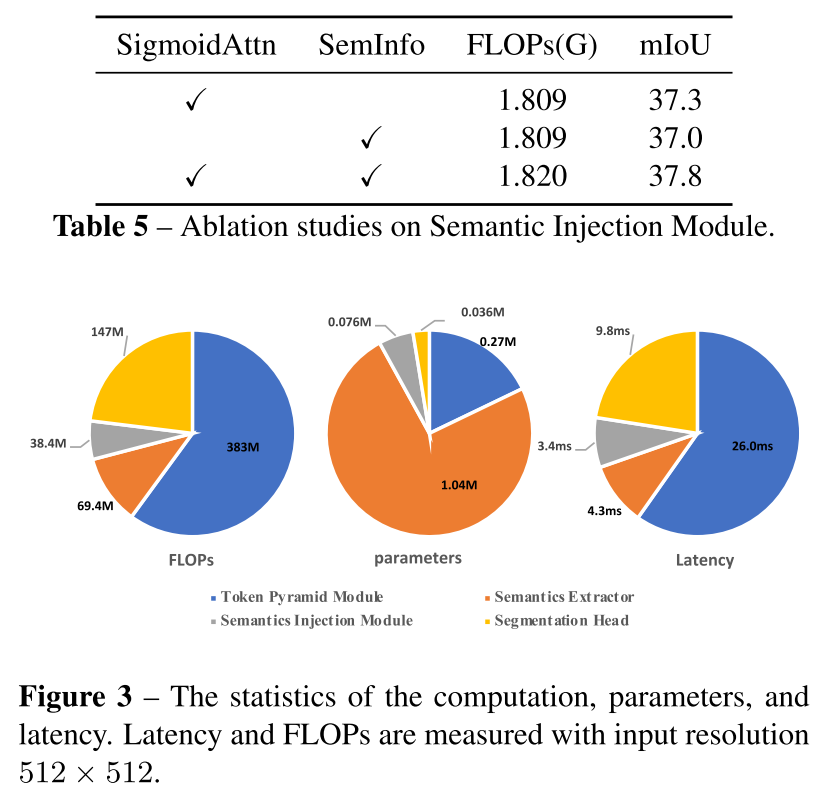
2.3. Semantic Injection Module and Segmentation Head
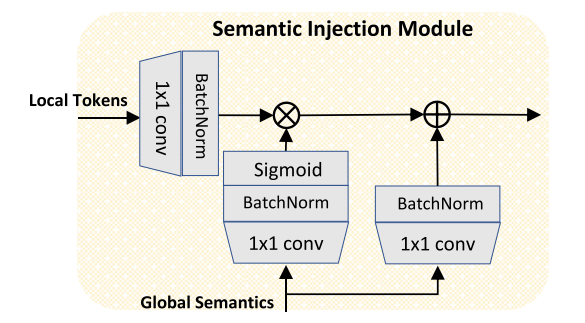
scale-aware semantics를 얻고 나서 이걸 서로 다른 scale에서의 token이랑 합쳐줄건데, token이랑 scale-aware semantic과 semantic gap이 존재하기 때문에, 이를 적절히 합쳐주기 위한 module을 쓸거다
그것이 Semantics Injection Module..! SIM.. 심봤다
Token Pyramid Module에서 나오는 local token들과 Vision Transformer에서 나온 global semantics를 input으로 하고
1x1 conv해주고 BatchNorm하고 Global Semantics에는 sigmoid를 하나 더 씌워주고 *multiply해주고 global semantics는 1x1 conv, BN을 해주고 sum을 해준다
*multiply: Hadamard production
SIM의 output들은 같은 갯수의 channel을 공유하고 이는 M이라고 할거임
semantic injection하고 나서, 서로 다른 scale에서 증강된 token들은 풍부한 공간적/의미적 정보를 모두 capture하는데 이는 semantic segmentation에서 critical하다.
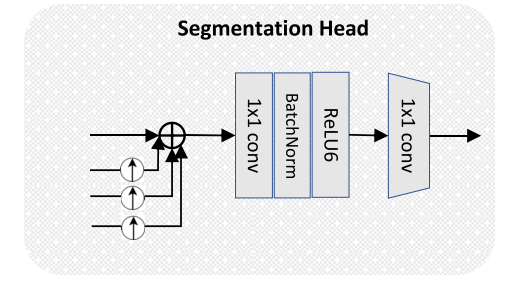
제안하는 Segmentation Head에서는 같은 resolution으로 upsample해서 모든 scale에서 온 token들을 element-wise sum을 해주고 두 개의 conv를 거쳐 최종 segmentation map을 제공한다.
2.4. Architecture and Variants
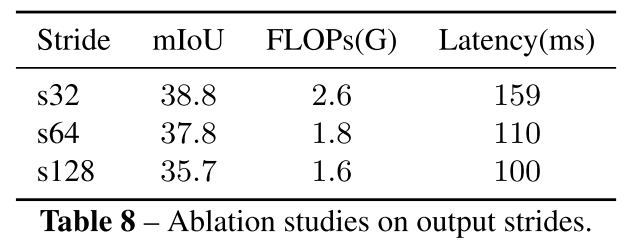
T: Tiny, 4개 head의 multi-head attention, M = 128
S: Small, 6개 head의 multi-head attention, M = 192
B: Base, 8개 head의 multi-head attention, M = 256
3. Experiments
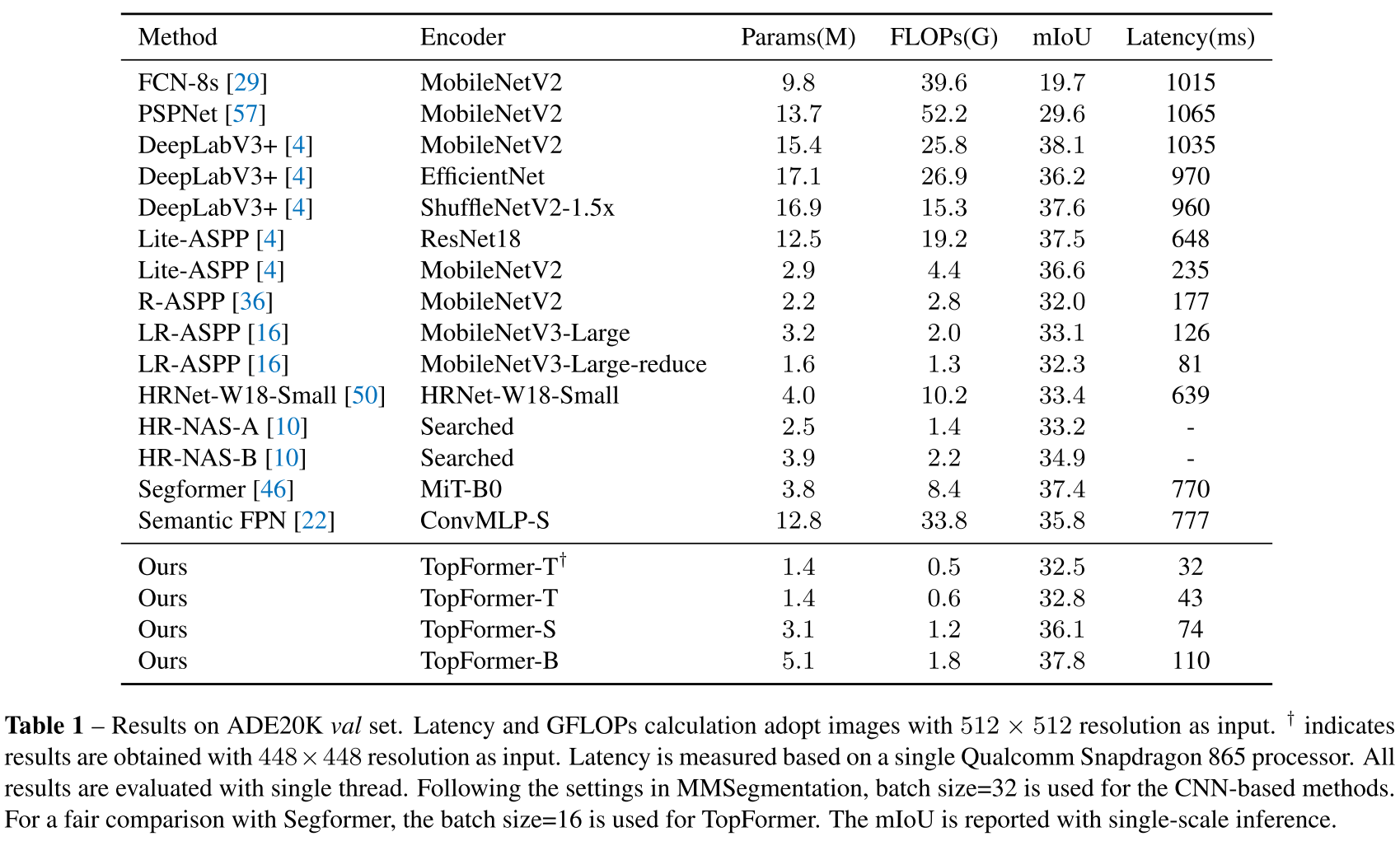
3.1. Semantic Segmentation
3.1.2. Implementation Details
MMSegmentation과 Pytorch위에서 구현이 built되었다.
여러개의 gpu를 사용하면서 BatchNorm의 평균과 표준편차를 모으기 위해 표준 BatchNorm을 Synchronize BatchNorm로 바꿨고,
ADE20K 데이터셋에서는 SegFormer를 따라 160K scheduler와 batch size 16을 사용하고, COCO-stuff와 PASCAL Context에서는 80K 훈련 iteration을 사용
초기 learning rate 0.00012, weight decay 0.01
poly learning rate scheduler factor 1.0 사용
randomly scaling, randomly cropping (고정된 크기의 patch), random resize, random horizontal flipping, random cropping 등
3.1.3. Experiments on ADE20K


그리고 Tiny 사이즈로 448 x 448 input 넣으면 모바일 기기에서의 real-time segmentation을 달성할 수 있는데, 이는 저자들이 아는 한 처음일 거라고 함
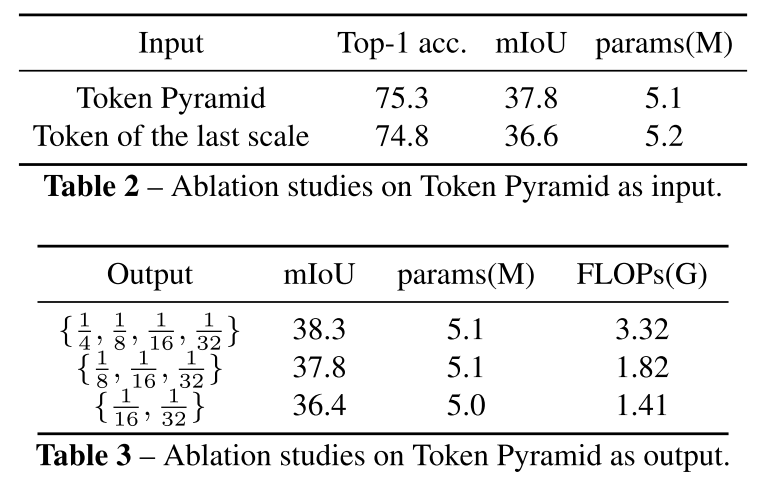
3.1.4. Ablation Study
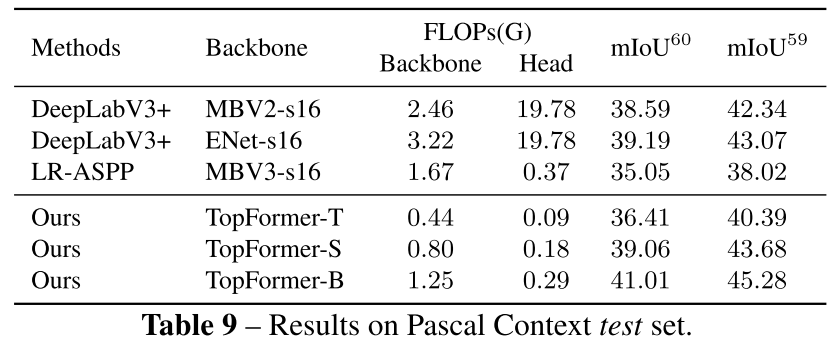
3.1.5. Experiments on Pascal Context
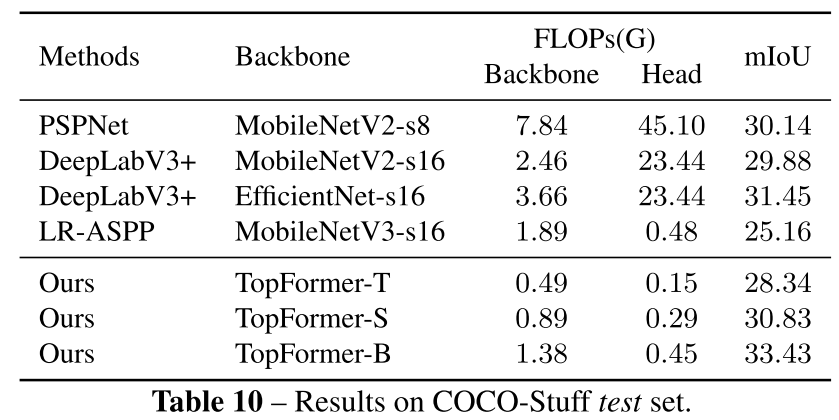
3.1.6. Experiments on COCO-Stuff
3.2. Object Detection
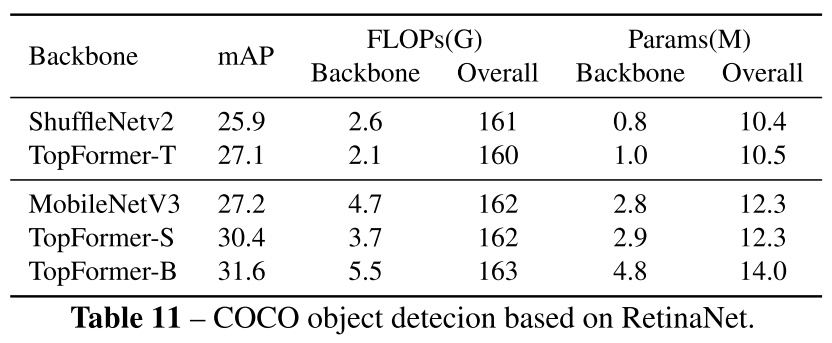
RetinaNet을 사용해 object detection을 하는데 feature pyramid를 제공하는 다른 backbone을 채택했다
MMdetection과 Pytorch에서 구현했고 segmentation head 대신 RetinaNet의 detection head로 교체했다
TopFormer 기반 RetinaNet이 MobileNetV3와 ShuffleNet보다 적은 computation으로 더 나은 성능을 달성
4. Conclusion and Limitations
제안하는 TopFormer는 CNN과 ViT의 강점을 잘 활용하여 정확도와 연산비용 사이의 좋은 trade-off를 달성했고, Tiny version은 ARM 기반 모바일 기기에서 real-time segmentation을 달성했다.
한계로는 object detection에서의 성능 개선이 미미했다는 점..?? 정도를 언급하면서 논문이 마무리된다.
