드디어 프로그래머스 SQL 문제 풀이 마지막 글입니다. 그동안 생각보다 이전 내용이 생각이 안나서 답답하기도 했고, 그러면서 동시에 점점 실력이 늘고 있다는 게 느껴져서 뿌듯하기도 했던 거 같습니다. 마지막까지 잘 마무리해보겠습니다 😉
SELECT: 멸종위기의 대장균 찾기
⭐⭐⭐⭐⭐
문제
- 각 세대별
- 자식이 없는 개체의 수(COUNT)와 세대(GENERATION)를 출력하는 SQL문을 작성해주세요.
- 이때 결과는 세대에 대해 오름차순 정렬해주세요.
- 단, 모든 세대에는 자식이 없는 개체가 적어도 1개체는 존재합니다.
코드
SELECT COUNT(*) AS 'COUNT',
CASE WHEN A.PARENT_ID IS NULL THEN 1
WHEN (A.PARENT_ID IS NOT NULL) AND (B.PARENT_ID IS NULL) THEN 2
WHEN (B.PARENT_ID IS NOT NULL) AND (C.PARENT_ID IS NULL) THEN 3
ELSE 4 END AS GENERATION
FROM ECOLI_DATA A LEFT JOIN ECOLI_DATA B ON A.PARENT_ID = B.ID LEFT JOIN ECOLI_DATA C ON B.PARENT_ID = C.ID
WHERE A.ID NOT IN (SELECT DISTINCT(PARENT_ID) FROM ECOLI_DATA WHERE PARENT_ID IS NOT NULL)
GROUP BY GENERATION
ORDER BY GENERATION;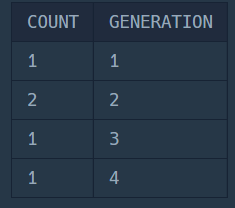
설명
저는 재귀 쿼리를 사용하지 않고 두 번의 SELF JOIN으로 풀어서 결과는 맞으나 채점하면 틀리다고 나왔습니다. 문제 의도와 달라서 그렇다고는 생각하는데, 오히려 단순히 풀었다고 생각해요.
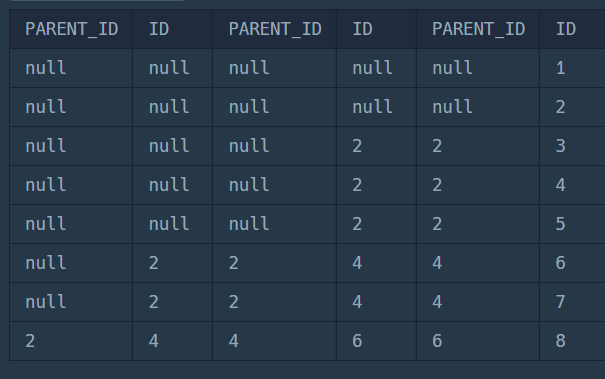
이 사진은 두 번의 LEFT JOIN을 한 결과입니다. 오른쪽부터 두 개 행씩 A, B, C 테이블입니다.
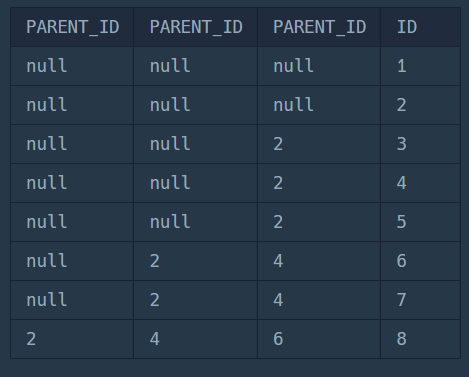
PARENT_ID가 순서대로 NULL인 경우에 따라 GENERATION을 정해주었습니다.
물론 이 방식은, 세대 수가 많아지면 그 만큼의 조인을 해주어야 하기 때문에 다른 문제에 적용하기는 어려울 거 같습니다.
WITH RECURSIVE GENERATION AS(
-- PARENT_ID가 NULL인 1세대 지정
SELECT ID, 1 AS g_level
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
UNION ALL
-- Recursive: 부모 ID를 기준으로 자식 탐색
SELECT e.ID, g.g_level+1 AS g_level
FROM ECOLI_DATA e INNER JOIN GENERATION g
ON e.PARENT_ID = g.ID
)
SELECT COUNT(*) AS `COUNT`, g_level as GENERATION
FROM GENERATION g
LEFT JOIN ECOLI_DATA e
ON g.ID = e.PARENT_ID
WHERE e.ID IS NULL
GROUP BY GENERATION
ORDER BY GENERATION그래서 재귀문을 살펴보면, WITH RECURSIVE절에서 순서대로 GENERATION을 구하고 있음을 확인할 수 있습니다.
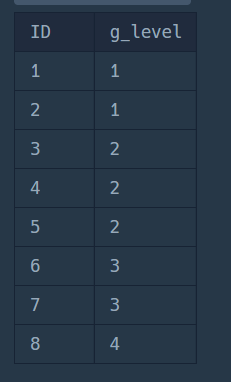
이런 식으로 말이죠.
과정을 뜯어서 보면,
🧩 Step 1: Anchor – PARENT_ID가 NULL인 레코드 (g_level = 1)
ID g_level
1 1
2 1
🧩 Step 2: 재귀 1회 실행 – 1세대(ID: 1, 2)의 자식 찾기 (g_level = 2)
2의 자식: 3, 4, 5
ID g_level
3 2
4 2
5 2
🧩 Step 3: 재귀 2회 실행 – 2세대(ID: 4)의 자식 찾기 (g_level = 3)
4의 자식: 6, 7
ID g_level
6 3
7 3
🧩 Step 4: 재귀 3회 실행 – 3세대(ID: 6)의 자식 찾기 (g_level = 4)
6의 자식: 8
ID g_level
8 4
SUM, MAX, MIN: 연도별 대장균 크기의 편차 구하기
⭐⭐
문제
- 분화된 연도(YEAR), 분화된 연도별 대장균 크기의 편차(YEAR_DEV), 대장균 개체의 ID(ID) 를 출력하는 SQL 문을 작성해주세요.
- 분화된 연도별 대장균 크기의 편차는 분화된 연도별 가장 큰 대장균의 크기 - 각 대장균의 크기로 구하며
- 결과는 연도에 대해 오름차순으로 정렬하고 같은 연도에 대해서는 대장균 크기의 편차에 대해 오름차순으로 정렬해주세요.
코드
WITH YEAR_MAX AS
(SELECT YEAR(DIFFERENTIATION_DATE) AS YEAR,
MAX(SIZE_OF_COLONY) AS MAX_SIZE
FROM ECOLI_DATA
GROUP BY YEAR)
SELECT YEAR(E.DIFFERENTIATION_DATE) AS YEAR,
Y.MAX_SIZE-E.SIZE_OF_COLONY AS YEAR_DEV,
ID
FROM ECOLI_DATA E JOIN YEAR_MAX Y ON YEAR(E.DIFFERENTIATION_DATE) = Y.YEAR
ORDER BY YEAR, YEAR_DEV;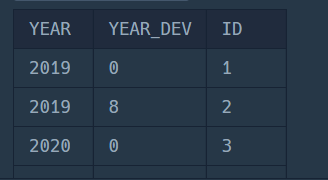
설명
WITH절에서 분화 연도별 가장 큰 대장균의 크기를 구합니다.
그 후, WITH절의 테이블과 원래 테이블을 YEAR를 기준으로 JOIN하여 쿼리를 구성합니다.
GROUP BY: 특정 조건을 만족하는 물고기별 수와 최대 길이 구하기
⭐⭐⭐
문제
FISH_INFO에서
- 평균 길이가 33cm 이상인 물고기들을
- 종류별로 분류하여
- 잡은 수, 최대 길이, 물고기의 종류를 출력하는 SQL문을 작성해주세요.
- 결과는 물고기 종류에 대해 오름차순으로 정렬해주시고,
- 10cm이하의 물고기들은 10cm로 취급하여 평균 길이를 구해주세요.
코드
SELECT
COUNT(*) AS FISH_COUNT,
MAX(LENGTH) AS MAX_LENGTH,
FISH_TYPE
FROM FISH_INFO
GROUP BY FISH_TYPE
HAVING AVG(IF(ISNULL(LENGTH), 10, LENGTH)) >= 33
ORDER BY FISH_TYPE;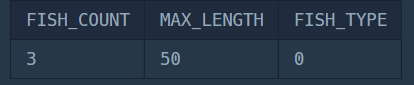
설명
물고기 종류별 평균 길이가 33 이상인 물고기 종류 중에서 해당 열들을 조회해야하므로, FISH_TYPE으로 GROUP BY하여 HAVING절에서 평균이 33이상인 종류만 필터링합니다.
JOIN: FrontEnd 개발자 찾기
⭐⭐⭐⭐
문제
DEVELOPERS 테이블에서
- Front End 스킬을 가진 개발자의 정보를 조회하려 합니다.
- 조건에 맞는 개발자의 ID, 이메일, 이름, 성을 조회하는 SQL 문을 작성해 주세요.
- 결과는 ID를 기준으로 오름차순 정렬해 주세요.
코드
SELECT
DISTINCT(D.ID), D.EMAIL, D.FIRST_NAME, D.LAST_NAME
FROM DEVELOPERS D JOIN SKILLCODES C ON D.SKILL_CODE & C.CODE
WHERE C.NAME IN (SELECT NAME FROM SKILLCODES WHERE CATEGORY = 'Front End')
ORDER BY D.ID;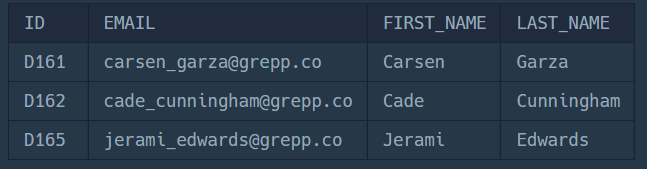
설명
비트 연산자 &를 사용하여, Front End에 해당하는 스킬을 가진 개발자를 WHERE절에서 필터링하여 구했습니다.
STRING, DATE: 분기별 분화된 대장균의 개체 수 구하기
⭐⭐
문제
- 각 분기(QUARTER)별
- 분화된 대장균의 개체의 총 수(ECOLI_COUNT)를 출력하는 SQL 문을 작성해주세요.
- 이때 각 분기에는 'Q' 를 붙이고
- 분기에 대해 오름차순으로 정렬해주세요.
- 대장균 개체가 분화되지 않은 분기는 없습니다.
코드
SELECT
CONCAT(QUARTER(DIFFERENTIATION_DATE), 'Q') AS QUARTER,
COUNT(*) AS ECOLI_COUNT
FROM ECOLI_DATA
GROUP BY QUARTER
ORDER BY QUARTER;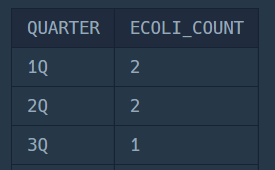
설명
QUARTER함수를 사용해 분기를 구한 후 CONCAT함수를 활용해 'Q'와 함께 출력되도록 합니다.
또한 분기별 개체 수이므로, 분기로 GROUP BY하여 COUNT합니다.
