
I. 파이썬 기반의 머신러닝과 생태계 이해
01. 넘파이 🥧
넘파이는 파이썬에서 선형 대수 기반의 프로그램을 만들 수 있도록 지원하는 대표적인 패키지
a. ndarray 개요
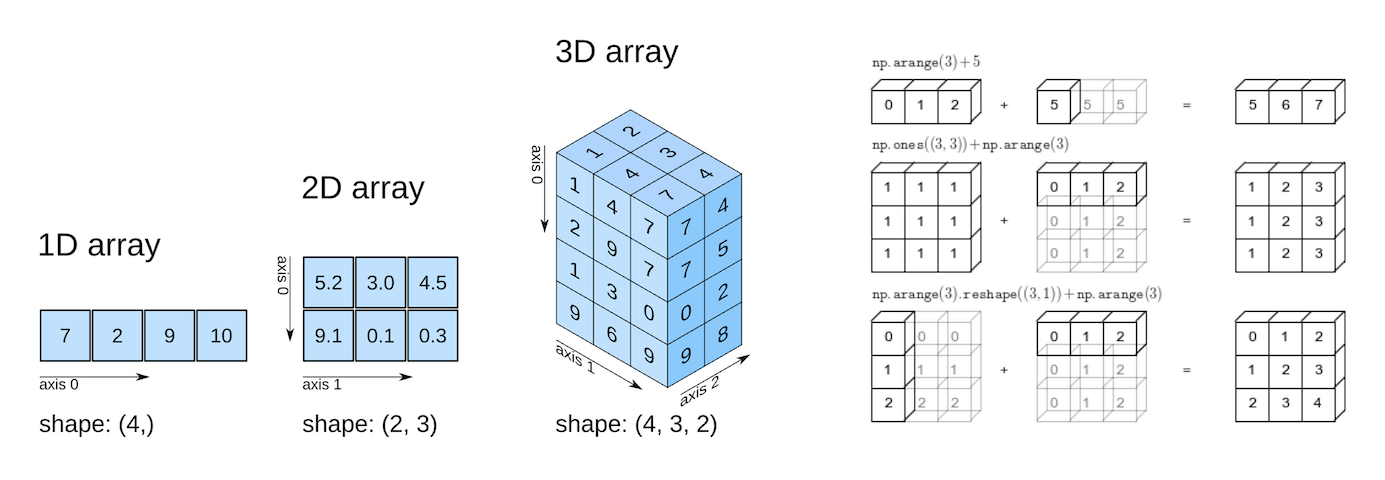
ndarry Numpy의 N차원 배열 객체
1차원 배열, 2차원 배열, 3차원 배열 ... 다차원 배열을 쉽게 생성하고 다양한 연산을 수행할 수 있음.
#ndarray
array1 = np.array([1,2,3])
print('array1 type:', type(array1))
print('array1 array 형태:',array1.shape)
array2 = np.array([[1,2,3], [2,3,4]])
print('array2 type:', type(array2))
print('array2 array 형태:', array2.shape)
array3 = np.array([[1,2,3]])
print('array3 type:', type(array3))
print('array3 array 형태:', array3.shape)- ndarray 데이터 타입
ndarray내의 데이터값은 숫자 값, 문자열 값, 불 값 모두 가능
ndarray 내의 데이터 타입은 특성상 같은 데이터 타입만 가능
타입 변환은 astype() 메서드를 이용해 가능
reshape()
ndarray를 특정 차원 및 크기로 변환한다. 모든 데이터를 주어진 행/열에 맞춰진 array를 반환한다. 단, 나누어떨어지지 않을 경우 Error가 발생한다.
#reshape
array1 = np.arange(10)
print('array1: \n', array1)
array2 = array1.reshape(2, 5)
print('array2: \n', array2)
array3 = array1.reshape(5, 2)
print('array3: \n', array3)b. indexing
- 특정 데이터만 추출
원하는 위치의 인덱스 값을 지정하면 해당 위치의 데이터가 반환
value = array1[2]- 슬라이싱
연속된 인덱스상의 ndarray를 추출하는 방식. 시작인덱스에서 종료 인덱스-1 위치에 있는 데이터의 ndarray를 반환
- 팬시 인덱싱
일정한 인덱싱 집합을 리스트 또는 ndarray 형태로 지정해 해당 위치에 있는 데이터의 ndarray를 반환
#fancy indexing
array1d = np.arange(start=1, stop=10)
array2d = array1d.reshape(3,3)
array3 = array2d[[0,1], 2]
print('array2d[[0,1],2] => ', array3.tolist())
array4 = array2d[[0,1], 0:2]
print('array2d[[0,1], 0:2] => ', array4.tolist())
array3 = array2d[[0,1]]
print('array2d[[0,1]] => ', array5.tolist())[Output]
array2d[[0,1], 2] => [3, 6]
array2d[[0,1], 0:2] => [[1, 2], [4, 5]]
array2d[[0,1], 2] => [[1, 2, 3], [4, 5, 6]]-불린 인덱싱
특정 조건에 해당하는 여부인 True/False 값 인덱싱 집합을 기반으로 True에 해당하는 인덱스 위치에 있는 데이터의 ndarray를 반환
#boolean indexing
array1d = np.arange(start=1, stop=10)
# [ ] 안에 array1d > 5 Boolean indexing을 적용
array3 = array1d[array1d > 5]
print('array1d > 5 불린 인덱싱 결과 값:', array3)array1d > 5 불린 인덱싱 결과 값 : [6 7 8 9]c. 행렬의 정렬
np.sort( )
넘파이에서 sort( )를 호출하는 방식
원 행렬을 그대로 유지한 채 원 행렬의 정렬된 행렬을 반환 (ndarry 원본 유지)
ndarray.sort( )
행렬 자체에서 sort( )를 호출하는 방식
원 행렬 자체를 정렬한 상태로 변환 (반환값 None/ ndarray 원본 대체)
np.argsort( )
정렬 행렬의 원본 행렬 인덱스를 ndarray 형으로 변환
#argsort
org_array = np.array([3, 1, 9, 5])
sort_indices = np.argsort(org_array)
print(type(sort_indices))
print('행렬 정렬 시 원본 행렬의 인덱스:', sort_indices)<class 'numpy.ndarray'>
행렬 정렬 시 원본 행렬의 인덱스 : [1 0 3 2]내림차순 정렬
[::-1]을 적용 -> np.argsort(org_array)[::-1]
argsort()는 넘파이에서 매우 활용도가 높다 반환된 인덱스를 팬시 인덱스로 적용해 추출할 수 있어 데이터 추출에서 많이 사용된다.
02. 판다스 🐼
판다스는 데이터 처리를 위해 존재하는 가장 인기 있는 라이브러리
판다스는 파이썬의 리스트, 컬렉션, 넘파이 등의 내부 데이터 뿐만 아니라 CSV 등의 파일을 쉽게 DataFrame으로 변경해 데이터 가공/분석을 편리하게 수행
- Pandas 핵심 개체
DataFrame은 여러개의 행과 열로 이뤄진 2차원 데이터를 담는 데이터 구조체
- Series와 DataFrame
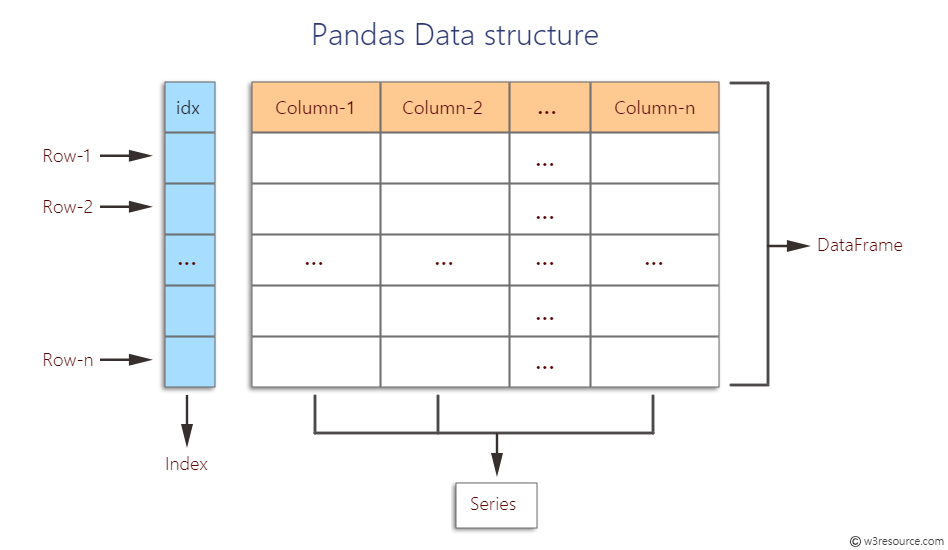
Series 칼럼이 하나뿐인 데이터 구조체
DataFrame 칼럼이 여러 개인 데이터 구조체 (여러 개의 Series)
a. 판다스 시작, 파일을 DataFrame로 로딩
- 판다스 모듈 임포트
Import pandas pdpd.read_csv( )
csv 파일 포맷을 위한 API
디폴트 필드 구분 문자 : ,
Sep 인자를 활용 (sep='\t')
DataFrame.head( )
DataFrame 맨 앞에 있는 N개 row 반환 (default : 5)
DataFrame.info( )
총 데이터 건수와 칼럼별 데이터 타입, null 건수
titanic_df.info()[Output]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KBDataFrame.describe( )
숫자형 칼럼에 대한 개략적인 데이터 분포도
(non-null 건수, mean, std, min, max, quantile)
titanic_df.describe()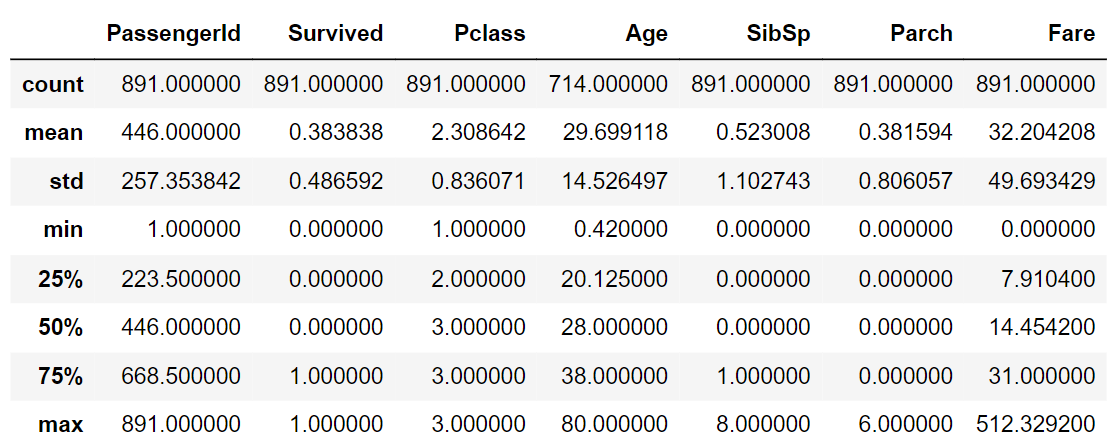
DataFrame[‘열].value_counts( )
해당 칼럼값의 유형과 건수 확인
많은 건수 순서로 정렬되어 값을 반환
해당 칼럼에 해당되는 Series 객체를 반환 (따라서 type가 Series이다)
value_counts = titanic_df['Pclass'].value_counts()순차 값과 같은 의미없는 식별자만 할당하는 것이 아닌 고유성이 보장된다면 의미 있는 데이터 값 할당도 가능 (모든 인덱스의 고유성 보장)
b. DataFrame과 리스트, 딕셔너리, 넘파이 ndarray 상호 변환
기본적으로 넘파이 ndarray를 입력인자로 사용하는 경우가 빈번
DataFrame과 넘파이 ndarray 상호 간의 변환은 매우 빈번하게 발생
- 넘파이 ndarray, 리스트, 딕셔너리를 DataFrame으로 변환
(1) ndarray -> DF
import numpy as np
col_name1 = ['col1']
list1= [1,2,3]
array1 = np.array(list1)
print('array1 shape: ', array1.shape)
#리스트를 이용해 DataFrame 생성
df_list1= pd.DataFrame(list1, columns = col_name1)
print('1차원 리스트로 만든 DataFrame:\n', df_list1)
#넘파이 ndarray를 이용해 DataFrame 생성
df_array1 = pd.DataFrame(array1, columns = col_name1)
print('1차원 ndarray로 만든 DataFrame:\n', df_array1)(2) list -> DF
#3개의 칼럼명이 필요함
col_name2 = ['col1', 'col2', 'col3']
#2행x3열 형태의 리스트와 ndarray 생성한 뒤 이를 DataFrame로 변환
list2= [[1,2,3],
[11, 12, 13]]
array2= np.array(list2)
print('array2 shape:', array2.shape)
df_list2 = pd.DataFrame(list2, columns=col_name2)
print('2차원 리스트로 만든 DataFrame:\n', df_list2)
df_array2 = pd.DataFrame(array2, columns=col_name2)
print('2차원 ndarray로 만든 DataFrame:\n', df_array2)(3) dictionary -> DF
#Key는 문자열 칼럼며으로 매핑, Value는 리스트형(또는 ndarray) 칼럼 데이터로 매핑
dict= {'col1':[1,11], 'col2':[2,22], 'col3':[3,33]}
df_dict = pd.DataFrame(dict)
print('딕셔너리로 만든 DataFrame:\n', df_dict)c. DataFrame의 칼럼 데이터 세트 생성 수정
- [ ] 연산자 이용
DataFrame[‘열‘] = 숫자
DataFrame[‘열'] = 수식
기존 칼럼값도 쉽게 일괄적으로 업데이트할 수 있음
titanic_df['Age_by_10'] = titanic_df['Age_by_10']+100d. DataFrame 데이터 삭제
DataFrame.drop( )
Labels drop할 칼럼이나 행 지정 ([ ] 안에 넣어서 입력)
Axis 특정 칼럼 또는 행 drop (axis=0: row, axis=1: column)
inplace drop한 데이터프레임을 원본으로 저장 (default: False)
inplace True 일 경우 반환값 None/ 원본이 새로운 DF로 대체됨.
drop() 메서드가 사용되는 대부분의 경우는 칼럼을 드롭하는 경우
e. Index 객체
Index 객체는 식별성 데이터를 1차원 array로 가지고 있음
DataFrame.index
DataFrame의 인덱스 객체 추출
DataFrame.index.values
DataFrame의 인덱스 객체를 실제 값 array로 변환
Index는 연산용이 아닌 오직 식별용으로만 사용
DataFrame.reset_index( )
DataFrame 인덱스를 새롭게 연속 숫자형 (0~)으로 할당 (고유 인덱스 잃어버림)
기존 인덱스 ‘index’라는 새로운 칼럼명으로 추가
drop 기본 인덱스를 새로운 칼럼으로 추가하지 않고 삭제 (default = False)
inplace reset_index한 데이터프레임을 원본으로 저장(default = False)
c. 데이터 셀렉션 및 필터링
[ ]연산자
DataFrame의 칼럼만 지정하는 ‘칼럼 지정 연산자‘
[ ] 는 칼럼만 지정할 수 있는 칼럼 지정 연산자로 이해하기
단일 칼럼 추출
titanic_df['Pclass']여러 칼럼 추출
[ ] 안에 해당 칼럼들이 포함된 [ ] 입력
titanic_df[['Survived', 'Pclass']]불린 인덱싱 가능
titanic_df[titanic_df['Pclass']==3].슬라이싱 연산으로 추출하는 방법은 사용하지 않는 게 좋음
DataFrame.iloc[ ]
위치 기반 인덱싱
행과 열 값으로 integer 혹은 integer형의 슬라이싱, 팬시 인덱싱만 가능
칼럼 명칭을 입력하면 오류 발생
불린 인덱싱은 제공하지 않음
Data_df.iloc[0, 0]DataFrame.loc[ ]
명칭 기반으로 데이터를 추출한다
loc[인덱스 값, 칼럼명] 와 같은 형식으로 데이터를 추출할 수 있다.
data_df.log['one', 'Name']- 불린 인덱싱
매우 편리한 데이터 필터링 방식이자 자주 사용되는 방식
[ ] 연산자와 DataFrame.loc[ ] 사용
복합 조건 결합해 사용 가능 (&, |, ~)
[ ] 연산자의 경우 : DataFrame[[조건][열 이름들]]titanic_df[titanic_df['Age'] > 60][['Name’, ‘Age’]].loc[ ]의 경우: DataFrame loc[[조건], [열 이름들]]
titanic_df.loc[titanic_df[‘Age’] > 60, [‘Name’, ‘Age’]]
d. 정렬, Aggregation 함수, GroupBy 적용
DataFrame.sort_values( )
DataFrame과 Series 정렬
by 정렬의 기준이 될 열(들)을 리스트형으로 입력
ascending 오름차순으로 정렬 여부 (default: True)
inplace 정렬한 데이터프레임을 원본으로 저장 (default : false)
titanic_sorted = titanic_df.sort_values(by=['Pclass', 'Name'], ascending=False)- Aggregation 함수
기본 연산을 도와주는 함수들의 집합 (min, max, sum, median, count)
DataFrame 전체 혹은 특정 칼럼들에 해당 aggregation 적용
전체 칼럼들 데이터프레임 뒤에 함수 적용
titanic_df.count()특정 칼럼들 데이터프레임[[칼럼들]] 뒤에 함수 적용
titanic_df[[‘Age’, ‘Fare’]].mean( )Axis 설정에 따라 적용되는 방향 달라짐(axis =0: 행/ axis =1: 열)
- DataFrame.groupby( )
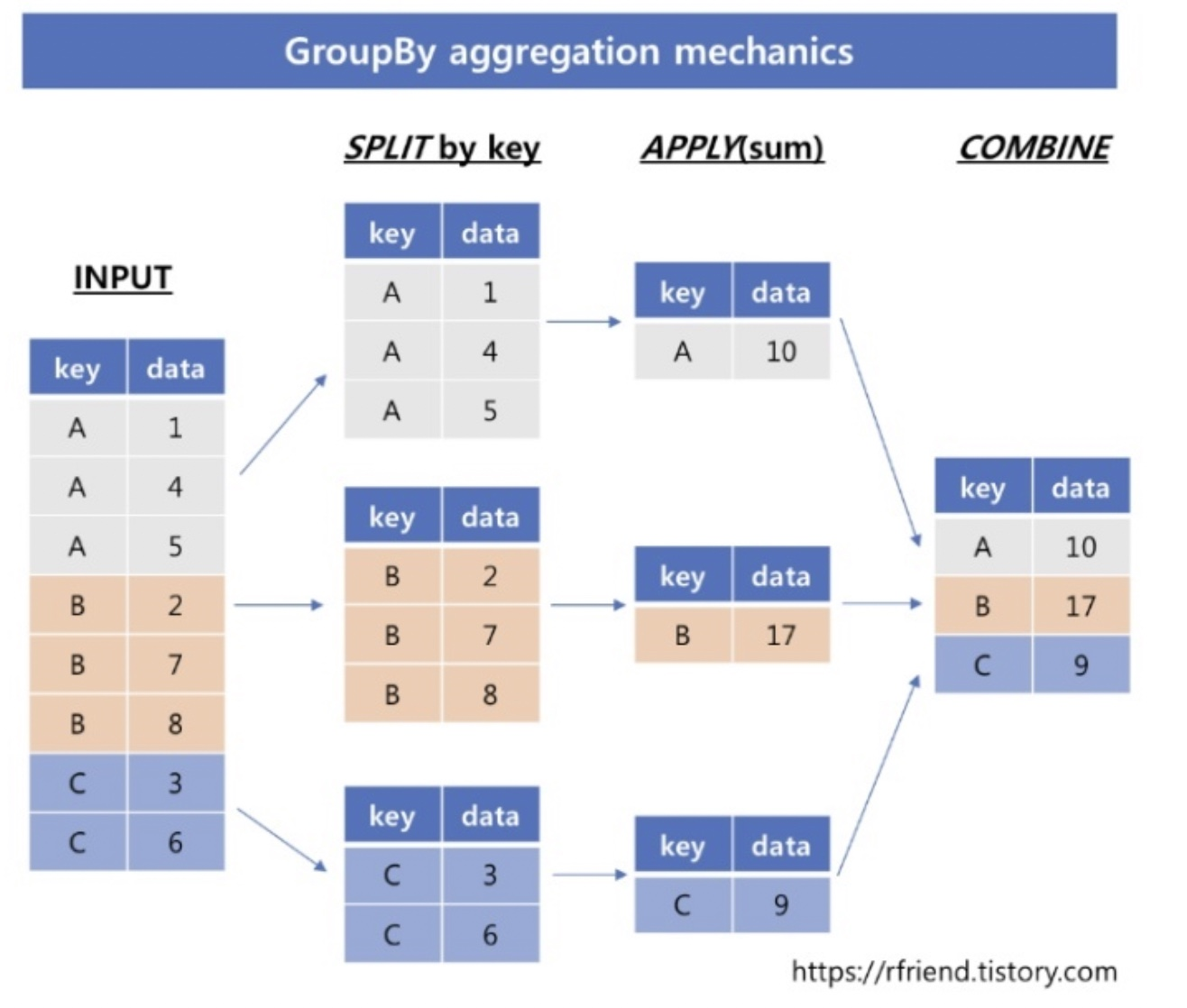
입력 파라미터 by에 칼럼을 입력하면 대상 칼럼을 groupby
반환된 DataFrame Groupby 객체에 aggregation 함수를 호출
groupby( ) 대상 칼럼을 제외한 모든 칼럼에 해당 aggregation 함수 적용
특정 칼럼들에만 적용
.groupby()[열].함수( ) , .groupby( )[[열들]].함수( )
.agg( ) 을 이용해 여러 개의 aggregation 함수 적용
하나의 칼럼에 여러 개의 함수: .agg([함수들])
titanic_df.groupby('Pclass')['Age'].agg([max, min])칼럼에 따라 서로 다른 함수
.agg(dic())
agg_format = {'Age':'max', 'SibSp':'sum', 'Fare':'mean'}
titanic_df.groupby('Pclass').agg(agg_format)e. 결손 데이터 처리하기
결손 데이터는 칼럼에 값이 없는 NULL인 경우를 의미하며 넘파이의 NaN으로 표시. 기본적으로 머신러닝 알고리즘은 NaN값을 처리하지 않음
DataFrame.isna( )
모든 칼럼 값이 NaN인지 아닌지 true/false로 반환
결손 데이터 개수를 확인하기 위해서는 DataFrame.isna( ).sum( )
DataFrame.fillna( )
결손 데이터를 다른 값으로 대체 가능
특정 칼럼에 대해서만 적용
DataFrame[열].filllna() , DataFrame[[열]].fillna( )
-> Inplace = True 혹은 다른 이름으로 저장해야 filna( ) 실행 값 저장됨
f. lambda 식으로 데이터 가공
Apply lambda 식으로 데이터 가공
일괄적으로 데이터 가공을 하는 것이 빠르나 복잡한 데이터 가공이 필요할 경우 apply lambda를 이용
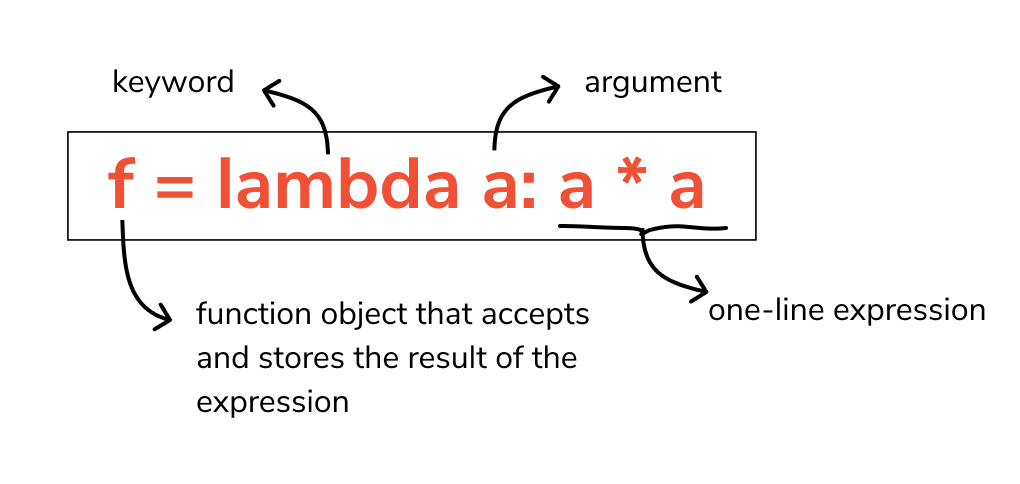
- Lambda
함수의 선언과 함수 내의 처리를 한 줄로 변환한 식
DataFrame.apply(lambda 식)
특정 칼럼에 대해서만 적용
DataFrame[열].apply( ) `DataFrame[[열]].apply( )`If else문 list comprehension 사용
너무 길어질 경우 따로 함수 정의하는 것도 방법
lambda x : 'Child' if x <=15 else 'Adultif절의 경우 반환 값이 식보다 먼저 나옴
