오늘은 텍스트 전처리와 + 순환 신경망 실습
colab link
Classifying IMDB Reviews using Recurrent Neural Networks
1. IMDB 리뷰 데이터셋
텍스트 데이터(비구조화된 데이터)를 머신러닝 모델이 처리하기 위해서는 구조화된 데이터로 변환이 필요하다. 각 단어는 숫자로 매핑이 된다.
이렇게 분리된 단어를 토큰이라고 부른다. (영어에서는 토큰을 단어와 같게 봐도 되지만 한국어에서는 다르다는 것을 유의하자)
- 데이터 로드
텐서플로에는 이미 텍스트가 정수로 바꿔진 데이터가 포함(텍스트 전처리가 된)되어 있다.
from tensorflow.keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(
num_words=300
)이때 num_words는 최대 300개의 단어만 사용해, 300개에 포함되지 않는 훈련세트의 데이터(단어)들은 반영되지 않는다.
- 데이터 분포
print(train_input[0])[Output]
[1, 14, 22, 16, 43, 2, 2, 2, 2, 65, 2, 2, 66, 2, 4, 173, 36, 256, 5, 25, 100, 43, 2, 112, 50, 2, 2, 9, 35, 2, 284, 5, 150, 4, 172, 112, 167, 2, 2, 2, 39, 4, 172, 2, 2, 17, 2, 38, 13, 2, 4, 192, 50, 16, 6, 147, 2, 19, 14, 22, 4, 2, 2, 2, 4, 22, 71, 87, 12, 16, 43, 2, 38, 76, 15, 13, 2, 4, 22, 17, 2, 17, 12, 16, 2, 18, 2, 5, 62, 2, 12, 8, 2, 8, 106, 5, 4, 2, 2, 16, 2, 66, 2, 33, 4, 130, 12, 16, 38, 2, 5, 25, 124, 51, 36, 135, 48, 25, 2, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 2, 16, 82, 2, 8, 4, 107, 117, 2, 15, 256, 4, 2, 7, 2, 5, 2, 36, 71, 43, 2, 2, 26, 2, 2, 46, 7, 4, 2, 2, 13, 104, 88, 4, 2, 15, 297, 98, 32, 2, 56, 26, 141, 6, 194, 2, 18, 4, 226, 22, 21, 134, 2, 26, 2, 5, 144, 30, 2, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 2, 88, 12, 16, 283, 5, 16, 2, 113, 103, 32, 15, 16, 2, 19, 178, 32]1은 문장의 시작, 2는 어휘사전에 없는 토큰을 가리킴. (앞서 봤던 300개에 포함되지 않는 단어들)
- target 데이터
리뷰 데이터를 보고 감정 분류하려고 함(긍정/부정)
print(train_target[:20][Output]
[1 0 0 1 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 1]- 단어 길이
리뷰의 길이가 편향되어 있음
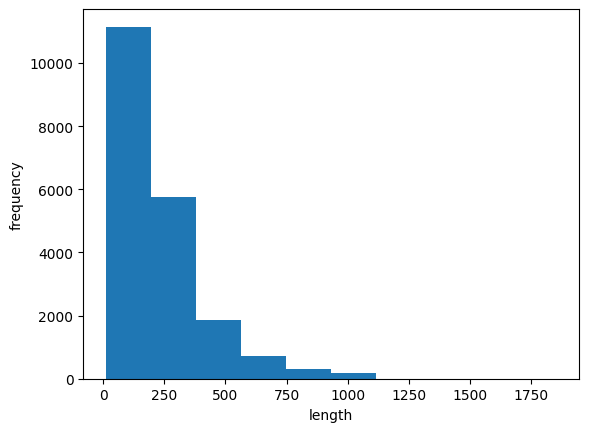
시퀀스 데이터의 길이를 맞추는 pad_sequences 함
모든 train_input의 길이를 100으로 맞춰줄거임
(1) 단어의 길이 < 100
0으로 패딩 추가
[Output]
[ 0 0 0 0 1 2 195 19 49 2 2 190 4 2 2 2 183 10
10 13 82 79 4 2 36 71 269 8 2 25 19 49 7 4 2 2
2 2 2 10 10 48 25 40 2 11 2 2 40 2 2 5 4 2
2 95 14 238 56 129 2 10 10 21 2 94 2 2 2 2 11 190
24 2 2 7 94 205 2 10 10 87 2 34 49 2 7 2 2 2
2 2 290 2 46 48 64 18 4 2]처음에 0을 추가한다. 왜냐하면 시퀀스의 마지막에 있는 단어가 셀의 은닉상태에 가장 큰 영향을 미치게 되므로 마지막에 패딩을 추가하는 것은 일반적으로 선호되지 않는다
바꾸고 싶다면 padding 매개변수를 pre에서 post로 변경하면 된다.
(2) 단어의 길이 > 100
maxlen 보다 긴 시퀀스의 앞부분을 자른다. 일반적으로 시퀀스의 뒷부분의 정보가 더 유용하리라 기대하기 때문이다
[Output]
[ 10 4 20 9 2 2 2 5 45 6 2 2 33 269 8 2 142 2
5 2 17 73 17 204 5 2 19 55 2 2 92 66 104 14 20 93
76 2 151 33 4 58 12 188 2 151 12 215 69 224 142 73 237 6
2 7 2 2 188 2 103 14 31 10 10 2 7 2 5 2 80 91
2 30 2 34 14 20 151 50 26 131 49 2 84 46 50 37 80 79
6 2 46 7 14 20 10 10 2 158]뒷부분을 잘라내고 싶다면 truncating 매개변수의 값을 pre가 아닌 post로 변경하면 된다
2. 순환 신경망 만들기
IMDB 리뷰 분류 문제는 이진 분류이므로 마지막 출력층은 시그모이드 활성화함수를 사용한다. (평소의 softmax가 아닌)
순환신경망 구현을 위해 SimpleRNN 클래스를 사용한다. 완전연결 신경망은 Dense, 합성곱신경망은 Conv2D 클래스
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 300)))
model.add(keras.layers.Dense(1, activation='sigmoid'))하지만 이대로 진행할경우 텍스트가 변환된 숫자들에 그대로 가중치가 곱해진다는 문제점이 있다. 변환들 숫자들 간에는 아무런 관계가 없지만 가중치가 곱해질 경우 특정 단어가 지나치게 강조될 수도 있다. 따라서 상관관계가 없도록 텍스트 전처리가 필요하다.
- 원-핫 인코딩
정수값을 배열에서 해당 정수 위치의 원소만 1이고 나머지는 모두 0으로 변환한다.
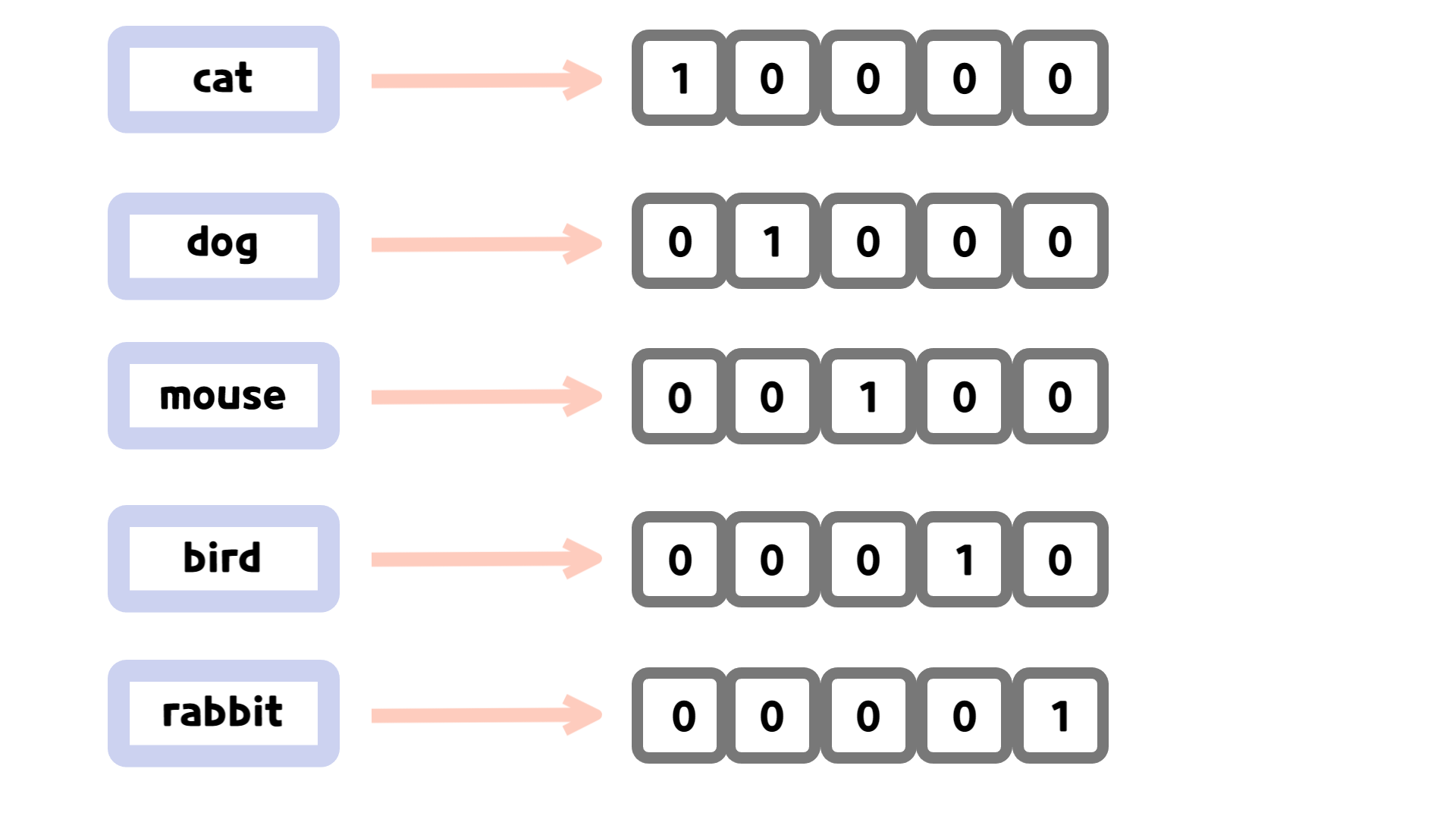
이미지 출처 : https://velog.io/@pheol9166/%EC%9B%90-%ED%95%AB-%EC%9D%B8%EC%BD%94%EB%94%A9One-hot-Encoding300개의 단어만 사용하도록 지정했기 때문에 훈련데이터에 포함될 수 있는 정수값의 범위는 0에서 299까지이고, 300개 중에 하나만 1이고 나머지는 모두 0으로 만든다. 즉, 각 숫자(단어) 하나마다 모두 300차원 배열로 변경되기 때문에 train 세트 크기는 (2000, 100, 300으로 변한다.
model_summary()
[Output]
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ simple_rnn (SimpleRNN) │ (None, 8) │ 2,472 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense (Dense) │ (None, 1) │ 9 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 2,481 (9.69 KB)
Trainable params: 2,481 (9.69 KB)
Non-trainable params: 0 (0.00 B)2472
순환 신경망에 대해 입력의 크기는 300, 출력 뉴런 개수는 8개이다.
입력에 대해 8개 뉴런이 완전연결되므로 300 x 8=2400,
8개 뉴런의 출력 은닉값이 다시 8개의 뉴런으로 완전 연결되어 8 x 8 =64
300 x 8 + 8 x 8 + 8 = 2472
순환층의 은닉 상태는 다시 다음 스텝에 사용돼 또 다른 가중치와 곱해진다는 것을 잊지 말자
3. 순환 신경망 훈련하기
RMSprop(앞에서 배운 optimizer, 경사하강법 최적화의 학습률 0.0001로 설정, 에포크 횟수 100, 배치 크기는 64개로 훈련
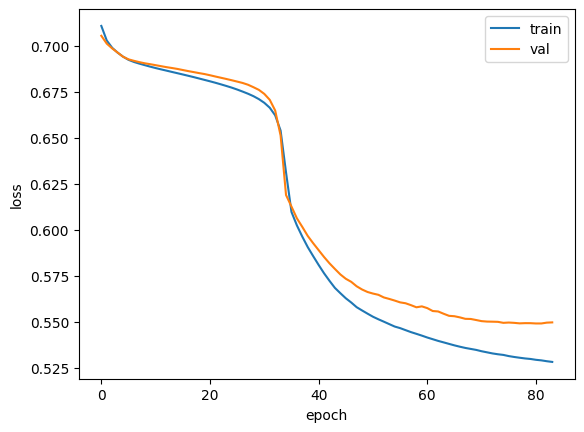
이게 맞나..? 제 코랩은 RAM이 부족해서 돌아가질 않음
검증세트의 정확도는 0.7330로 약 73%의 정확률을 보여줌.
4. 단어 임베딩을 사용하기
원-핫 인코딩의 단점은 입력 데이터가 엄청 커진다는 점이다. (내 코랩에서는 아예 돌아가질 못한다)
따라서 이러한 단점을 극복하기 위해 텍스트 처리에 단어 임베딩도 즐겨 사용한다. 각 단어를 고정된 크기의 실수 벡터로 바꾸어 준다
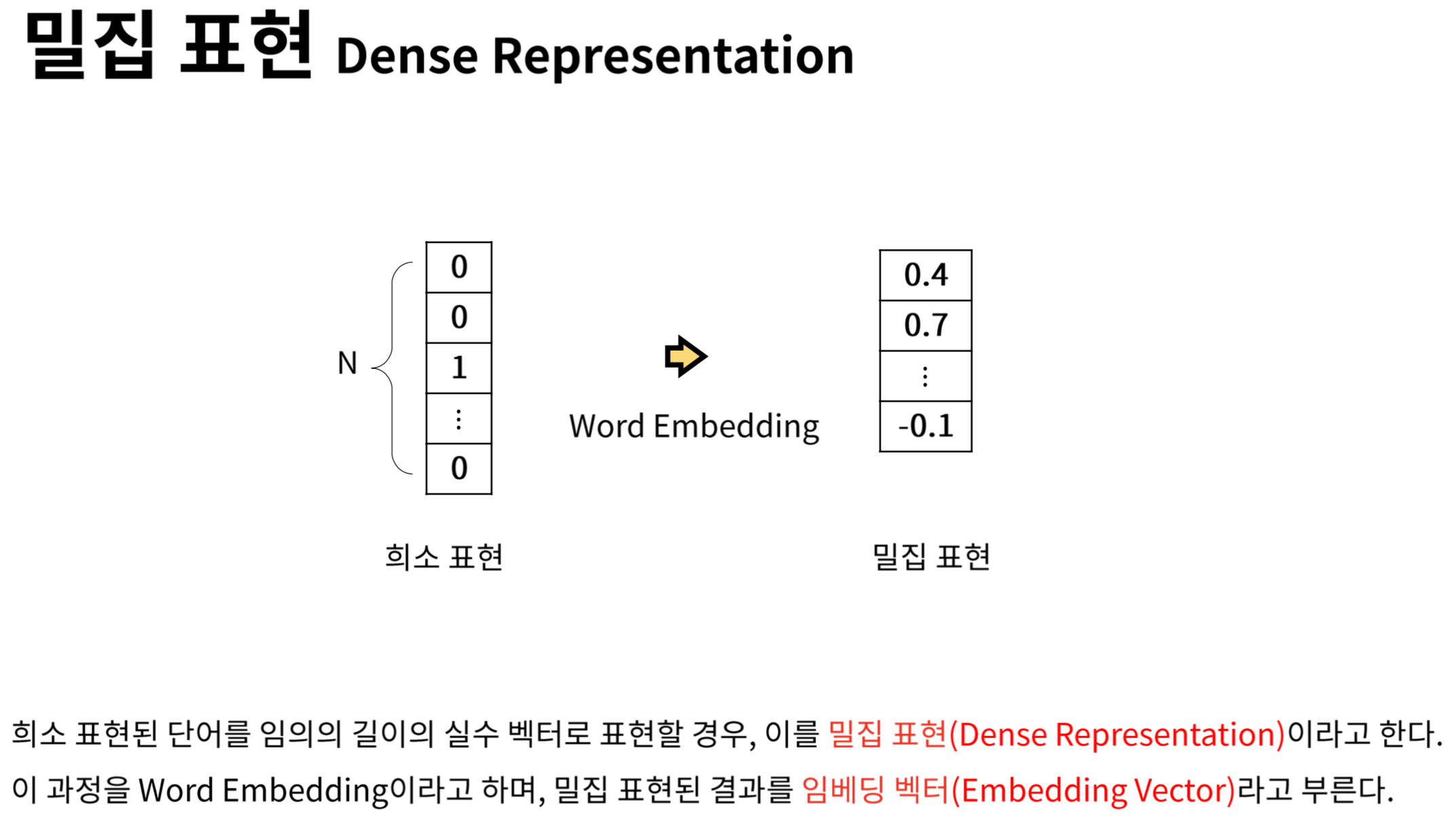
이미지 출처 : https://heung-bae-lee.github.io/2020/01/16/NLP_01/단어 임베딩으로 만들어진 벡터는 원-핫 인코딩된 벡터보다 훨씬 의미 있는 값ㅡ올 채워져 있기 때문에 자연어 처리에서 더 좋은 성능을 내는 경우가 많다.
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(200, 16, input_shape=(100,)))
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1, activation='sigmoid'))
model2.summary()Embedding 클래스의 첫번째 매개변수(300)은 어휘사전의 크기, 두번째 매개변수(16)은 임베딩 벡터의 크기, 3번째 input_length 매개변수는 입력 시퀀스의 길이이다.
훈련 과정은 원-핫 인코딩과 동일하다. 출력 결과(0.7395)를 보면 원-핫 인코딩과 비슷한 성능을 내지만 가중치 개수는 훨씬 작고 세트 크기도 훨씬 줄어들었다
[Output]
...
313/313 ━━━━━━━━━━━━━━━━━━━━ 6s 19ms/step - accuracy: 0.7350 - loss: 0.5323 - val_accuracy: 0.7308 - val_loss: 0.5423
Epoch 28/100
313/313 ━━━━━━━━━━━━━━━━━━━━ 10s 18ms/step - accuracy: 0.7352 - loss: 0.5313 - val_accuracy: 0.7296 - val_loss: 0.5418
Epoch 29/100
313/313 ━━━━━━━━━━━━━━━━━━━━ 6s 18ms/step - accuracy: 0.7367 - loss: 0.5303 - val_accuracy: 0.7294 - val_loss: 0.5415
Epoch 30/100
313/313 ━━━━━━━━━━━━━━━━━━━━ 5s 17ms/step - accuracy: 0.7369 - loss: 0.5294 - val_accuracy: 0.7290 - val_loss: 0.5415
Epoch 31/100
313/313 ━━━━━━━━━━━━━━━━━━━━ 6s 18ms/step - accuracy: 0.7387 - loss: 0.5287 - val_accuracy: 0.7306 - val_loss: 0.5413
Epoch 32/100
313/313 ━━━━━━━━━━━━━━━━━━━━ 10s 19ms/step - accuracy: 0.7385 - loss: 0.5279 - val_accuracy: 0.7310 - val_loss: 0.5415
Epoch 33/100
313/313 ━━━━━━━━━━━━━━━━━━━━ 10s 17ms/step - accuracy: 0.7394 - loss: 0.5273 - val_accuracy: 0.7316 - val_loss: 0.5416
Epoch 34/100
313/313 ━━━━━━━━━━━━━━━━━━━━ 6s 18ms/step - accuracy: 0.7395 - loss: 0.5268 - val_accuracy: 0.7322 - val_loss: 0.5417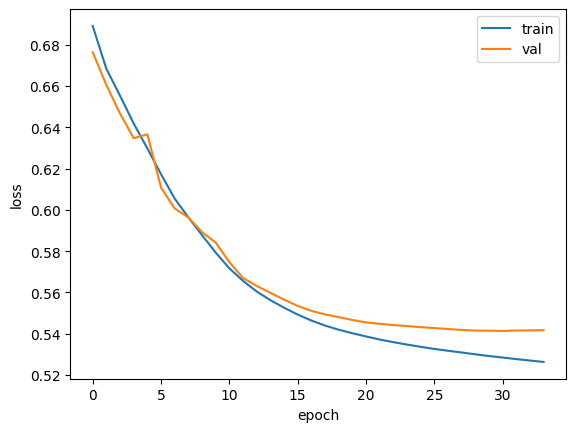

너무 머싯어요,,,,,,,,,