Beautifulsoup4를 활용한 네이버 파워링크 크롤러 개발
배경
동생이 재택근무하는데 여러 키워드를 검색하며 광고 대상이 네이버 파워링크 상 순위를 조사하고, 체크하는 단순노가다를 붙잡고 짜증을 내는걸 보고 제작하게 되었습니다.
요구사항
- 복수개의 키워드는 엑셀파일로 입력
- 파워링크 검색 결과를 저장하고 타겟 브랜드의 순위를 출력
- PC/mobile 두가지 버전 필요
- 순위 결과는 엑셀파일로 저장
구조
- 키워드 목록을 불러옴
- 파워링크 도메인에 특정 키워드를 검색하는 base url 생성
- 검색 결과 중 광고 제목(
class = "lnk_tit") 만 크롤링해서 리스트로 저장 -> beautiful soup 사용 - 제목 리스트에서 타겟 브랜드가 몇 위에 노출되었는지 출력
- csv 파일로 저장
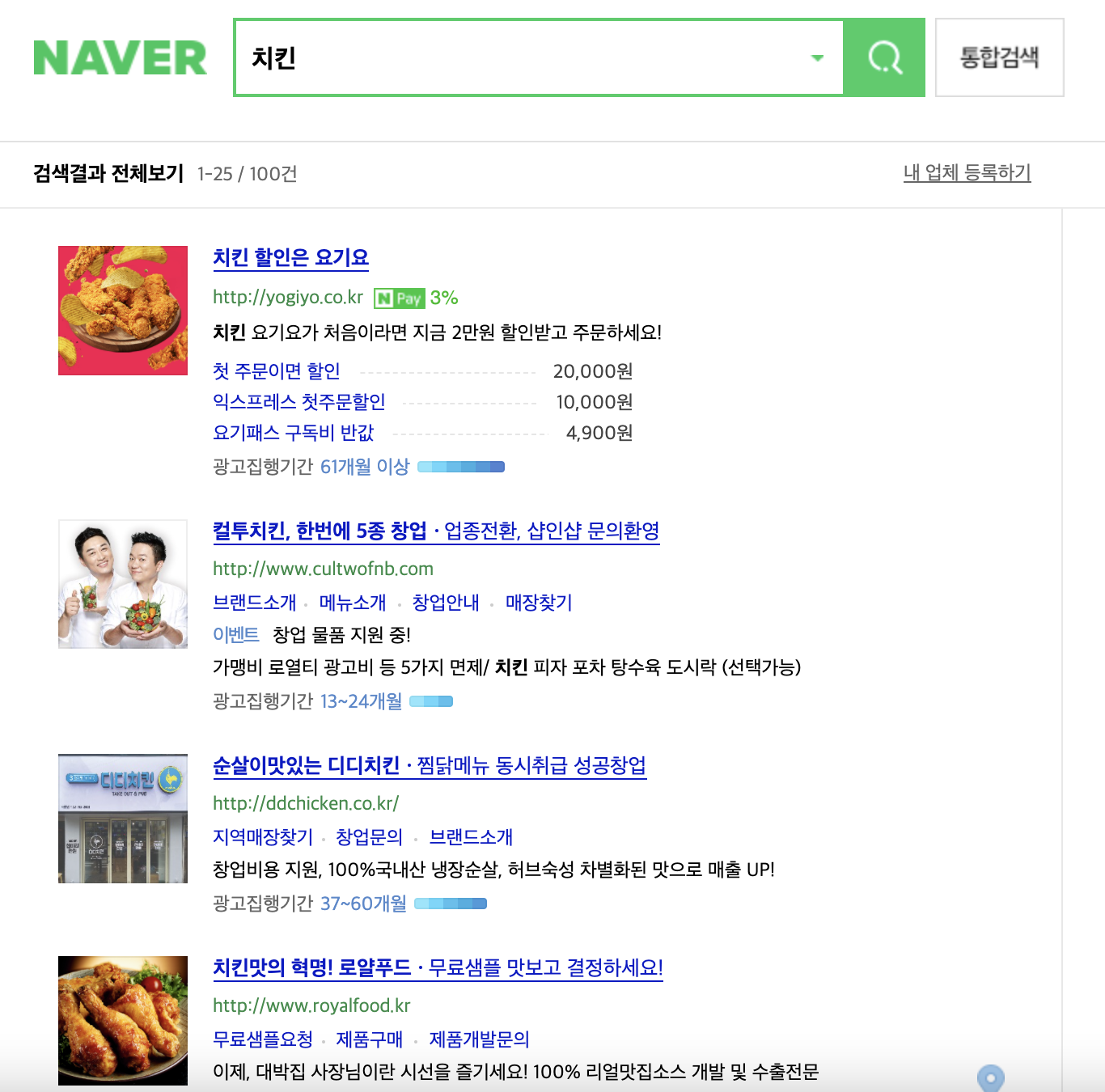
예시
타겟 브랜드가 디디치킨인 경우, 치킨을 검색했을 때 검색결과에서 나온 순위(현재 예시에서는 3위)를 출력하고 다음 키워드를 탐색하며 반복한다.
코드첨부
import csv
import requests
from urllib.request import urlopen
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
import re
import pandas as pd
#cp949 에러 발생시 csv파일 인코딩을 메모장에서 ANSI로 변경
## file_name : 파워링크 검색 키워드 목록
## find : 탐색할 업체
file_name = "keyword.csv"
find = "치킨"
f = open(file_name,'r', encoding="utf-8")
df = pd.read_csv(f)
keywords = df['이름']
## PC 버전 크롤링
data = []
url = 'https://ad.search.naver.com/search.naver?where=ad&x=0&y=0&query='
for keyword in keywords:
base_url = url+quote_plus(keyword)
response = requests.get(base_url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
items = soup.find_all(attrs={'class':'lnk_tit'})
rank = 1
temp = 0
for item in items[:10]:#10위까지만 탐색
serial = item.get_text()
#print(serial[:10])
if "네네치킨" in serial:
temp = rank
rank = rank+1
data.append([keyword,temp])
# 결과 저장
result = pd.DataFrame(data, columns=['Name','Rank'])
print(result)
result.to_csv('result.csv', encoding='euc-kr')
Be curious
안녕하세요 혼자 공부중인 학생입니다만 프로그램 실행을
해보는 와중 KeyError가 keywords = df['이름'] 부분에서 계속 나오는데
어떻게 수정해야 정상 작동이 될까요??
아직 초보다 보니 잘 모르는 부분이 많네요 ㅠㅠ