colab link
1. 데이터 전처리
알고리즘들은 샘플간의 거리에 영향을 많이 받으므로 제대로 사용하려면 특정값을 일정한 기준으로 맞춰 주어야 함.
Data preprocessing can refer to manipulation or dropping of data before it is used in order to ensure or enhance performance, and is an important step in the data mining process.
표준 점수
표준편차의 몇배만큼 떨어져 있는지를 나타낸다. 이를 통해 실제 특성값의 크기와 상관없이 동일한 조건으로 비교할 수 있다. (즉, x축과 y축을 동일한 조건으로 비교가 필요)
- 결측치 missing value 처리
- 범주형 변수 categorical data 처리
- Feature Scaling
1. 데이터 준비하기
- 사이킷런으로 훈련세트와 테스트 세트 나누기
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify= fish_target, random_state=42)- k-최근접 이웃 훈련 오류
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
import matplotlib.pyplot as plt
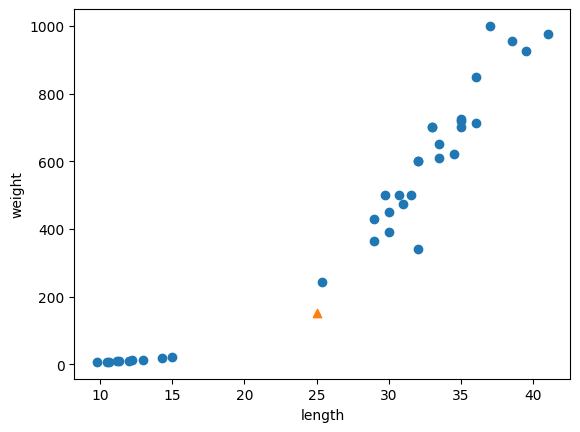
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()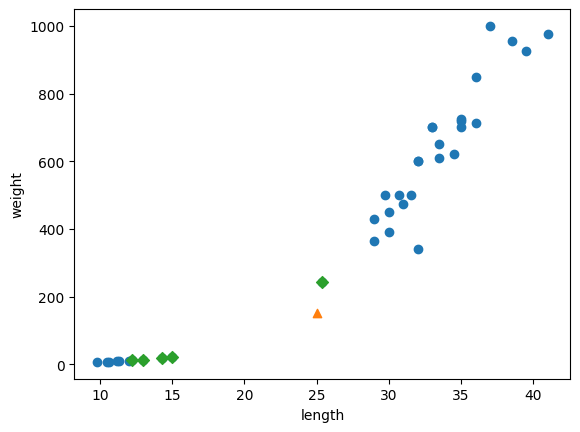
x축과 y축의 범위 스케일이 달라 잘못된 k-최근접 이웃 선택됨. 오로지 생선의 무게(y축)만 고려대상이 됨
2. Feature Scaling
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis = 0)
train_scaled = (train_input - mean) / std3. 전처리 데이터로 모델 훈련하기
new = ([25, 150] - mean) / std
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()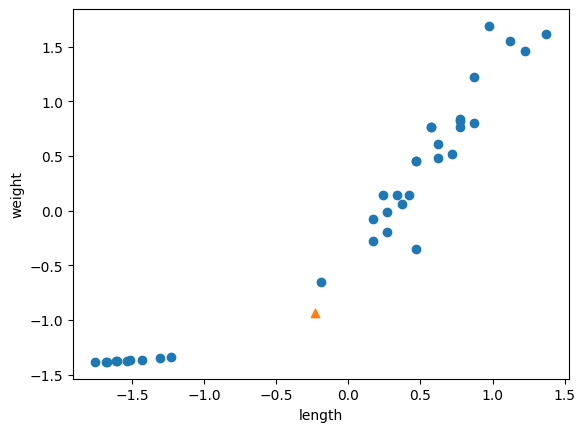
kn.fit(train_scaled, train_target)
test_scaled = (test_input - mean)/std테스트 세트도 훈련세트의 평균과 표준편차로 변환해야 한다. 테스트도 동일한 스케일로 맞추기 위해 '훈련세트' 스케일(평균, 표준편차) 사용해야 된다.
kn.score(test_scaled, test_target)
print(kn.predict([new]))
distances, indexes = kn.kneighbors([new])
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()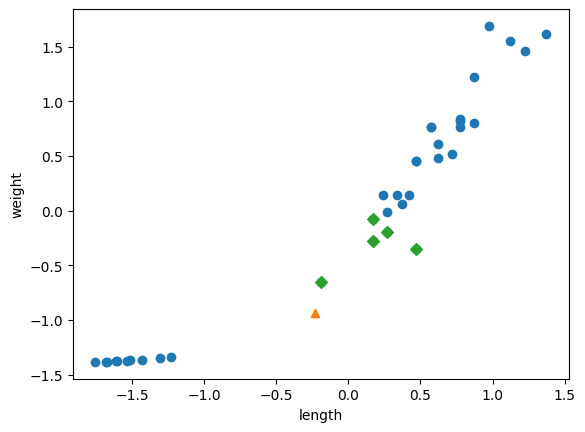

for well-being we need nectar and ambrosia