영문으로 검색을 하였고 https://www.iangreer.io/tesla-fsd-technical-deep-dive/ 를 참고하여 작성했다.
머스크는 사람의 눈이 두개의 카메라를 가진 것과 똑같다고 묘사를 했다. 사람의 눈은 깜빡이거나 다른 방향을 보게 되면 Vision을 상실하게 되는 반면에 카메라는 continuous하게 사용이 가능하다. 그래서 테슬라는 8개의 카메라를 사용하였다. 여기서 주목해야할 부분은 다른 회사들은 Lidar나 Rader를 사용했다는 것이다.
AI에 대한 자세한 내용은 분석하지 않고 대략적인 구조만 설명할 예정이다.

테슬라의 FSD 뉴런 네트워크는 확률 기반 방식으로 학습 되었다. 카메라가 찍은 사진이 Blurry한 상황에서 시스템이 자동으로 확률을 계산해서 예측을 한다. 하지만 확률 기반으로 계산을 하기 때문에 테슬라는 incorrect한 예측에 피드백을 하고 Threshold의 비율을 조정하면서 더 정확한 예측을 하는 네트워크를 구축하려 한다.
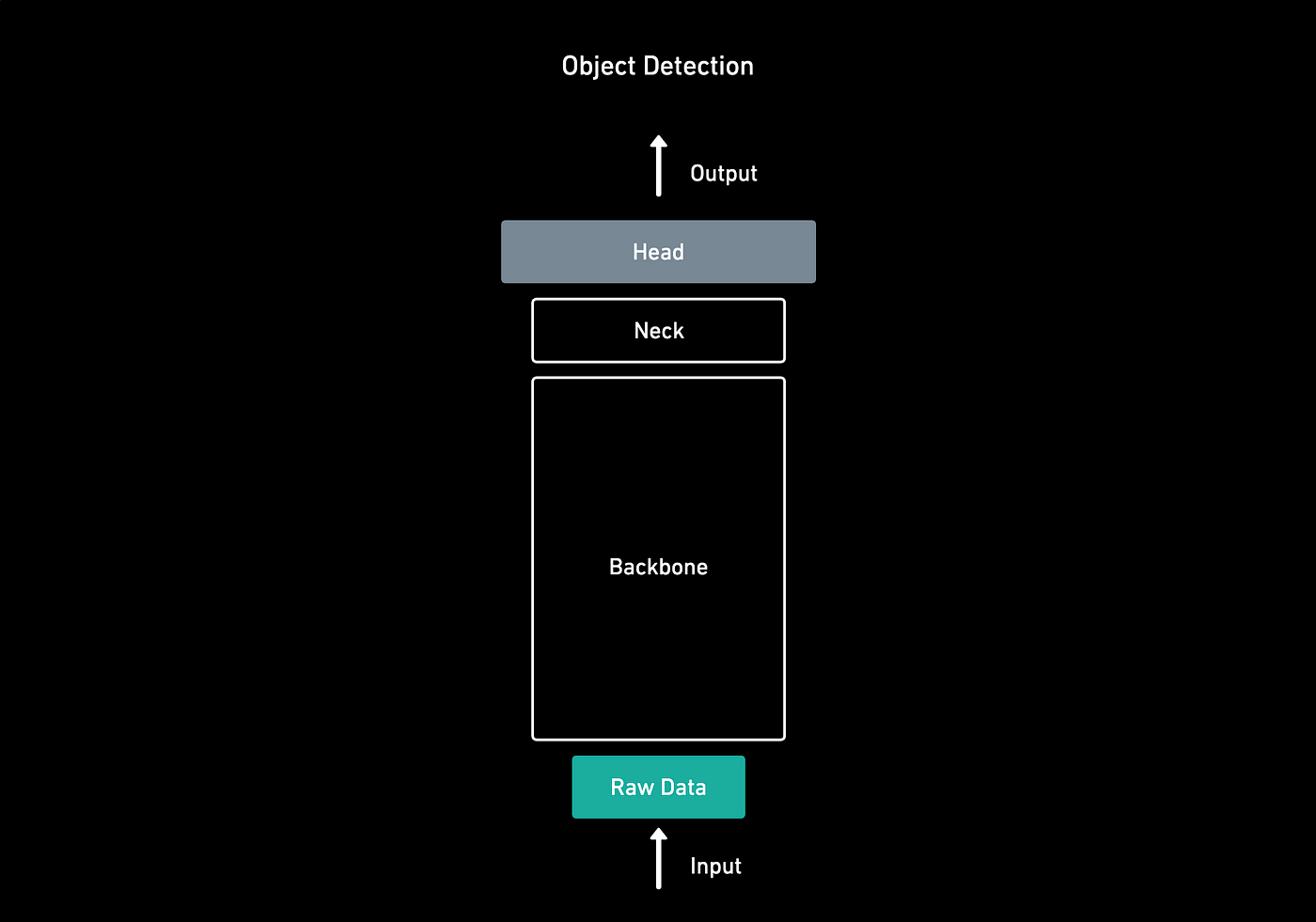
테슬라의 구조는 백본, 넥, 헤드로 구성되어있다고 말할 수 있다.
백본에서는 단일 사진에서 여러 특징을 인지하고 그리고 객체에 대한 풍부한 정보를 추출한다.
백본은 RegNet + ResNet으로 구현되어있고
넥에서는 더 정교한 특징을 추출하고
헤드에서는 input에 대한 Feature Map을 보여준다.
테슬라는 카메라 1대로는 충분하지 않음을 깨닫고 더 많은 카메라를 사용하여 3D 벡터 표현을 하였다.
C++을 사용하여 Occupancy Tracker라는 시스템을 만들었고 이 시스템에서 이미지, 카메라경계, 시간 경과에 따른 연석 감지를 결합했다.여기서 두가지의 제약 사항이 있었다. 첫번째는 카메라 전체의 정보를 융합하고 추적하기 위한 코드 작성이 어려웠고 둘째는 시스템이 예측을 100%로 할 수 없었기 때문에 베터공간에서 '예측'이 필요했다. 벡터로 변환하는 과정에서 정확도를 높이기 위해서 8개의 카메라의 데이터를 하나의 가상 합성 카메라로 합쳐야했다. 이 과정을 통해 이전에 흐릿했던 이미지가 선명해지고 성능이 크게 향상 되었다.
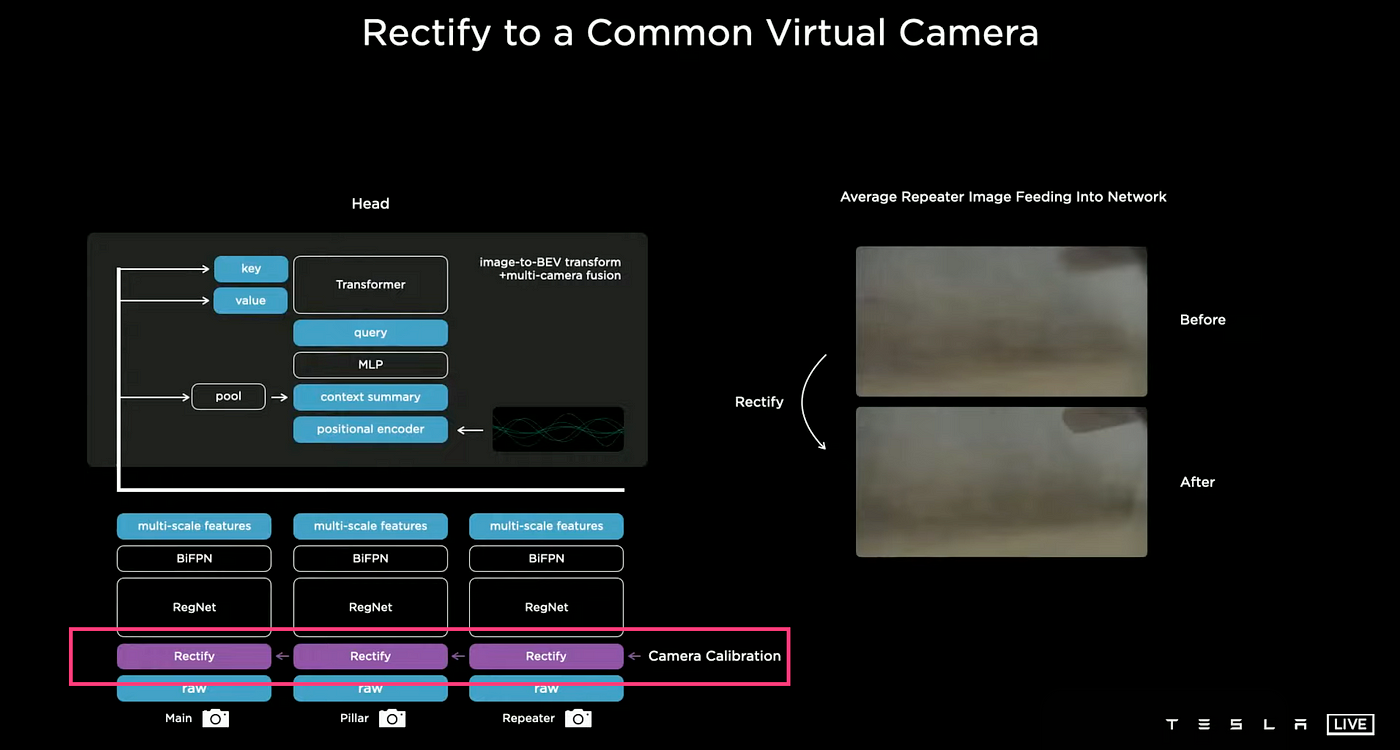
아래 사진은 테슬라의 비전 구조도이다.
1,2. Single-Cam Object Detection
Raw 이미지가 Back으로 입력 되고 카메라 보정을 통해 가상 병합 형상을 만들게 된다.
이후 RegNets 네트워크를 통해 가공된 후 다양한 정보가 추출되고 BiFBN을 통해 Multi-scale 정보가 결합된다.
3. Multi-Cam Fusion + Vector Space
이미지가 Transformer를 통해 Vector Space로 변환된다.
4. Time-Based & Space-Based Memory
Spatial RNN과 같은 비디오 모듈을 이용하여 시간, 공간 큐에 입력된다.
5. HydraNet for Multi-Task
처리된 이미지는 HydraNet 분기 구조를 통과한다.
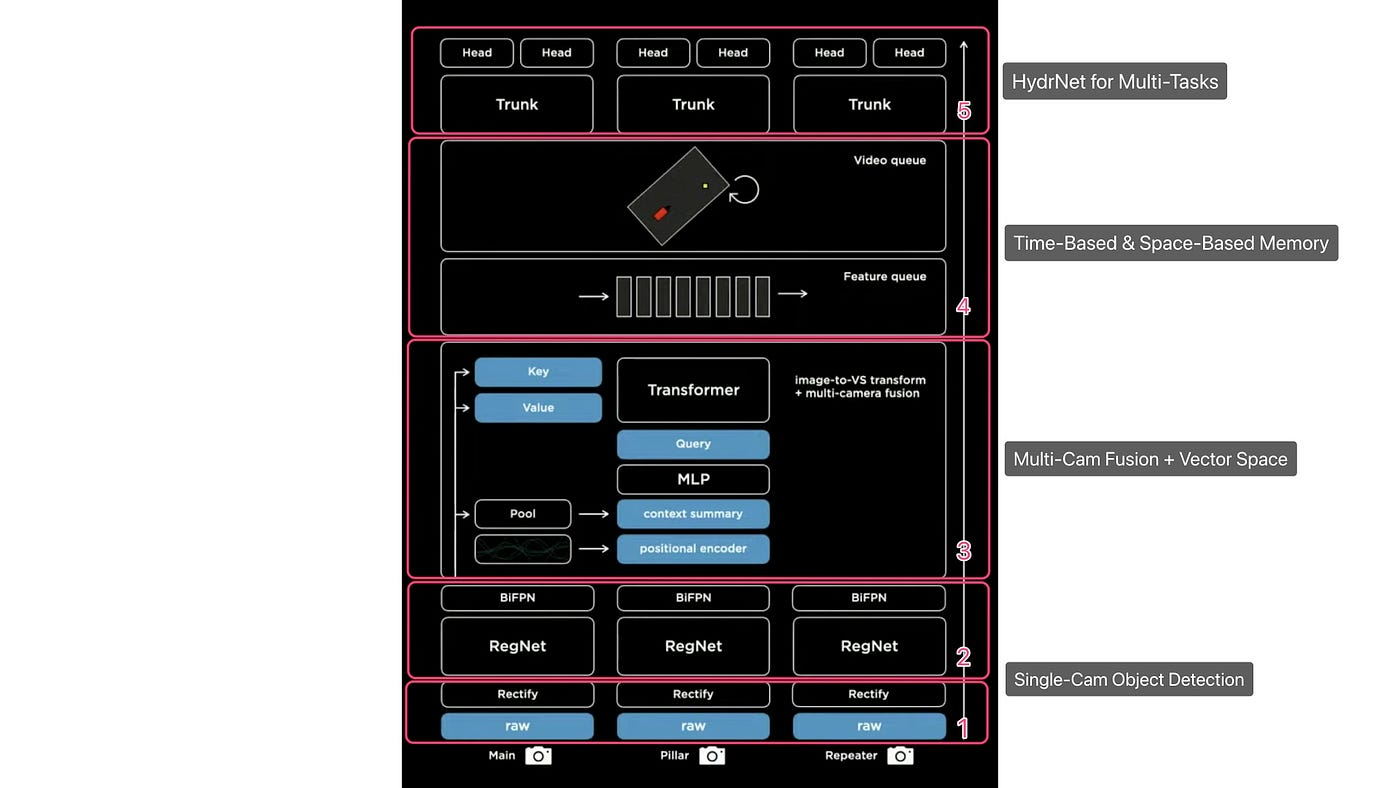
간단한 구조만 다뤘는데 시간이 된다면 각각 네트워크가 의미하는 바와 어떻게 사용했는지 분석을 해보겠다!
