[NIPS 2022] SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
Paper Review
SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation (AAAI 2024) 라는 논문에서 다른 방법론들과 성능을 비교한 표를 보는데, SegNeXt가 그 중에서도 가벼우면서도 높은 성능을 보고하고 있어서 리뷰함.
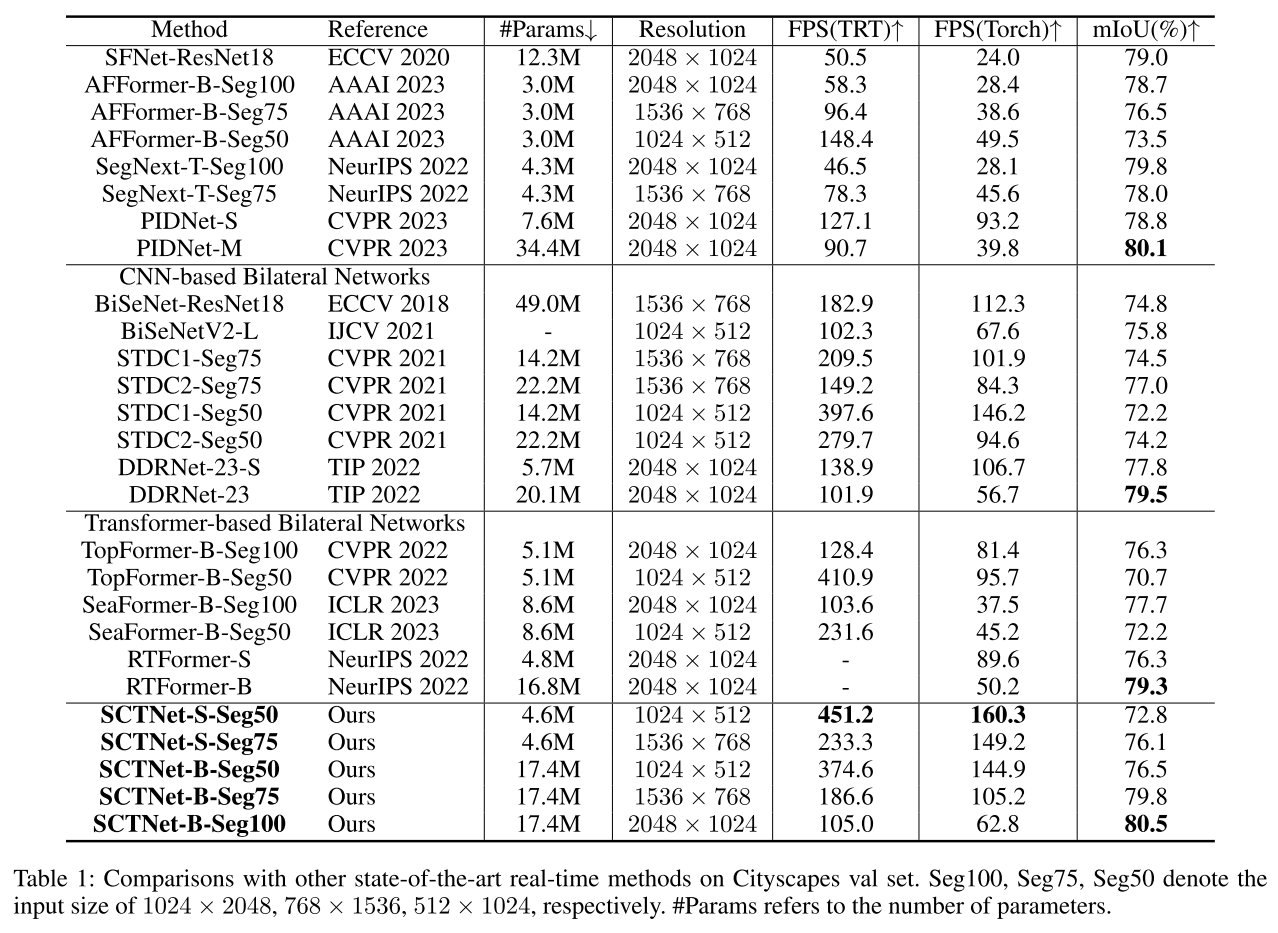
SCTNet은 특히 높은 FPS로 real-time segmentation에서의 강점을 보고하고 있는데, 저정도로 빠른 게 필요한 건 아니라서.. 오히려 가벼우면서 높은 성능을 보인 SegNeXt에 주목하게 됨. 특히나 Efficient Segmentation 모델로 리뷰했던 TopFormer, SeaFormer보다도 가벼우면서 훨씬 더 좋은 성능을 보이는 것이 흥미로웠음. FPS에서 큰 손해를 보는 것 같긴 하지만..?
- SegNeXt-T-Seg75 (78.0 mIoU, 4.3M) > SCTNet-S-Seg75 (76.1 mIoU, 4.6M),
- SegNeXt-T-Seg100 (79.8 mIoU, 4.3M) > DDRNet-23-S (77.8 mIoU, 5.7M), SeaFormer-B-Seg100 (77.6 mIoU, 8.6M), TopFormer-B-Seg100 (76.3 mIoU, 5.1M), RTFormer-S (76.3 mIoU, 4.8M)
Summary
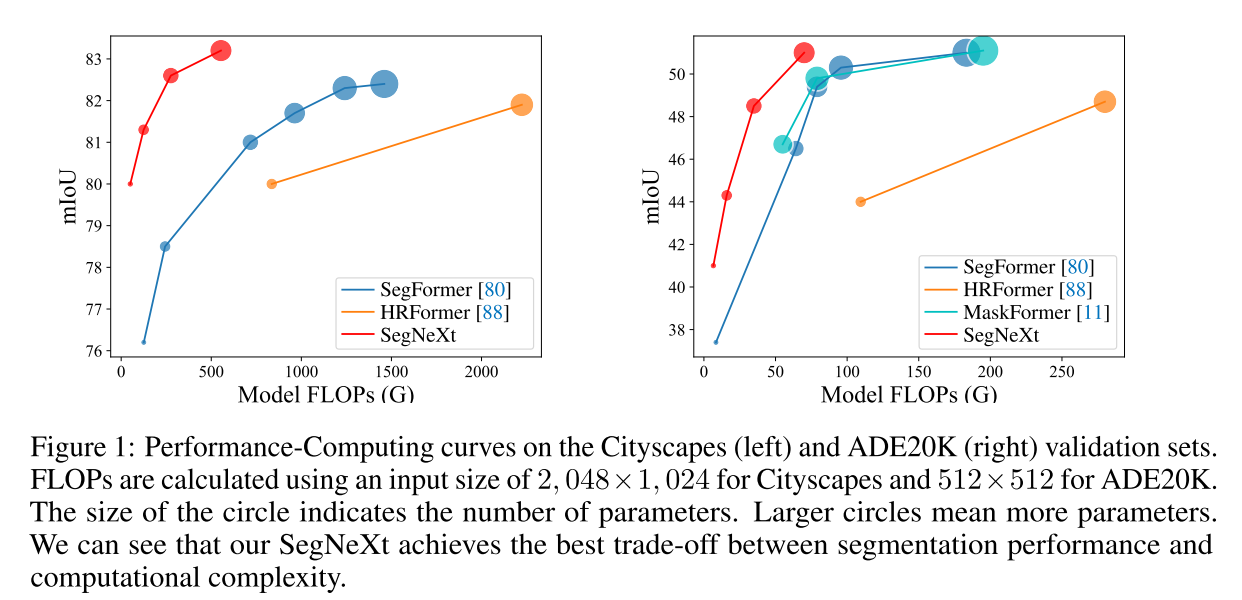
Different from previous methods, SegNeXt, besides capturing multi-scale features in encoder, introduces an efficient attention mechanism and employs cheaper and larger kernel convolutions.
- encoder는 ViT의 구조를 따르되, transformer attention block을 1xN - Nx1의 depth-wise strip convolution을 사용한 multi-scale convolution attention module로 대체함.
- 제안한 convolutional encoder의 첫번째 stage를 제외한 feature를 concatenation한 뒤, global context를 capturing하는 Hamburger (matrix decomposition-based) 라는 block 이후에 MLP를 통과시키는 decoder 구조를 함께 제안함.

3.1. Encoder
encoder는 ViT의 구조를 따르되, self-attention mechanism 대신 multi-scale convolutional attention module (MSCA) 을 사용한다.
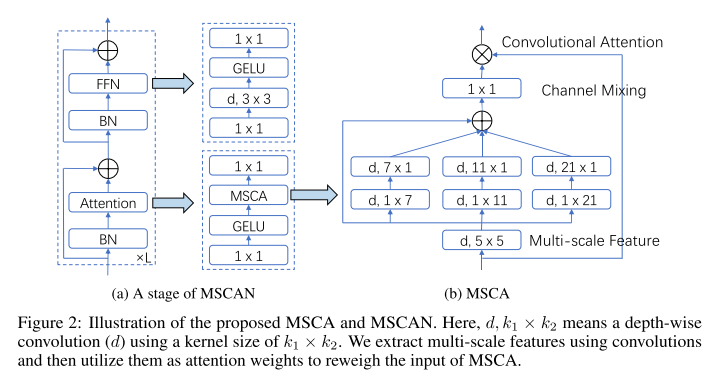
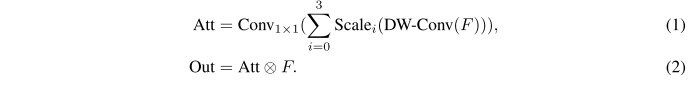
depth-wise convoltion으로 local information을 aggregate하고 multi-branch depth-wise strip convolution은 multi-scale context를 capture하도록 하고 1x1 conv로 서로 다른 채널 간의 relationship을 model한다.
이는 input feature의 weight을 구하여 다시 곱해주는 형태로 통과하게 됨.
strip convolution을 사용하는 이유를 이와 같다고 함.
- 하나는 strip convolution이 더 가볍기 때문에, 7x7 2D convolution을 하는 대신에 1x7, 7x1의 convolution 쌍을 사용했다.
- 또 다른 하나는 사람이나 전화부스처럼 strip-like objects들이 있기 때문.
self-attention 대신 제안하는 MSCA을 넣은 block을 sequential하게 쌓은 형태의 encoder를 MSCAN으로 부르기로 하자. downsampling block에서 stride 2의 3x3 conv에 batch norm을 사용한다. layer norm 대신 batch norm으로 바꿔 사용하는데, batch norm이 분할 성능이 더 좋았어서 그렇다.
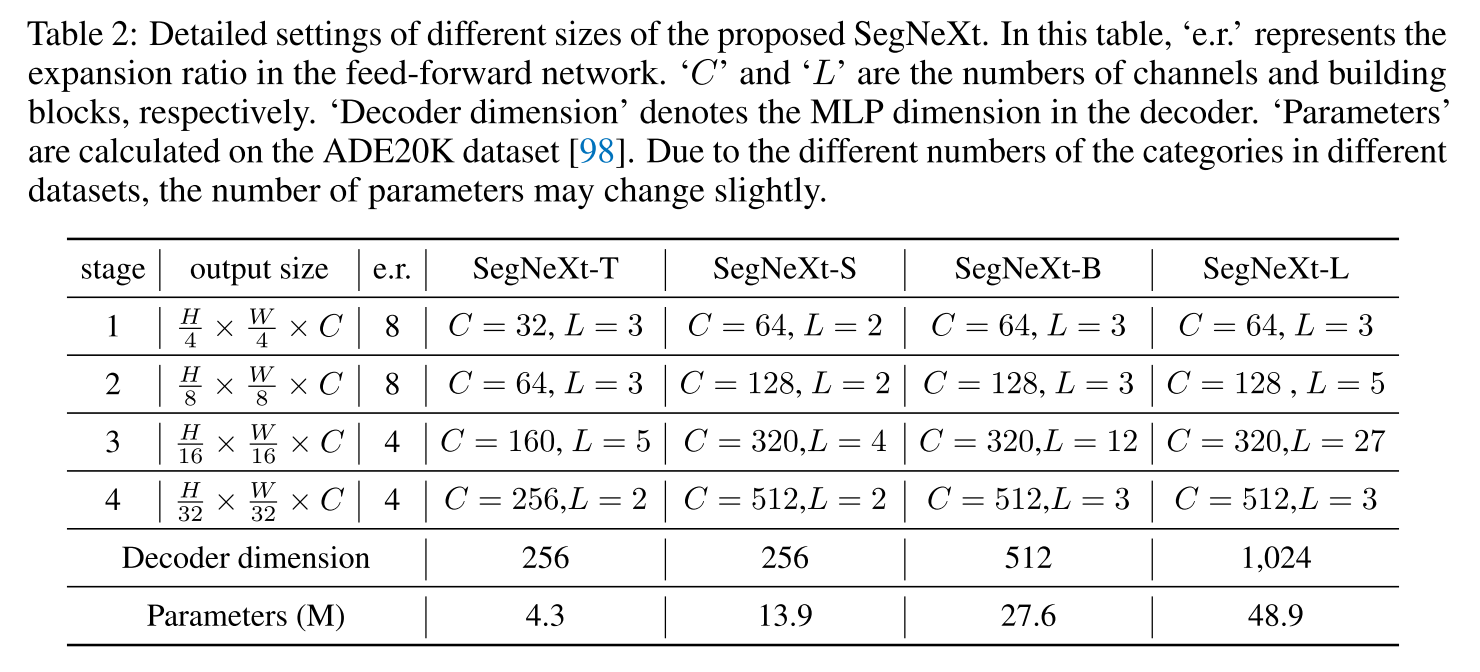
4가지 크기의 4가지 endcoder model을 만들고 decoder
3.2. Decoder
decoder를 세 가지 형태로 나눠서 분류해보았음.
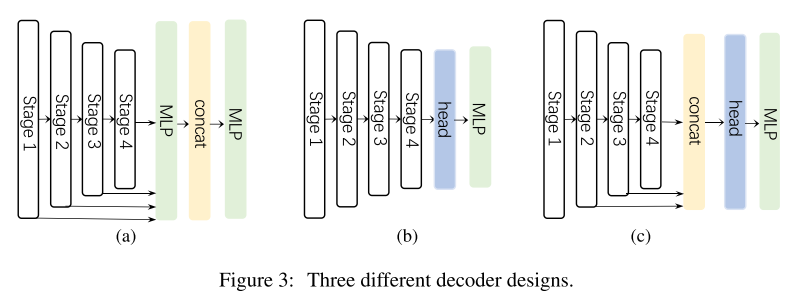
(a) Segformer (b) CNN-based models (c) decoder of SegNeXt (proposed)
마지막 세 개 stage로부터 가져와서 concat하고 'Hamburger'를 사용해 global context를 model한다. 첫번째 stage가 제외된 이유는 SegNeXt는 convolution이기 때문에 첫 stage의 정보는 너무 low-level 정보라서 성능을 저해하고 연산적인 overhead를 피하기 위해서다.
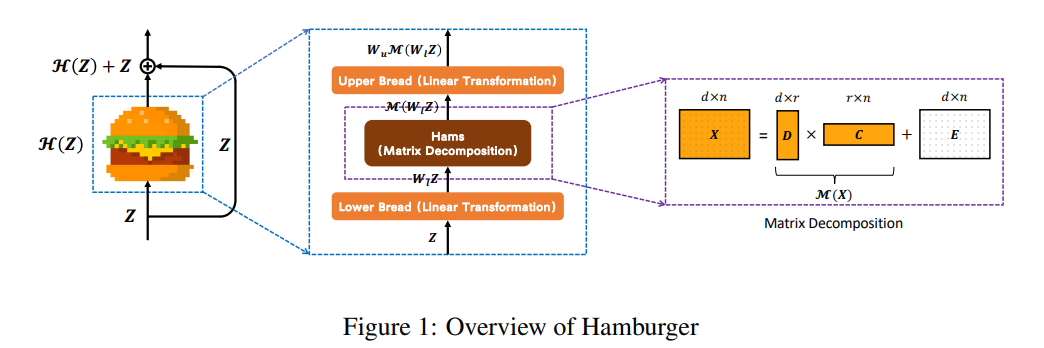
*Hamburger
self-attention 말고 matrix decomposition을 사용해 global context를 capture하도록 제안한 block. 이를 gradient로 풀 수 있도록 수학적으로 검토하고 알고리즘으로 구현한 것이 어려운 부분인데, 해당 논문 (https://arxiv.org/abs/2109.04553) 참고.
4. Experiements
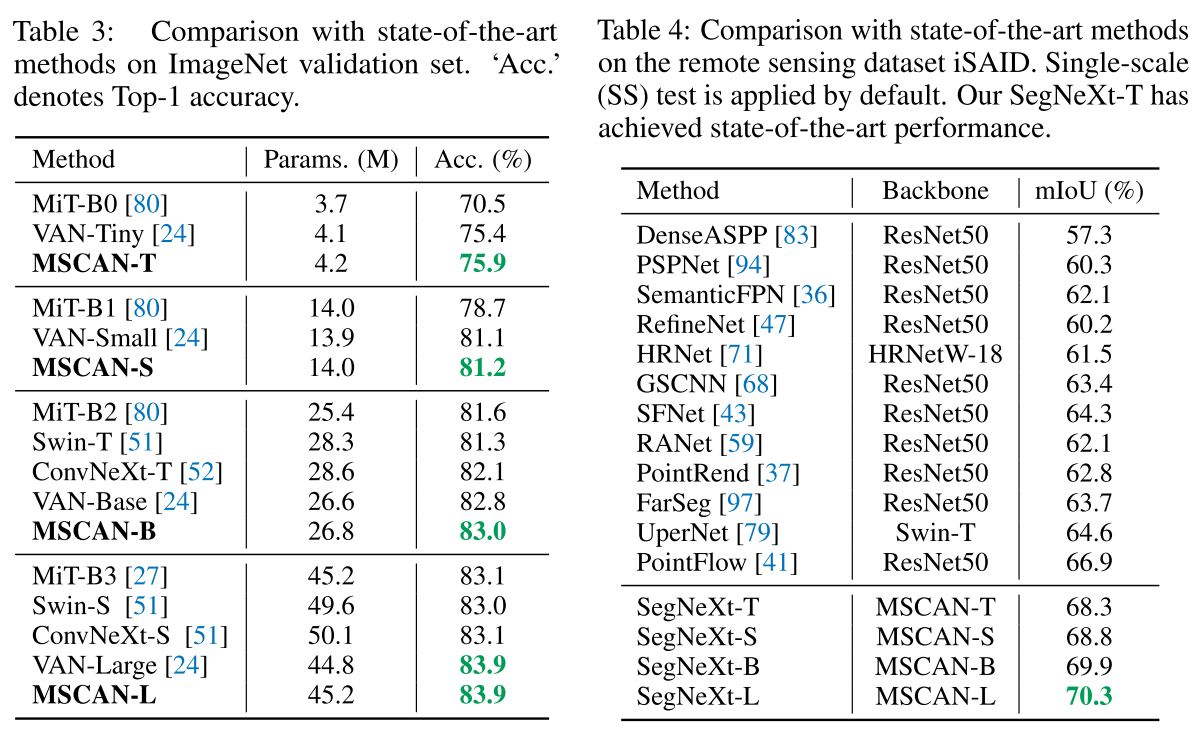
ImageNet validation set에서 top-1 accuracy로 유사한 크기 (Parameter)의 network 대비 더 높은 성능을 보였고, remote sensing dataset iSAID에서 높은 성능으로 SOTA를 달성함.
4.2. Ablation study
- Ablation on MSCA design

MSCA에서 component별로 성능 추이 비교한 건데, 7x7 kernel만 있을때랑 1x1 Conv 없었을 때 성능이 가장 떨어지긴 함. Attention은 구해진 값을 원래 feature input에 다시 element-wise로 곱해주는 operation인데, 가장 성능 차이가 적은 것으로 보임.
- Global Context for Decoder
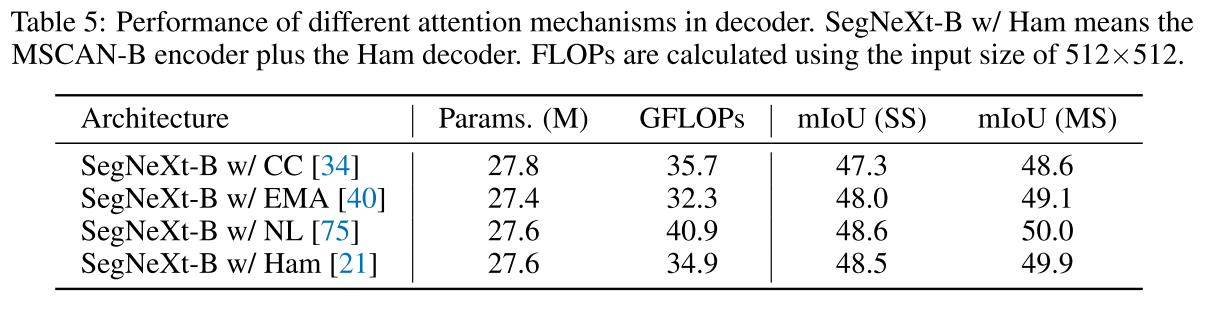
decoder 쪽에서 global context를 다시 integation해주는 알고리즘을 비교해봤는데, NL (non-local) attention은 O(N^2)의 연산복잡도를 가지고 CCNet, EMANet, HamNet은 O(N^2) 복잡도인데, Ham이 가장 나은 trade-off를 보여서 사용했다고 함.
- Decoder Structure
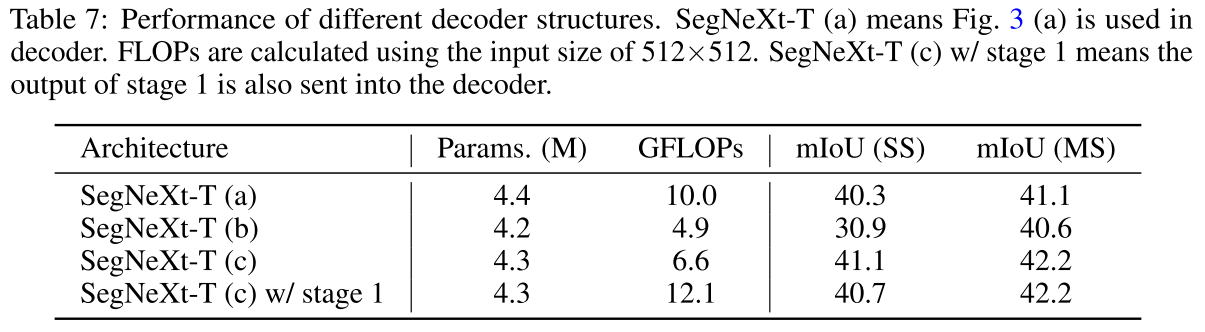
Figure 3의 (a), (b), (c)의 decoder structure를 비교해보았을 때, stage 1을 안 사용한 (c)가 가장 좋았다고 함. (b)는 high-resolution feature 정보를 사용 안 해서 성능 저하가 당연하고 (a)는 그냥 MLP만 사용하고 당연히 성능이 더 나오진 않음..
- Importance of Our MSCA
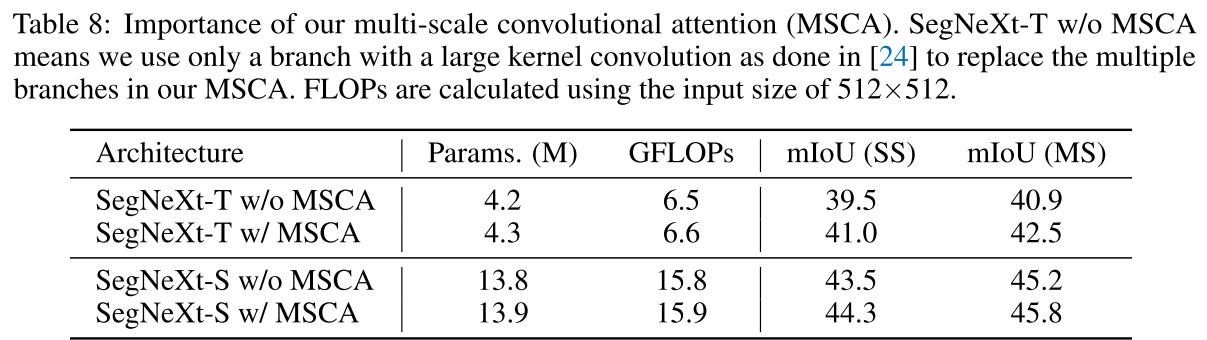
encoder에서 VAN에 구현된 것처럼 large kernel convolution 하나만 사용하는 것보다 multi-scale의 정보를 interaction하는 MSCA를 사용하는 것이 아주 작은 파라미터수와 FLOPs 증가 대비 segmentation 성능에 확실히 큰 영향을 미치는 것으로 보임.
Comments
제안한 encoder가 ImageNet에서도 파라미터 수 대비 좋은 성능을 보였지만, single object에 대한 이미지 classification과 달리, 다양한 크기의 여러 object들을 찾아야하는 semantic segmentation에서는 feature learning 과정에서도 multi-scale interaction하는 것이 특히 효과적이고, decoder에서도 multi-scale feature를 가져와 사용하는 것이 효과적이고 한 번 더 global context를 찾아내기 위한 모듈을 사용하는 게 성능에 더 나은 영향이 보이더라.
decoder쪽에서 global information을 capture하는 걸 efficient한 transformer 계열로 해볼 수 있었지만, Hamburger라는 대체적인 알고리즘으로 transformer 계열은 피한 것으로 보임.
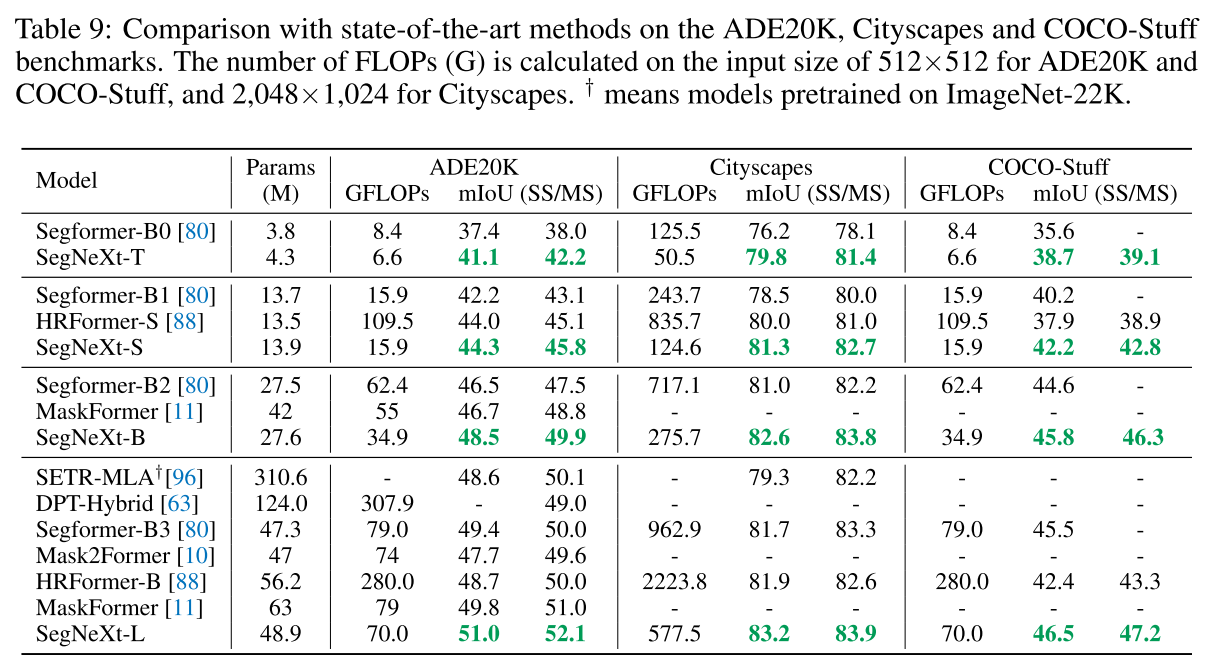
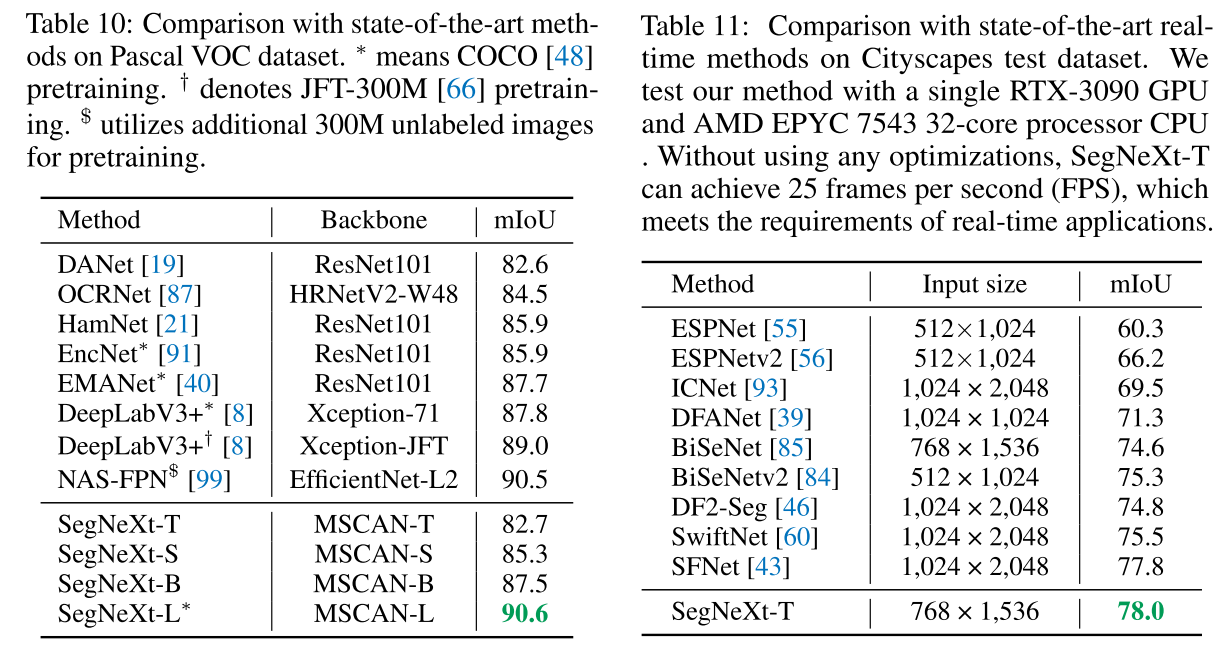
여러 벤치마크 데이터셋 및 다양한 알고리즘들과 single-scale 및 multi-scale test를 수행해 성능을 비교하여 우수함을 입증하였고, STCNet (AAAI 2024) 에서도 parameter 수 대비 좋은 성능을 보인 것으로 보면 잘 설계되고 입증된 network architecture 인 것으로 보임.
