항상 새로운 프로젝트는 시작할 때 코드 구조를 어떻게 해야하지?라는 고민을 한다.
하지만 MVC, MVP, MVVM, Clean ...... 이러한 새로운 개념들을 공부해야 하다 보니까
그냥 일단 개발을 하자라고 생각을 하고 넘기게 됐던 것 같다.
이제는 Base Structure를 만들어두고 이것들을 기반으로 코드를 작성해보려고 한다.
그러면 우선 그 유명한 Clean Architecture가 뭔지 알아보자
Clean Architecture가 뭔데?
클린 아키텍처는 『클린 코드(Clean Code)』를 저술한 로버트 마틴(Robert C. Martin)이 제안한 시스템 아키텍처로, 기존의 계층형 아키텍처가 가지던 의존성에서 벗어나도록 하는 설계를 제공합니다.
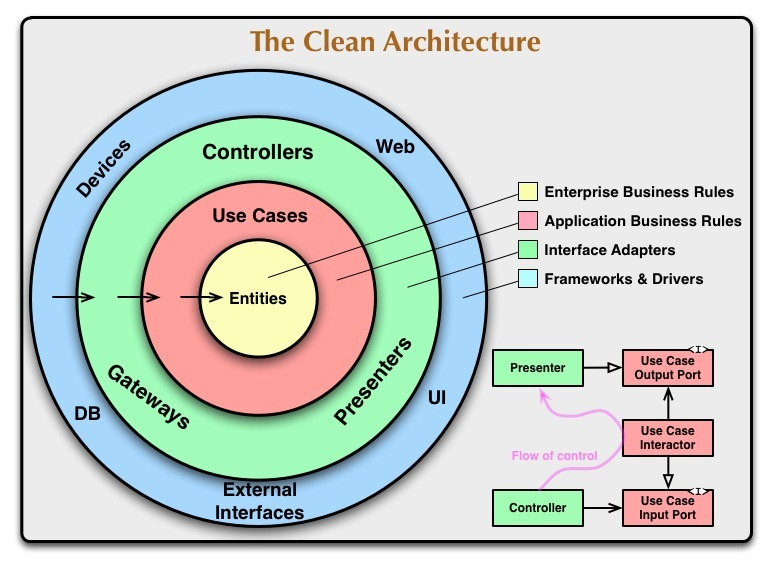
로버트 마틴이 제시한 아키텍처로 의존성에서 벗어날 수 있도록 설계한 구조를 얘기한다.
위 그림과 말을 보면 생소한 용어도 많고 왜 필요한지 알 수 없다. 차근차근 하나씩 살펴보도록 하자
용어 설명
Enterprise Business Rules : 시스템 전반에 걸친
ex) 회사의 모든 사용자는 고유한 ID를 가져야 한다.
Entity : 시스템의 가장 핵심적인 비지니스 규칙을 담고 있는 객체들이다.
ex) 전자상거래 시스템에서 'User'나 'Order' 같은 객체
Application Business Rules : 특정 어플리케이션내에서만
ex) 로그인 시도 횟수가 5회 이상이면 계정이 잠긴다.
Use Case : 어플리케이션의 비지니스 규칙을 구현한 계층이다. 각 유즈 케이스는 사용자가 시스템과 어떻게 상호작용하는 특정한 방법을 정의해둔다.
ex) "상품 주문하기", "사용자 등록" 같은 기능
여기서 비지니스 규칙 이란 뭘까?
특정 비지니스에서 반드시 따라야 하는 정책, 규칙, 제약 사항을 의미한다.
여기에는 사용 흐름을 정의하거나, 데이터를 처리하는 방법을 명확하게 규정하는 규칙들이다.
그래서 Entity는 비니지스 규칙을 담아서 설계된 상태를 말하고
Use Case는 비지니스 규칙이 구현 될 수 있도록 한 것이다.
Interface Adapter : Use Case <-> 외부 인터페이스 (UI, DB) 간의 데이터 변환
Use Case에서 나온 데이터를 화면에 맞게 포맷팅하거나, UI에서 입력받은 데이터를 유스 케이스가 이해할수 있는 형식으로 변환
Controller: Use Case와 상호작용하는 계층으로 입력을 받아서 Use Case에 전달
사용자의 요청을 처리하고, 적절한 Use Case를 호출 (중개 역할)
Gateway : Database와 같은 외부 인터페이스와 사용작용하는 역할
Presenter : Use Case에서 데이터를 받아서 UI에 적합한 형태로 변환하는 역할
Frameworks & Drivers :
External Interface : 시스템이 외부와 상호작용하는 모든 Interface
Web :
UI :
Device :
DB :
사용 예시 Entity ~ DB까지
User Entitiy -> "가입하기" Use Case가 있으면 레포지토리에 요청 -> DB가 이해할 수 있게 Data Access Layer(Interface Adapters)로 SQL 쿼리로 변환 -> 실제 데이터베이스와 통신 SQL 쿼리 실행(Frameworks & Drivers)
그래서 이렇게 계층을 나누는 게 왜 중요한데?
여기서 가장 중요한 점은 내부의 원은 외부의 원에 대해 알지 못해야 하는 의존성 규칙 을 지켜야 한다는 것이다.
클린 아키텍처의 의존성을 밖에서 안으로 향하고, 바깥 원은 안쪽 원에 영향을 미치지 않는다.
경계의 바깥으로 갈수록 덜 중요하고 세부적인 영역으로 표현, 안으로 갈수록 고수준(추상화된 개념)
밖에 있을수록 집에서 유튜브를 보면서 홈트레이닝을 한다 안에 있을 수록 운동을 한다로 표현할수 잇다.
NHN Cloud Tech Blog에 따르면 바깥 원은 안쪽 원에 영향을 미치지 않는다 이점이 중요하다고 한다.
클린 아키텍처가 왜 필요한데?
개념적으로는 의존성 분리 아키텍처가 중요하다고 흔히들 말하지만 실무적으로 어떤 상황이 있는지 이해하기 힘들다. 예시를 들어서 생각해보자.
나는 카카오뱅크 앱의 개발자이고, 어느 날 카카오 뱅크앱이랑 토스앱이랑 통합된다고 가정해보자
"카카오뱅크 앱 시스테밍 잘 되어 있으니 카카오뱅크의 핵심 기능은 유지하고, UI와 DB 쪽만 바꿔주세요" 라는 요구, 또는 "카카오 뱅크 앱이 너무 잘 되니 웹으로 확장해 봅시다" 요구가 있을 수 있다.
이런 요구가 있을 경우 최대한 현재의 구조를 유지하고, 현재의 기능을 유지하며 변경을 해야한다.
이럴 경우 핵심 기능을 담고 있는 Entity, Use Case 부분은 유지하는 것이 좋을 것이다.
왜냐면 고객과 업체 사이에서 금융 서비스를 중계한다라는 비지니스 로직은 변하지 않았기 때문이다. 그래서 결국은 Interface Adapter Framework & Drivers 부분만 수정하면 된다.
이처럼 비지니스 로직은 변경하지 않으면서, 언제든 DB와 프레임워크에 구애 받지 않고 교체할수 있는 아키텍처가 중요한 것이다.
Android에서는 어떻게 적용할지 실제로 확인해보자
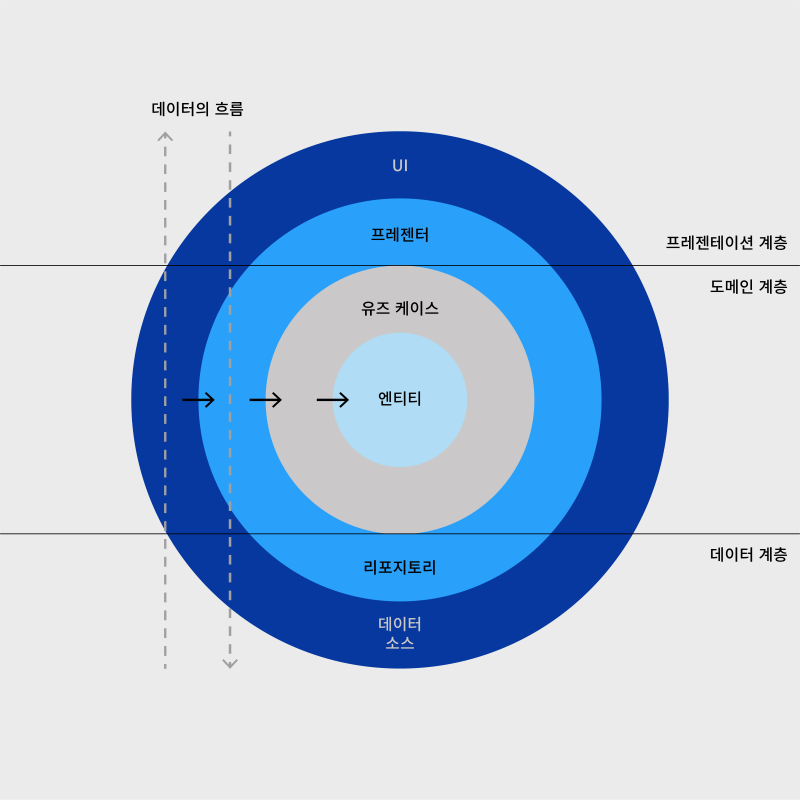
Android에서는 클린 아키텍처에서 보여줬던 원을 3가지 계층으로 나누는 구조를 가진다.
프레젠테이션 도메인 데이터 계층으로 원을 또 수평으로 나누고 있다.
프레젠테이션 계층 : 화면 표시와 사용자 입력을 담당하는 View, ViewModel 같이 사용자 입력에 어떤 반응을 해야하는지에 대한 판단을 하는 Presenter을 포함한다.
도메인 계층 : Use Case, Entity가 들어가는 영역이다.
데이터 계층 : 데이터 통신을 하는 Repository, 데이터 입출력이 있는 Data Source가 있다.
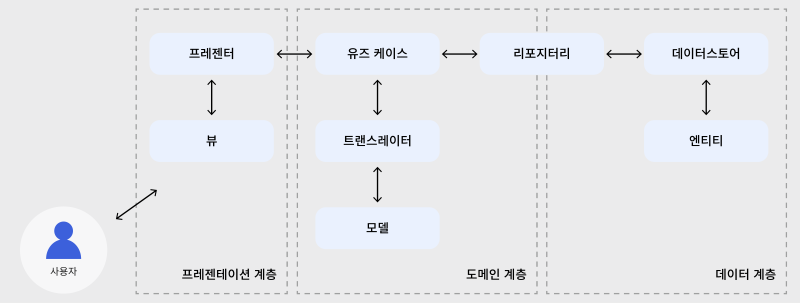
위 사진을 참고하면 사용자가 버튼을 클릭할 경우 UI -> 프레젠터 -> 유즈케이스 -> 엔티티(모델) -> 레포지토리 -> 데이터 소스로 간다.
여기서 가장 이해가 안 됐던 점이 도메인 계층이 데이터 계층을 알고 있어야 데이터를 보낼수 있는 게 아닌가
알고 있어야 개념을 코드 예시를 통해 살펴보자.
# 도메인 계층 코드
class UserService:
def __init__(self):
# 도메인 계층에서 데이터 계층의 구현에 직접 의존하고 있음
self.user_repository = UserRepository(database_connection)
def get_user(self, user_id):
# 데이터 계층의 find_by_id 메서드를 직접 호출
return self.user_repository.find_by_id(user_id)
# 도메인 계층에서 사용할 인터페이스 정의
class UserRepositoryInterface:
def find_by_id(self, user_id):
raise NotImplementedError("This method should be overridden by subclasses")
# 도메인 계층 코드
class UserService:
def __init__(self, user_repository: UserRepositoryInterface):
# UserRepositoryInterface에 의존하게 됨
self.user_repository = user_repository
def get_user(self, user_id):
# 인터페이스를 통해 메서드를 호출
return self.user_repository.find_by_id(user_id)
위의 코드는 도메인 계층에서 Repository 데이터 계층에의존하고 있는 예시이다. 그리고 아래는 Interface 구현을 통해 의존성을 배제한 코드이다.
이제 차이점이 뭔지 코드를 보면 쉽게 파악할 수 있을 것이다.
위에 있는 코드를 보면 UserService가 UserRepository 클래스의 인스턴스를 직접 생성해서 데이터베이스에 접근하고 있다. 만약 UserRepository에서 find_by_id 하는 함수가 DB에서 File로 변경을 해야하고 한다라고 하면 UserRepository(database_connection)가 UserRepository(file_name)으로 변경 되어야 하는 문제점이 발생한다.
컴공생답게 코드 예시를 보니까 조금 더 이해가 쉬운 것 같다.
그리고 사실은 도메인 계층이 데이터 계층을 참고하고 있지 않습니다 이런 이유는 Repository의 의존성 역전 법칙 때문입니다.
의존성 역전 법칙이 뭔데?
객체 지향 프로그래밍에서 의존 관계 역전 원칙은 소프트웨어 모듈들을 분리하는 특정 형식을 지칭한다. 이 원칙을 따르면, 상위 계층(정책 결정)이 하위 계층(세부 사항)에 의존하는 전통적인 의존 관계를 반전(역전)시킴으로써 상위 계층이 하위 계층의 구현으로부터 독립되게 할 수 있다.
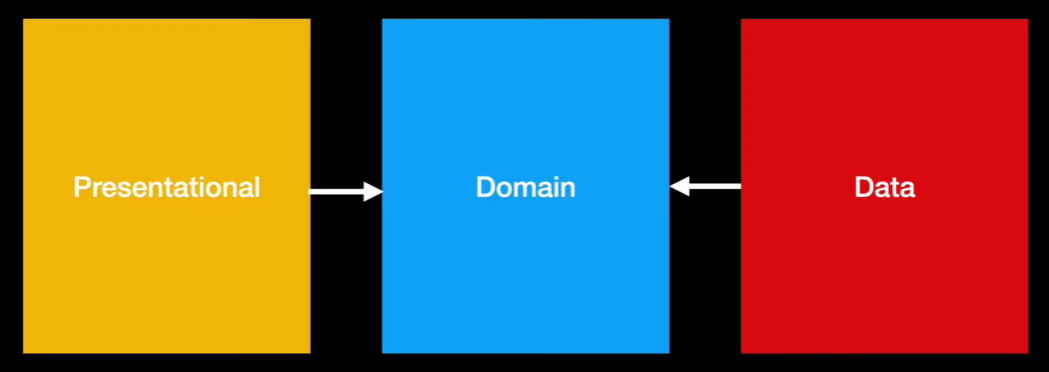
Clean Architecture에 따르면 Presentational은 Domain을 알고 있고 Data도 Domain을 알고 있는 구조이다. 예를 들어 UI에서 버튼을 누른다면 Domain 계층으로 비지니스 로직 요청을 보내야 하는 것입니다.
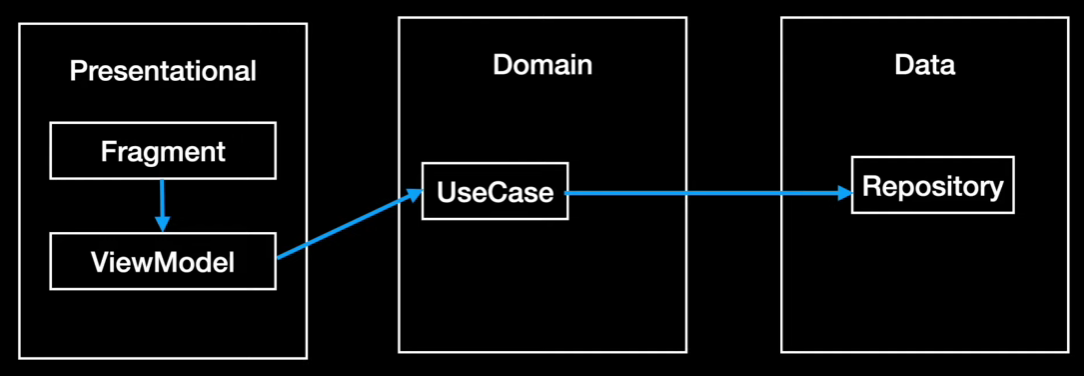
위사진을 보면 Presenter -> Domain -> Data의 흐름으로 데이터가 흘러가고 있습니다. 이렇게 되면 안 되는 것이 Domain은 원래 Data를 모른 상태로 진행해야 했던 것입니다.
이걸 가능하게 한 것이 바로 의존성 역전(DIP)입니다.
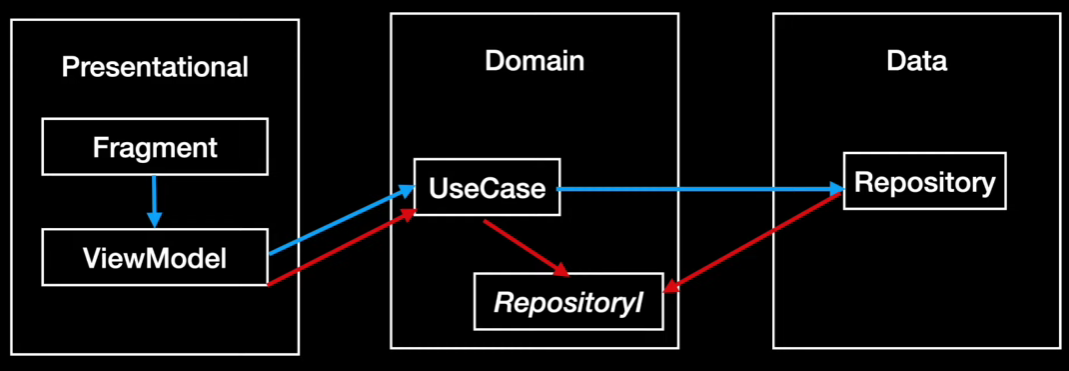
Domain에서 Data Interface를 생성하여 Data가 Domain에 의존할 수 있게 하여
의존성이 역전 되었다라고 할 수 있는 것입니다.
그러면 Android는 DIP를 사용해서 Clean Architecture를 "지향"할까?
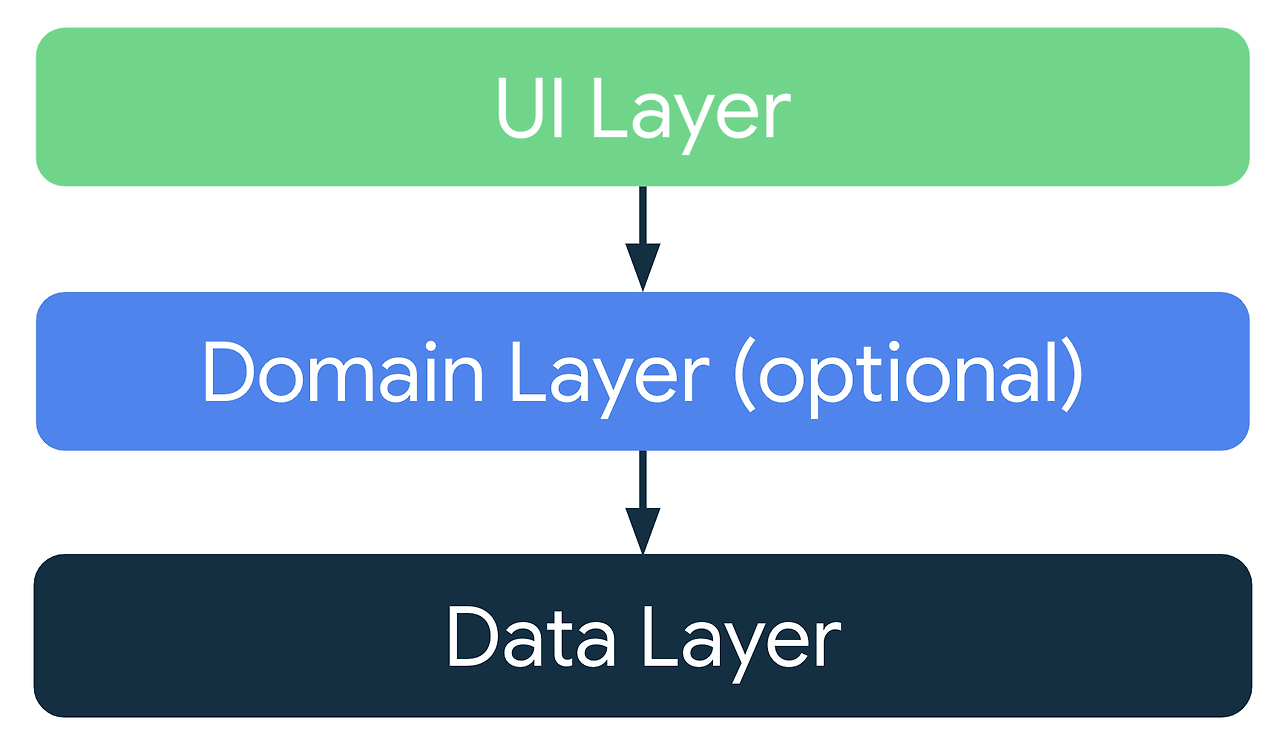
위의 사진이 안드로이드에서 권장하는 아키텍처입니다.
아니 지금까지 공부한거랑 다르잖아?
사실 안드로이드에서 권장하고 있는 아키텍처는 클린 아키텍처가 아니었습니다
내용이 길어져서 안드로이드에서 권장하는 아키텍처를 적용하는 과정은 다음 편에 적도록 하겠습니다
참조 및 출처
https://everyday-develop-myself.tistory.com/309
https://meetup.nhncloud.com/posts/345
