서론
주니어 개발자인 내가 코드를 작성할 때 자주 들던 고민이 있다. 바로 계층간 모델을 어떻게 매핑할 것인가이다. 그러던 중 만들면서 배우는 클린 아키텍쳐라는 책에서 계층간 모델을 매핑하는 다양한 전략들을 소개하는 부분을 읽고 느낀점을 정리하려고 한다.
계층간 모델은 어떻게 정의해야할까?
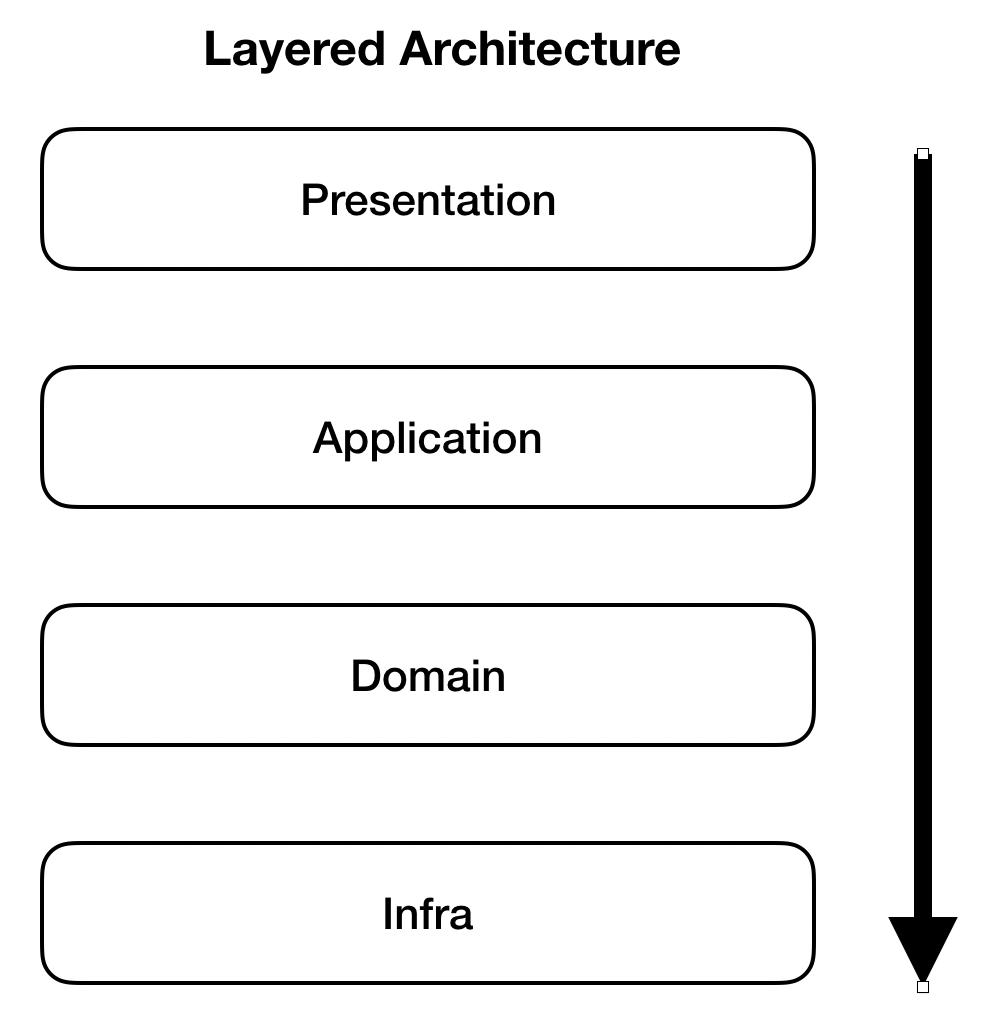
어플리케이션을 개발하기 위해 일반적으로 비슷한 관심사끼리 계층을 분리하는 계층형 아키텍쳐(Layered Architecture)를 선택할것이다.
분리되어버린 서로 다른 계층 간에 입출력 데이터를 전달하기 위해서는 모델을 정의할 필요가 있다. 이 때 모델을 정의하는 방법은 다음과 같을 것이다.
- 두 계층 간 서로 같은 모델을 정의
- 두 계층 간 서로 다른 모델을 정의하고 매핑하여 전달하는 방식
이 중 어느 방식을 채택할 것인가? 두 계층 간 서로 같은 모델을 정의하면 코드를 작성하기에는 편리하지만 두 계층이 강하게 결합된다. 반대로 두 계층 간 서로 다른 모델을 사용하면 계층 간의 결합이 느슨해지지만 매핑을 위한 보일러플레이트 코드를 많이 작성해야한다.
각 방식의 장단점 때문에 선택을 하기가 쉽지 않다. 다양한 매핑전략을 통해 자세히 분석해보자
다양한 매핑 전략들
'만들면서 배우는 클린 아키텍쳐' 에서는 계층간 모델을 매핑하는 전략으로 다음과 같은 4가지 전략을 소개하고 있다.
1. '매핑하지 않기' 전략
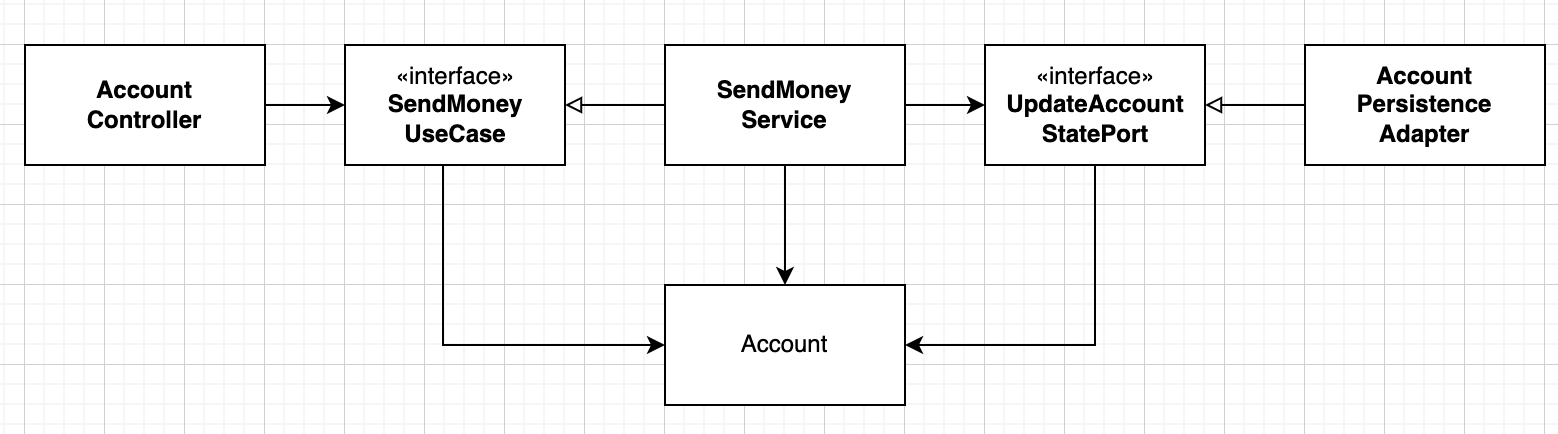
매우 단순한 전략으로 모든 계층이 전부 같은 모델을 사용하는 것이다.
모든 계층이 전부 같은 정보를 필요로 한다면 장점인 전략이다.
하지만 새로운 요구사항이 들어오게 되면 금방 유지하기 어려워지는 전략이다. 점점 갈수록 한 모델안에 여러 계층의 로직이 덕지덕지 붙게되어 식별하기 어려워진다. 단일 책임 원칙을 위반하는 것이다.
실제로 이 전략이 범용적으로 사용되는 레거시 코드를 봤었는데 유지보수하기 정말 끔직하고 예상하지 못한 사이드이펙트가 많이 발생했다.
2. 양방향 매핑 전략
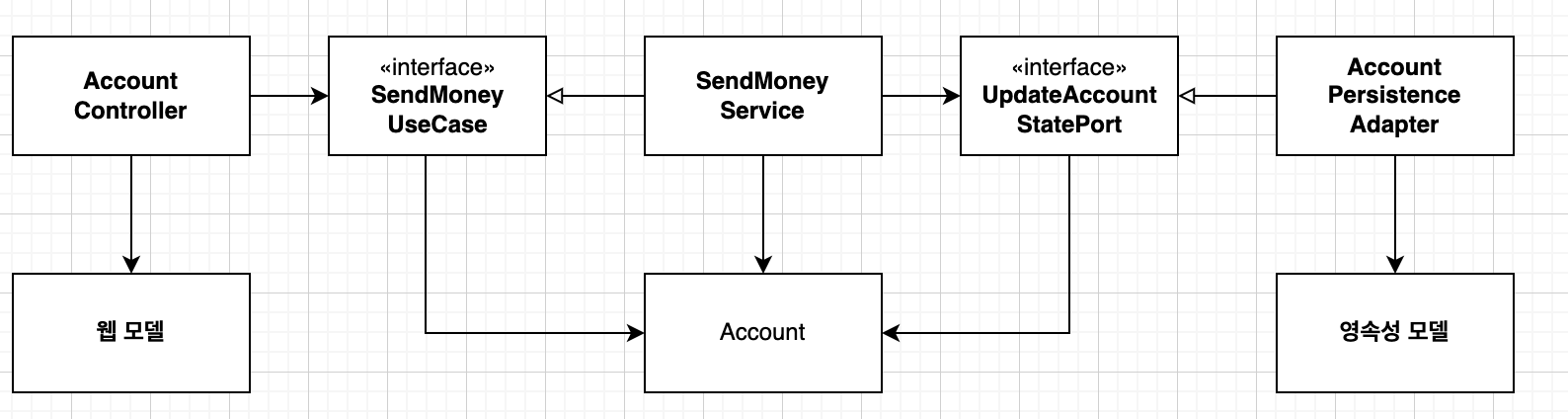
양방향 매핑 전략은 서로 다른 두 계층이 전용 모델을 사용하는 방식이다.
예를 들어 도메인 모델과 영속성 계층의 모델이 분리되었다고 가정해보자. 입력이 들어 왔을 때 도메인 모델 -> 영속성 모델 로 매핑 과정이 필요하고 다시 출력이 나갈 때 영속성 모델 -> 도메인 모델 로 매핑을 해주는 양방향 매핑이 필요하다. 위 사진의 구조는 웹 모델, 도메인 모델, 영속성 모델이 서로 다른 모델로 분리된 경우라 할 수 있다.
모델이 분리된 계층은 이제 전용 모델을 변경하더라도 다른 계층에 영향을 주지 않는다. 하지만 모델간의 매핑하는 보일러 플레이트가 증가한다.
ModelMapper 나 Mapstruct 라이브러리를 사용하면 보일러플레이트를 줄일 수도 있지만 객체 변환이 단순하지 않으면 직접 매핑하는게 더 낫기 때문에 보일러플레이트를 피할 수는 없는 것 같다.
3. 단방향 매핑 전략
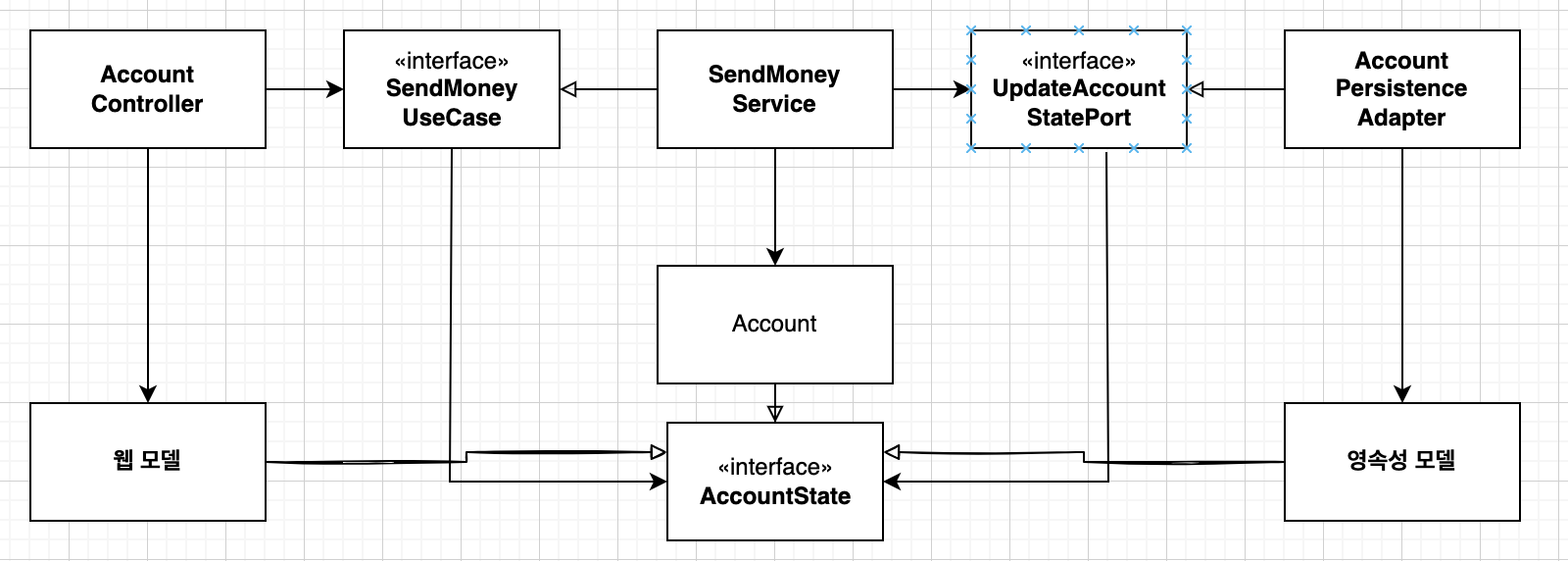
단방향 매핑전략은 모든 계층의 모델이 같은 인터페이스 모델을 구현하는 방식이다. 인터페이스는 getter 메소드를 제공해서 읽기 전용 모델을 제공할 수 있다.
이 전략을 취하면 각 계층 모델 -> 인터페이스 모델 로 단방향 매핑만으로 다른 계층에 모델을 전달해 줄 수 있다.
DDD 개념에서는 도메인 모델에 비즈니스 로직이 추가 되는데 이러한 도메인 모델을 그대로 상위 표현 계층에 전달해버리면 도메인에 대한 직접 제어가 가능하다. 하지만 단방향 매핑 전략으로 인터페이스 모델을 제공하면 이런 행동을 제한할 수 있다.
하지만 공통의 인터페이스 모델을 사용하므로 '매핑하지 않기 전략'처럼 새로운 요구사항에 취약하다. 인터페이스에 새로운 메소드가 추가되면 다른 계층의 구현 모델에도 전부 영향을 받는 단점이 있다.
4. 완전 매핑 전략
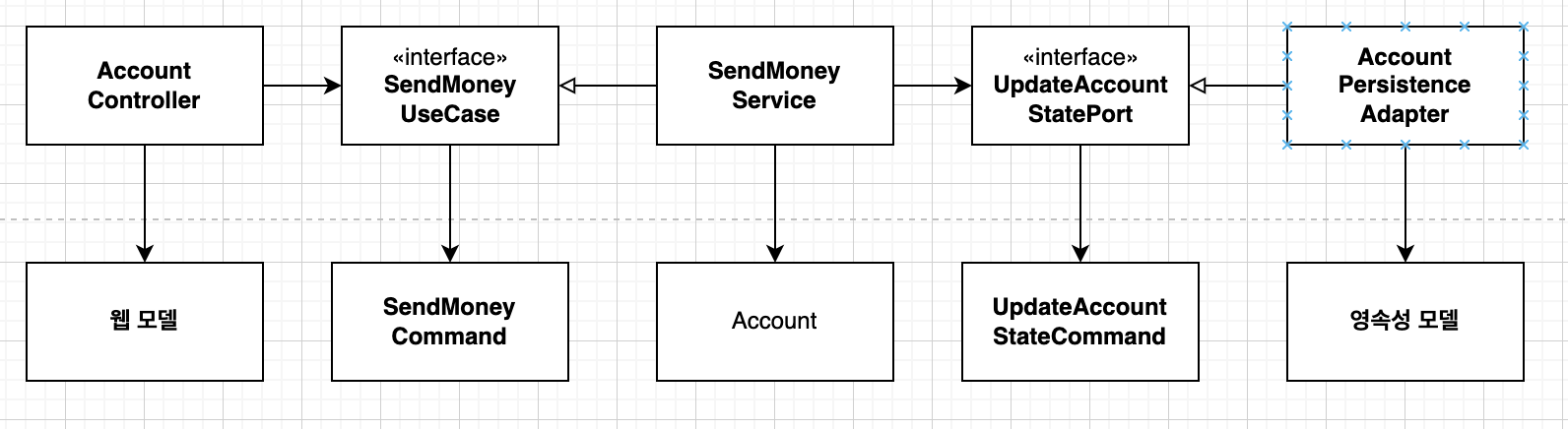
완전 매핑 전략은 모든 계층에 전용 모델을 사용하는 방법이다.
모든 계층이 엄격하게 분리되는 장점이 있고 테스트코드를 작성하기도 편리하다.
하지만 보일러플레이트가 정말 끔찍할 정도로 많아진다.
어떤 매핑 전략을 사용해야 하는가?
책에서도 언급하지만 정답은 없다. 각 전략은 서로 섞어쓰는 것도 가능하다. 애플리케이션 계층과 영속성 계층의 모델은 개발상의 편의로 인해 '매핑하지 않기' 전략을 취하는 경우도 많다.
@Getter
@Entity
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "order_id")
private Long id;
@OneToMany(mappedBy = "order", cascade = CascadeType.PERSIST)
private List<OrderLine> orderLines;
@Embedded
private ShippingInfo shippingInfo;
}도메인 모델과 영속성 모델을 통일하면 JPA 전용 어노테이션이 도메인 모델에 추가되지만 jpa가 제공해주는 영속성 기능과 같은 장점을 누릴 수 있다.
또, 입력 모델과 출력 모델사이의 매핑 전략에 차이를 둘 수도 있다. 예를 들어 웹 계층과 애플리케이션의 계층의 입력 모델은 매핑을 하지 않고 출력 모델은 매핑하는 것이다.
@PostMapping("/api/v1/orders")
public ResultResponse<OrderResponseDto> createOrder(@RequestBody OrderRequestDto orderReuqestDto) {
orderResponseDto = orderService.createOrder(orderReuqestDto);
return ResultResponse.ok(orderResponseDto);
}
@Getter
@AllArgsConstructor
public class ResultResponse<T> {
private T data;
private success;
private String message; // 실패 메시지
public static <T> ResultReponse<T> ok(T data) {
return new ResultResponse<>(data, true, null);
}
public static <T> ResultResponse<Void> fail(String message) {
return new ResultResponse<>(null, false, message);
}
}예시로 든 코드는 API 응답으로 ResultResponse 라는 정형화된 템플릿 모델이 있다고 가정한 것이다. 이때 ResultResponse 객체는 웹 계층에서만 필요로 하는 출력 모델이므로 애플리케이션 계층에서 사용할 필요는 없다. 입력 모델의 경우 웹 계층에서는 @RequestBody 어노테이션을 붙이면 ArgumentResolver에 의해 요청 바디값이 자동으로 객체로 매핑된다. 요청 객체는 대부분 애플리케이션 계층에서 필요로하는 값을 포함하므로 서로 동일한 모델을 사용해도 괜찮은 방법이다.
결론
계층 간의 객체를 매핑하는 방법은 개인의 선호도나 팀의 선호도를 따르며 상황에 맞는 최선의 매핑전략을 선택해야 한다.
참고자료
https://velog.io/@jeb1225/DDD%EC%9D%98-%EA%B3%84%EC%B8%B5%EA%B5%AC%EC%A1%B0Layered-architecture
https://sabarada.tistory.com/159
https://rutgo-letsgo.tistory.com/333
