
📖 문제


📝 풀이 과정
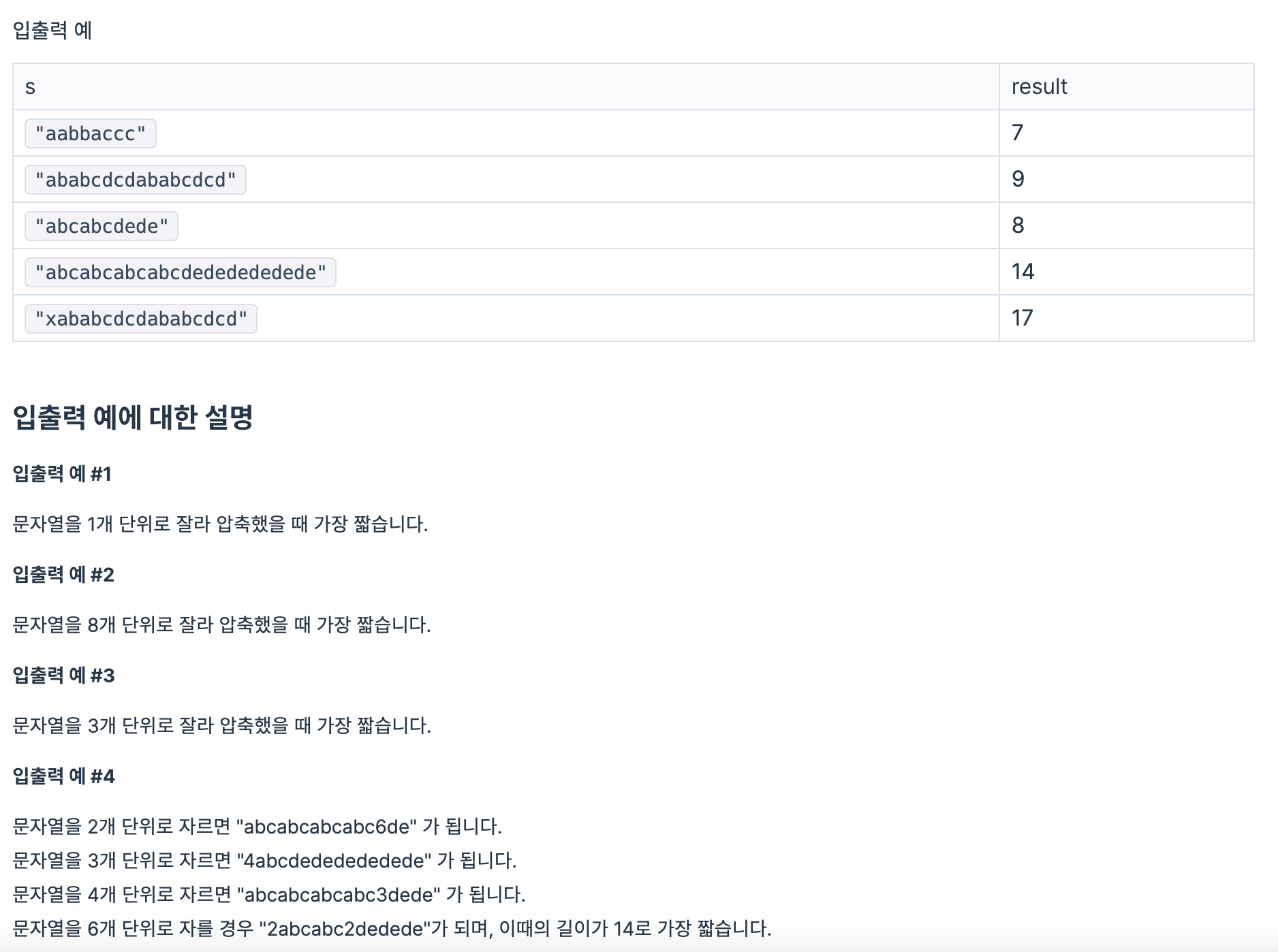
- 압축 단위가 문자열
s의 길이의 1/2을 넘으면 압축이 안되기 때문에 압축 단위의 범위는1 ~ len(s)//2이다. 이 범위를 모두 순회하여 모든 경우의 수를 구한다. (완전 탐색) <- 문자열s의 최대 길이가 1000이어서 가능 - 압축 기준이 되는 문자열을 잡아서 압축이 가능한지 검사한다.
unit단위로 압축 기준이 되는 문자열을 잡는다.- 바로 다음에 나오는
unit단위의 문자열들과 기준 문자열을 비교한다.
2 - 1. 같다면 압축이 가능하므로 압축되는 문자열의 개수를 세는 변수cnt를 1 증가
2 - 2. 다르다면 압축이 불가능하므로 이전까지 압축한 문자열을tmp_cmpr_str에 조건에 맞게 담고 압축 기준을 다음unit단위 문자열로 갱신한다.
unit단위로 압축한 문자열의 길이를length에 담는다.- 모든 압축 단위 범위에 대해 검사한 후
length에 있는 문자열의 길이 중 가장 짧은 길이를 구한다.
⌨ 코드
def solution(s):
# 1~half_len의 단위로 압축한 문자열들을 담을 리스트
length = []
# 압축 단위는 주어진 문자열 s의 길이의 절반을 넘어갈 수 없다.
half_len = len(s) // 2
# 문자열 s의 길이가 1인 경우 압축할 수 없다.
if len(s) == 1:
return 1
# unit은 압축 단위
for unit in range(1, half_len+1):
cnt = 1
# 문자열 s를 unit단위로 압축한 문자열이 담긴다.
tmp_cmpr_str = ""
# 현재 압축 기준이 되는 문자열
cur_str = s[:unit]
for i in range(unit, len(s), unit):
# 압축이 될 수 있는 경우
if cur_str == s[i:i+unit]:
cnt += 1
else:
# 이전 압축한 문자열을 tmp_cmpr_str에 담는다.
if cnt == 1:
tmp_cmpr_str += "" + cur_str
else:
tmp_cmpr_str += str(cnt) + cur_str
# 압축 기준 갱신
cnt = 1
cur_str = s[i:i+unit]
# 마지막 단위 문자열 처리
if cnt == 1:
tmp_cmpr_str += "" + cur_str
else:
tmp_cmpr_str += str(cnt) + cur_str
# unit단위로 압축한 문자열의 길이를 length에 담는다.
length.append(len(tmp_cmpr_str))
return min(length)😋 느낀점
처음에 문제를 제대로 읽지 않아서 헤맸다...
'문자열은 제일 앞부터 정해진 길이만큼 잘라야 한다.'라는 조건을 모르고 문제를 풀기 시작했다. 이 조건을 모르고 문제를 풀다보니 인덱스를 조정하는 게 굉장히 복잡하게 느껴졌다. 1시간동안 해메다가 결국 구글링을 해서 다른 사람의 코드를 보았는데 무언가 이상하다는 것을 알아챘다....그래서 문제를 다시 읽어보니 입출력 예 #5에 저런 조건이 있다는 것을 알게 되었다.
내가 문제를 풀 때 입출력 예시는 잘 읽지 않는 경향이 있었는데 앞으로는 문제에 쓰여있는 모든 내용을 읽고 문제를 풀기로 약속~~👍

할 수 있어! :)