최근 음주운전 사고에 관한 뉴스 영상들을 많이 접했습니다.

<음주운전을 검색했을 때 나오는 네이버 뉴스 기사의 제목을 크롤링한 결과>
많은 뉴스가 쏟아지는 음주운전 을 키워드로 데이터 분석을 진행해보고 싶었습니다.
사실 관련해서 진짜로(?) 진행해보고 싶었던 주제는 형종 예측입니다. 빈번히 일어나는 음주운전 사고의 데이터를 보고 형종을 예측해준다면 객관적인 판단을 할 수 있도록 도울 수 있지 않을까요?
그런데, 이 주제에서의 문제점은 데이터입니다.. 형종을 예측하기 위해서는 기존에 판결문 데이터가 있어야 하는데 이 부분은 공개된 데이터가 아니기 때문이죠..
그래서 다른 주제를 생각해보았고, 예방과 신속한 사후처리를 위해 음주운전 사고 심각도 예측이라는 주제를 생각하게 되었습니다.
사고 심각도 레이블링
데이터
데이터는 주로 공공데이터를 사용했습니다.
공공데이터 포털과 통계청의 데이터를 사용했으며, 기상청 API도 활용해보았습니다.
레이블링
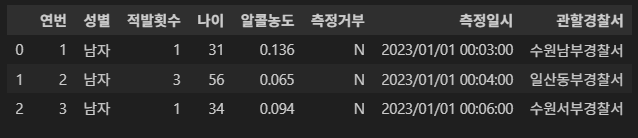
사고 심각도를 예측할 대상 데이터는 경찰청_음주운전 데이터 입니다.
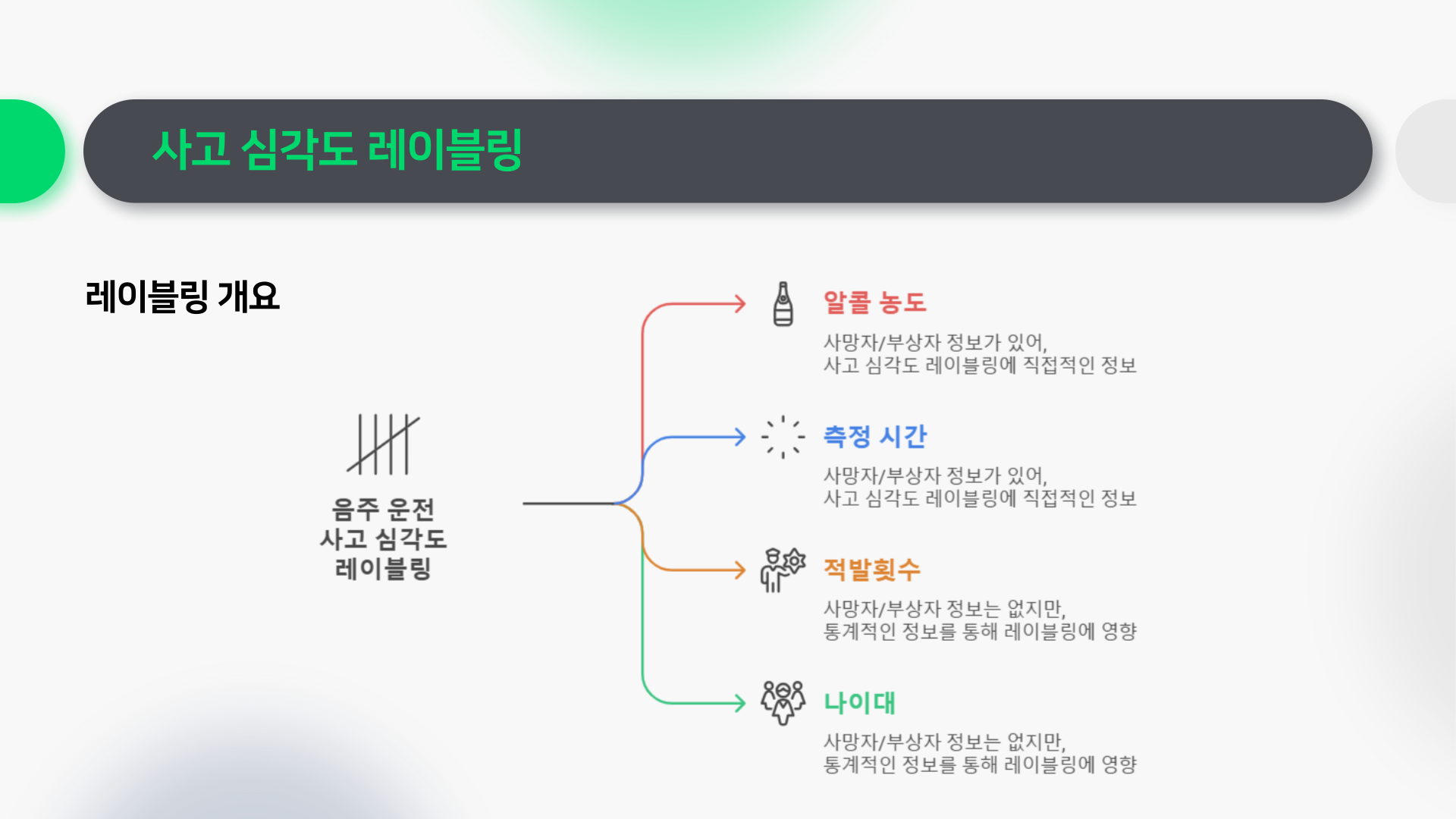
사고 심각도 레이블링에 쓰일 피처들은 다음과 같습니다:
1. 알콜 농도
2. 측정 시간
3. 적발 횟수
4. 나이대
여기에 더해 날씨 정보까지 고려하고 싶었으나,
여러 논문들을 살펴보았을 때 음주운전과 날씨는 상관관계가 없음을 확인할 수 있었습니다.
그래서 기상청 api로 관할경찰서 위치를 기준으로 과거 날씨를 불러왔지만, 레이블링에 사용하지는 않았습니다.
(1) 적발 횟수
"음주 교통사고 10건 중 4건, 음주운전 전력자가 냈다" 라는 기사 내용과 더불어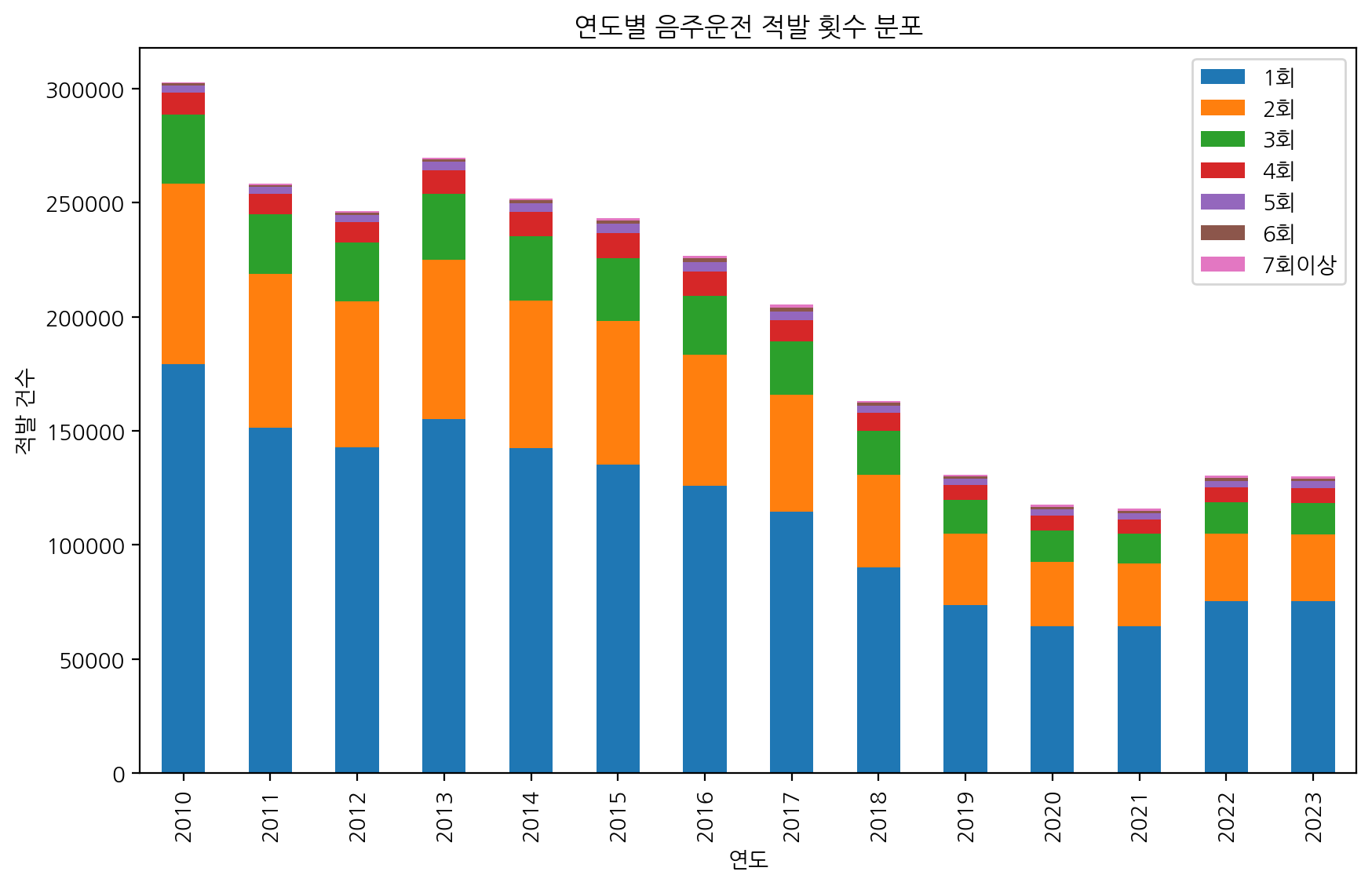
데이터 EDA 결과를 바탕으로 적발 횟수가 2회 이상이면 +1 가중치를 주기로 했습니다.
(2) 나이
나이 정보 역시 EDA 통해서 살펴보았지만, 더 좋은 자료가 있어서 절주온 페이지에서 내용을 참고하여 판단을 내렸습니다.
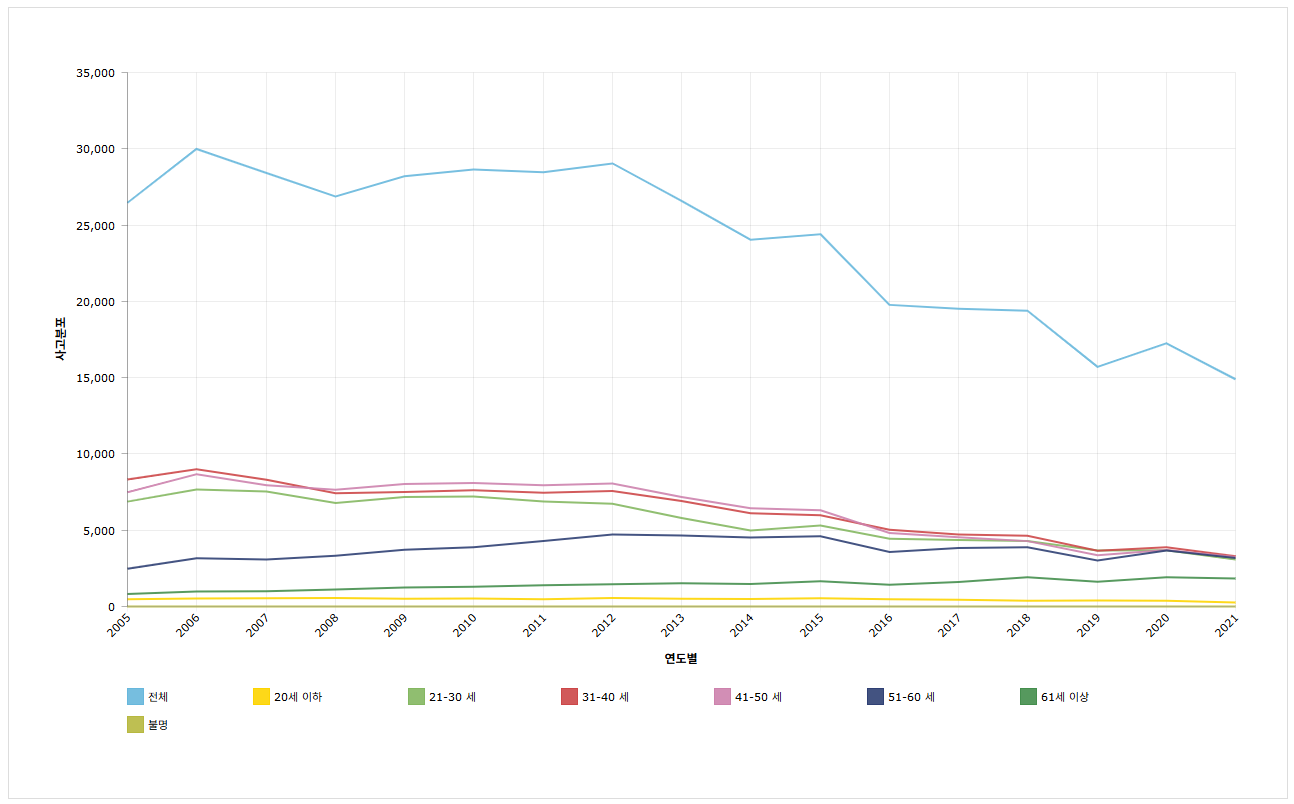
이를 통해 31-50세라면 +1 가중치를 주었습니다.
(3) 알콜 농도
도로교통공단의 데이터를 사용했기 때문에, 정확한 기준을 적용하기 위해 도로교통공단의 문서를 참고했습니다.
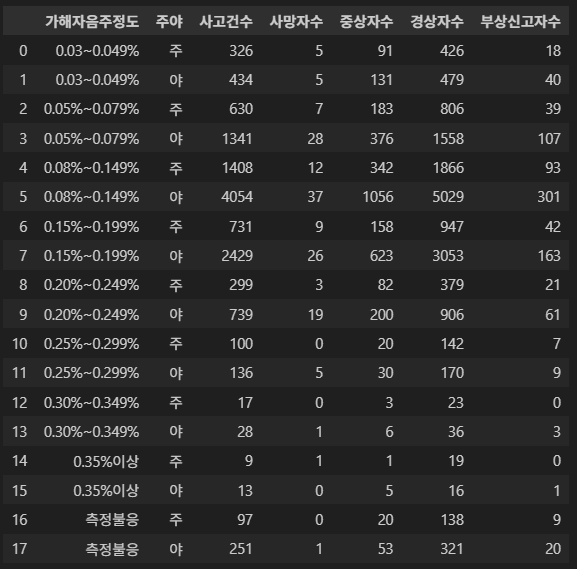
이 데이터에서 말하는 사망자, 중상자, 경상자, 부상신고자의 기준을 명확히 하기 위해 도로교통공단이 정의하는 교통사고 인적피해의 기준을 살펴보았습니다.
그 결과 사고로 인한 치료 기간별 가중치를 부여하기로 했습니다.
그 후 점수의 4분위수를 기준으로 1분위수 이하면 하, 3분위수 이상이면 상, 나머지는 중으로 분류하였습니다.
(4) 측정 일시
이 또한 발생 일시를 MMHH 형식으로 변환하여 알콜 농도와 동일한 기준으로 레이블링을 진행했습니다.
모델 선정
모델은 우선 여러 모델 중 가장 높은 정확도를 보인 모델을 선정하고, 이를 대상으로 하이퍼파라미터 튜닝을 진행해주었습니다.
사용한 모델은 다음과 같습니다:
- Logistic Regression
- Random Forest
- Gradient Boosting
- KNN
이 중 정확도가 0.68로 가장 높았던 Gradient Boosting 모델을 선택하여 하이퍼파라미터 튜닝을 해주었습니다.
하이퍼파라미터 튜닝 과정은 Grid Search로 최적 범위를 찾은 후, BayesianOptimization을 통해 파라미터를 확정지어줬습니다.
하이퍼 파라미터 튜닝을 통해 엄청난 성능 향상을 기록한 것은 아니여서 아쉬웠지만 미세하게 성능이 올라서 다행이라고 생각했습니다..! ㅎㅎ 😊
결론
사실 음주 운전 사고라는 것이 이런 식으로 데이터 분석으로 심각도를 판단하고 어떠한 사람을 사고 위험이 높다고 분류하는 것에는 비약이 심하다고 생각합니다.
이 분석에서 가질 수 있는 의의는 데이터 기반으로 음주 운전을 바라보고, 객관적으로 이를 판단할 수 있는 형종 예측에 사용할 수 있다는 점입니다.
또한, 사고 심각도를 예측함으로써 사고 발생 시 빠른 대처가 가능하다는 점이 의의가 될 수 있습니다.
후에는 이를 발전시켜 데이터만 확보된다면, 실제 우리 사회에서 쓰일 수 있는 모델을 만들어보는 것이 목표입니다.
