
colab link
1. 데이터 준비하기
-
이진 분류
분류 : 여러 개의 종류(클래스) 중 하나를 구별해 내는 문제
2개의 클래스 중 하나를 고르는 문제를 이진분류라 함. -
특성
데이터의 특징 (현재 각 도미의 특징은 길이와 무게)
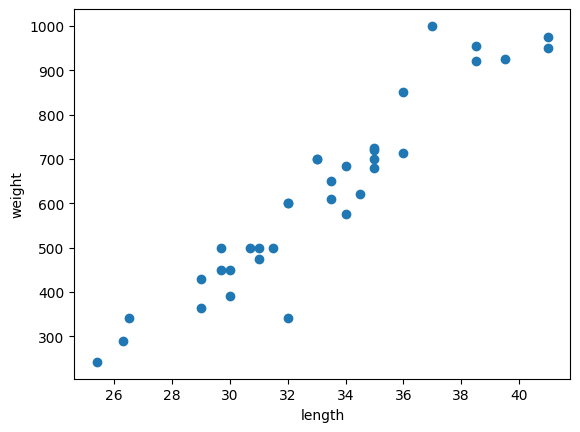
1) 도미 데이터 준비
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]2) 산점도 그리기
맷플롯립에서 scatter() 함수를 이용해 산점도 그래프 그리기
3) 빙어 데이터 준비 및 2개의 산점도 그리기
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]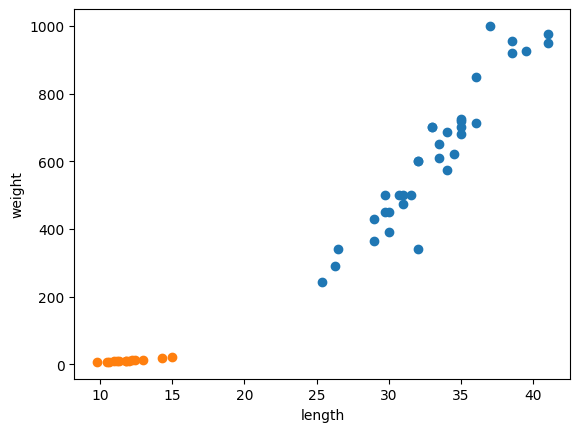
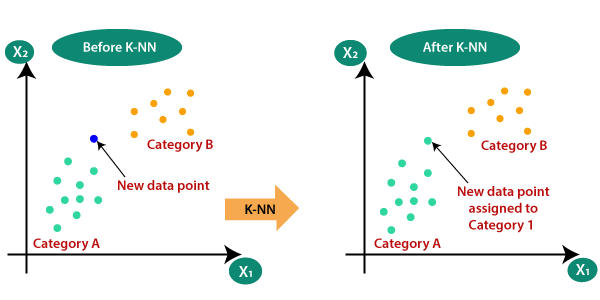
2. k-최근접 이웃 알고리즘
- k-최근접 이웃 알고리즘
주변의 가장 가까운 k개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘이 k 최근접 이웃 알고리즘
3. 훈련하기
- 사이킷런
사용하는 머신러닝 패키지, 2차원 리스트를 필요로 함
fish_data = [[l,w] for l,w in zip(length, weight)] #1번째 열이 길이, 2번째 열이 무게인 2차원 리스트 생성- 정답 데이터
머신러닝 알고리즘이 생선의 길이와 무게를 보고 도미와 빙어를 구분하는 규칙을 찾기 위해선 적어도 어떤 생선이 도미인지 빙어인지를 알려주어야 함
fish_target = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0]- k-최근접 이웃 알고리즘
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier() #KNeighborsClassifier의 객체 생성이 객체에 fish_data와 fish_target을 전달해 도미를 찾기 위한 기준 학습 (훈련)
fit() 메소드는 주어진 데이터로 알고리즘을 훈련
kn.fit(fish_data, fish_target)사이킷런에서 모델을 평가하는 메서드는 score() 메소드, 정확도를 출력
kn.score(fish_data, fish_target)
#result = 1.0 predict() 메소드는 새로운 데이터의 정답을 예측. 리스트의 리스트를 전달해야 함
kn.predict([[30, 600]])
#result = array([1])k-최근접 이웃 알고리즘이 새로운 데이터를 예측할 대 직선거리에 어떤 데이터가 있는지를 살핌. 단점은 k-최근접 이웃 알고리즘의 이런 특징 때문에 데이터가 아주 많은 경우 사용이 어려움.
n_neighbors()는 참고하는 가까운 데이터 수, KNeighborsClassifer 클래스의 기본값은 5개이다.

for well-being we need nectar and ambrosia