이번 글은 키워드 기반 단어 게임 | n-gram, 동시등장행렬, Word2Vec
에 이어서 작성하는 글입니다. 게임을 만들면서 진행했던 여러 실험 과정과 결과에 관해 작성해보겠습니다.
Experiment
3가지 방식 모두 특정 선수에 대한 키워드를 찾을 수 있는 방식이라, 어떤 것을 키워드로 볼지, 어떤 method를 더 큰 가중치를 주는 것이 타당할지에 관한 고민이 있었습니다. 그 과정에 관해 이야기해보겠습니다.
데이터
네이버 뉴스기사의 제목과 내용을 크롤링하여 수집했습니다.
전처리
전처리 과정은 다음과 같습니다.
- 중복데이터 삭제, 특수문자 등 삭제
같은 제목과 내용을 가진 여러 기사들이 존재했기 때문에, 이를 모두 삭제해주었습니다.
# 동일한 본문이 있는 경우 제거
df.drop_duplicates(subset=['total'], inplace=True)또한, 한글만 남기고 나머지 특수문자나 영어 등은 삭제해주었습니다.
# 한글과 공백만 남기기 (영어, 특수문자, 숫자 등 제거)
df['total_prepro'] = df['total'].apply(lambda text: re.sub('[^\uAC00-\uD7A3\s]', '', text))- 선수 이름 사용자 사전에 저장
선수 이름이 토큰화를 통해 쪼개지는 것을 방지하기 위해 미리 사전에 넣었습니다.
word_list = []
for i in range(len(player_list)):
word_list.append(((player_list[i]),(0)))
word_list
print(word_list)
make_user_dic_csv(morpheme_type="NNP", word_list=word_list, user_dic_file_name='user-nnp.csv')# 추가한 사용자 사전이 잘 작동하는지 확인
from konlpy.tag import Mecab
mecab = Mecab(dicpath = '/content/mecab-ko-dic-2.1.1-20180720')
word_list = ['< 신유빈 >']
for word in word_list:
print(mecab.pos(word))원래 유빈으로 토큰화되었던 단어가 온전히 선수이름으로 토큰화된 것을 확인하였습니다.
- 토큰화 후 처리
Mecab을 활용해서 단어를 토큰화해주었습니다. 명사 단어가 게임에 의미있는 키워드가 될 것으로 판단하여 제한하고 진행했습니다.
#1차 토큰화(명사)
df['tokens'] = df['total_prepro'].map(lambda x: mecab.nouns(x))또한, 단어 길이가 1인 것은 키워드로써 의미가 없다고 판단하여 삭제했습니다.
# 한 글자짜리 단어 삭제
df['tokens'] = df['tokens'].map(lambda tokens: [word for word in tokens if len(word) > 1])- 불용어 설정
기존 한국어 불용어 외에 파리, 올림픽, 기자, ... 등 키워드 기반 게임에 불필요한 단어들을 삭제해주었습니다.
키워드를 보고 특정 선수가 떠올라야하는데, 파리올림픽이나 기자는 모든 선수의 기사에 나오는 키워드이기 때문에 불필요하다고 판단할 수 있었습니다.
#2차 불용어 삭제
df['filtered_tokens'] = df['content_token'].map(lambda x: [word for word in x if word not in stopwords])이렇게 전처리를 한 후, 앞서 이야기한 키워드를 뽑는 3가지 방법을 각각 적용해보았습니다. 이 중 제가 맡은 Word2Vec에 집중하여 정리해보겠습니다.
Methods
n-gram
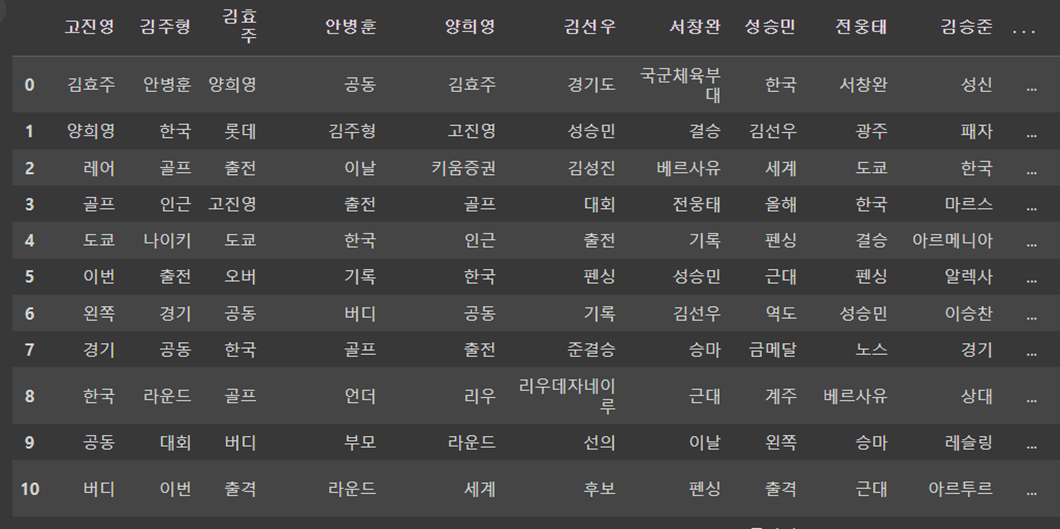 사진은 bigram 기반으로 뽑은 키워드들입니다.
사진은 bigram 기반으로 뽑은 키워드들입니다.
동시등장행렬
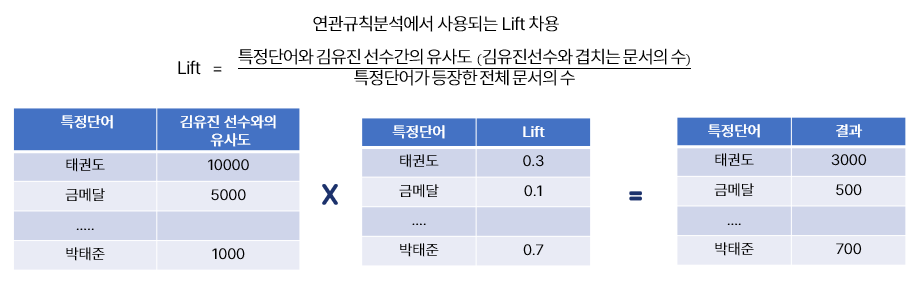
여기에는 Lift 개념을 도입해주었습니다. 왜냐하면, 특정 선수와 함께 많이 등장하는 단어가 궁금한 것이지, 모든 문서에 많이 등장하는 단어가 궁금한 것이 아니었기 때문입니다.
 사진은 Lift 개념을 도입하여 도출한 키워드입니다.
사진은 Lift 개념을 도입하여 도출한 키워드입니다.
Word2Vec
Word2Vec은 앞서 이야기한 것처럼, 일반적으로 성능이 더 좋다고 알려진 skip-gram을 사용해주었습니다. 쉽게 이야기하면, 선수 이름으로부터 주변 단어를 예측하는 방법입니다.
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
model = Word2Vec(sentences = df['filtered_tokens'], # sentences = 사용할 데이터/토큰
vector_size = 150, # vector size = 워드 벡터의 특징 값/임베딩 된 벡터의 차원
window = 3, # window = 컨텍스트 윈도우 크기
min_count = 5, # min_count =단어 최소 빈도 수 제한
workers = 4, # wokers = 학습을 위한 프로세스 수
sg = 1 # sg: 0 = CBOW, 1 = Skip-gram
)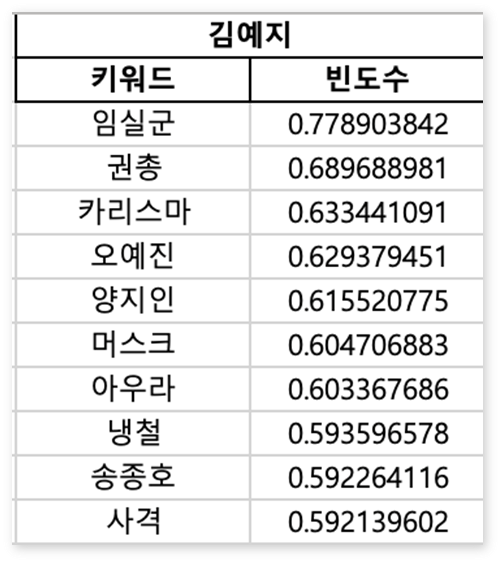 사진은 Word2Vec으로 도출된 키워드입니다. Word2Vec의 단어들은 선수 이름을 대체할 수 있는 단어들이 뽑힌 것으로 이해할 수 있습니다.
사진은 Word2Vec으로 도출된 키워드입니다. Word2Vec의 단어들은 선수 이름을 대체할 수 있는 단어들이 뽑힌 것으로 이해할 수 있습니다.
이렇게 3가지 방식으로 키워드를 뽑아보았지만, 게임을 만드는 데는 어려운 점 2가지가 있었는데요, 그 부분에 관해 이야기해보겠습니다.
Problem
두 가지 문제점은 키워드 정의 와 난이도 설정 이었습니다. 이 둘을 분리해서 설명하기보다 함께 설명해보겠습니다.
저희는 게임을 만드는 것이 목적이었기 때문에, 난이도와 재미 모두 필요했습니다. 그래서 이 부분에 관해 많은 고민을 했습니다.
우선, 키워드는 명사가 되어야하며 키워드를 보고 선수이름을 유추할 수 있는 단어가 되어야 했습니다. 그래서 3가지 방식으로 일단 뽑은 것이죠.
n-gram, 동시등장행렬, Word2Vec 중에 쉬운 난이도는 무엇일까? 를 고민해보았는데, 결론은 방식에 따라 난이도를 나눌 수 없다였습니다. 직관적으로, 빈도 수와 유사도가 높다고 해서 쉬운 난이도는 아니었기 때문이죠. 예시를 들어보겠습니다.
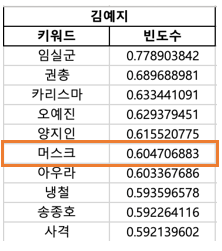 일론 머스크는 김예지 선수와 유사도가 비교적 낮은 단어이지만, 우리는 쉽게 일론 머스크에서 김예지 선수를 유추해낼 수 있습니다. 따라서, 유사도라는 기준 하나로 난이도를 설정할 수 없는 것입니다.
일론 머스크는 김예지 선수와 유사도가 비교적 낮은 단어이지만, 우리는 쉽게 일론 머스크에서 김예지 선수를 유추해낼 수 있습니다. 따라서, 유사도라는 기준 하나로 난이도를 설정할 수 없는 것입니다.
결론은...
3가지 방식으로 뽑힌 키워드를 보고, 직접 선정한다! 입니다..
사실 게임이니 재밌어야하고, 사람이 판단하는 것이 난이도 설정에 가장 알맞는 방식이라 생각했습니다. 따라서, 모든 선수에 대해 진행하지 않고, 선정한 선수들에 대해 키워드를 뽑아 게임을 만들었습니다.
Result

이런 식으로 구현해보았습니다.
처음으로 자연어처리에 관한 프로젝트를 진행해본 것이라, 같이 공부하며 적용해본 것이 재밌었습니다. 데이터 수집부터 구현까지 모두 해보았던 토이 프로젝트라 의미있었습니다. 약간 비효율적이라 생각이 들 수 있는 키워드 선정 과정 또한, 고민하는 과정에서 많은 것을 얻었다 생각합니다. 또한, 개인적으로 딥러닝에 흥미를 느낄 수 있었던 프로젝트라 좋았습니다.
