
🍮 참고 링크 - 강동희 님 글
개요
React를 사용하면서 마주치는 이슈 중 하나는 state(상태) 관리이다.
원래 React에서 상태 관리를 하려면 Redux를 활용하며
서버 데이터를 활용할 때는 반드시 Redux-saga, Redux-Thunk, RTK-Query 같은 또 다른 미들웨어를 사용해야 했다.
1. 캐싱(Caching)
react-query의 장점 중 하나는 데이터를 캐싱한다는 것이다.
캐싱된 데이터로 API 콜을 줄여주며, 이는 서버에 대한 부하 감소로 이어진다.
기본적으로 데이터를 fetching 해오면 react-query는 캐싱한다.
해당 데이터가 stale이라고 판단되면 refetching 해온다.
stale한 상태란 것은 쉽게 말해서 유통기한이 지난 것이다.
캐싱은 유용하면서도 위험한 기술이다.
서버 데이터를 fetching하고 캐싱한 뒤 사용자가 해당 데이터를 확인할 때
만약 이 과정 도중 서버에서 데이터 상태가 변경되면 사용자가 잘못된 데이터를 확인할 수 있기 때문이다.
✨ 브라우저에서 사용자가 최신 데이터를 바라봐야 하는 상황은 ?
- (기본적으로) 페이지를 보고 있을 때
- 새로운 페이지로 이동했을 때
- 클릭 이벤트 등으로 새로운 데이터를 요청했을 때
위의 3가지 경우를 제외하고는
사용자 입장에서는 굳이 신선한(fresh) 데이터가 아니어도 된다.
아래는 react-query가 기본으로 제공하고 있는 옵션들이다.
refetchOnWindowFocus, // default: true
refetchOnMount, // default: true
refetchOnReconnect, // default: true
staleTime, // default: 0
cacheTime, // default: 5 minutes (60 * 5 * 1000 = 30000)즉, react-query가 데이터를 refetch 해오는 상황은
- 브라우저 윈도우에 포커스가 들어온 경우 (refetchOnWindowFocus)
- 컴포넌트가 새로 mount된 경우 (refetchOnMount)
- 네트워크가 끊어졌다가 다시 연결된 경우 (refetchOnReconnect)
위와 같은 react-query의 컨셉으로 사용자는 항상 fresh한 데이터를 볼 수 있게 된다.
2. staleTime과 cacheTime의 차이
🥣 이 항목의 참고 링크
react-query의 라이프 사이클
- A 쿼리 인스턴스가 mount 됨
- 네트워크에서 데이터를 fetch하고 쿼리 키 A로 캐싱함
fresh상태에서staleTime이후stale상태로 변경됨 (기본값: 0 = fetch 되자마자stale됨)- A 쿼리 인스턴스가 unmount 됨
- 캐시는
cacheTime만큼 유지되다가 Garbage Collector가 수집 (기본값: 5분) staleTime이 지난 후 +cacheTime이 지나기 전에 A 쿼리 인스턴스가 새롭게 mount되면 데이터를 다시 fetch해오고,fresh한 값을 가져오는 동안 화면에는 캐시한 데이터를 보여줌
staleTime
- 데이터가 fetch 후
fresh한 상태에서stale상태로 변경되는데 걸리는 시간 - 데이터가
fresh한 상태일 때는 쿼리 인스턴스가 새롭게 mount되어도 refetch가 일어나지 않는다
cacheTime
- react-query는 기본적으로 fetch한 데이터를 바로 캐싱한다.
- 데이터를 fetch한 후 캐싱이 유지되는 시간 (기본 5분)
- 쿼리 인스턴스가 unmount되면 데이터는
inactive상태로 변경되지만, 해당 데이터의 캐시는cacheTime만큼 유지된다. cacheTime이 지나면 GC가 수집cacheTime이 지나기 전에 쿼리 인스턴스가 다시 mount되면, 데이터를 fetch하는 동안 캐시 데이터를 보여준다.cacheTime은staleTime과 관계없이, 무조건inactive된 시점을 기준으로 캐시 데이터 삭제 여부를 결정한다.
3. 클라이언트 데이터와 서버 데이터의 분리
Redux, Recoil은 클라이언트에서 전역 상태를 관리하면서, 서버 데이터가 있는 경우 middleware를 붙여 관리한다. 이 과정에서 boiler-plate가 비대해지는 부작용이 발생한다.
react-query를 활용하면 이들이 본연의 역할에만 집중할 수 있도록 서버 데이터와 클라이언트 데이터 관리를 분리하게 해준다.
클라이언트의 전역 데이터(global state)는 어떤 것들이 있을까?
- 화면에서 단계별로 입력받는 값들 (예: 설문 조사, 회원 가입 등)
- 값을 입력받은 후 나중에 저장된 값을 활용해야 하는 데이터들
서버를 거치느냐, 브라우저에만 국한되느냐로 구분 가능
(게임으로 치자면 싱글 플레이 vs. 멀티 플레이)
기존에 Redux를 활용하여 서버 데이터 관리를 할 때는 redux-saga를 사용하는 과정에서 API 요청의 성공/실패 로직을 Redux에서 다루면서 store와 boiler-plate가 비대해졌다.
하지만 react-query를 사용하면 이러한 로직을 클라이언트에서 완전히 분리할 수 있다.
react-query에서 서버 데이터의 성공을 처리하는 모습

useQueries를 활용하여 서버 데이터를 핸들링하고 있다.
그 외 사용
react-query 사용 시, 서버 데이터를 recoil에 전달하여 전역 상태(global State)로 활용하는 것도 가능하다.
recoil 코드
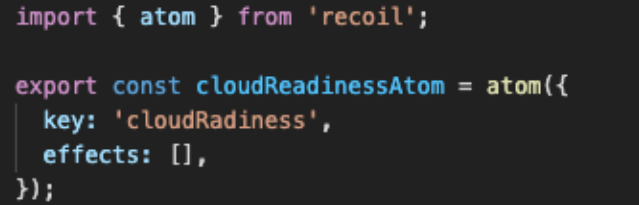
react-query 코드
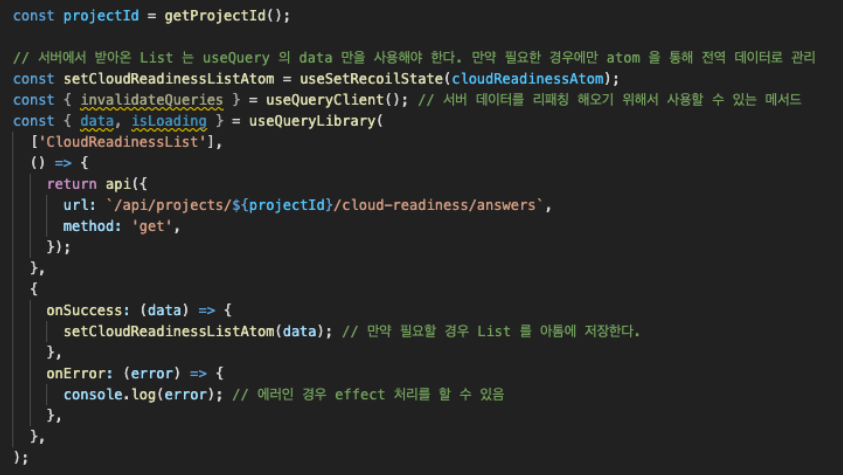
위 코드는 데이터를 성공적으로 불러왔을 때(onSuccess), 불러온 서버 데이터를 recoil에 셋팅해주고 있다.
4. Success 혹은 Error 상황을 최상단에서 핸들링하기
success, error를 공통으로 핸들링하고 싶다면 최상위 index.tsx에서 QueryClient의 defaultOptions의 queries를 이용하여 핸들링할 수 있다.

recoil을 추가하여 success/error 공통 처리하기
예를 들어 요청에 대한 응답이 실패일 때 error 코드를 recoil의 atom으로 핸들링 하는 경우이다.
위의 코드는 onError 로직이 최상단 index.tsx 에 위치하여 atom을 호출할 hook을 사용할 수 없다.
이러한 경우 app.tsx를 활용하여 다음과 같이 작성할 수 있다.
import { useQueryClient } from "react-query";
import { useRecoilState } from "recoil";
import { errorAtom } from "./common/atom";
import Router from "./Router";
function App() {
const [error, setError] = useRecoilState(errorAtom);
const queryClient = useQueryClient();
queryClient.setDefaultOptions({ // 메서드로도 defaultOptions 설정 가능
queries: {
onError: (err) => {
// 공통 error를 atom의 setError에 전달해준다
setError((prev) => [...prev, (err as any).message as string]);
},
},
});
return (
<>
{error.length !== 0 &&
error.map((err, index) => {
return <div key={index}>{err}</div>;
})}
<Router /> // 라우터 자리 (React)
</>
);
}추가: react-query에서 코드가 괜찮은데 에러가 나는 경우
원인: destructure 때문일 수 있음
예시
잘 되던 invalidateQueries가 발표에서 작동하지 않았던 경우
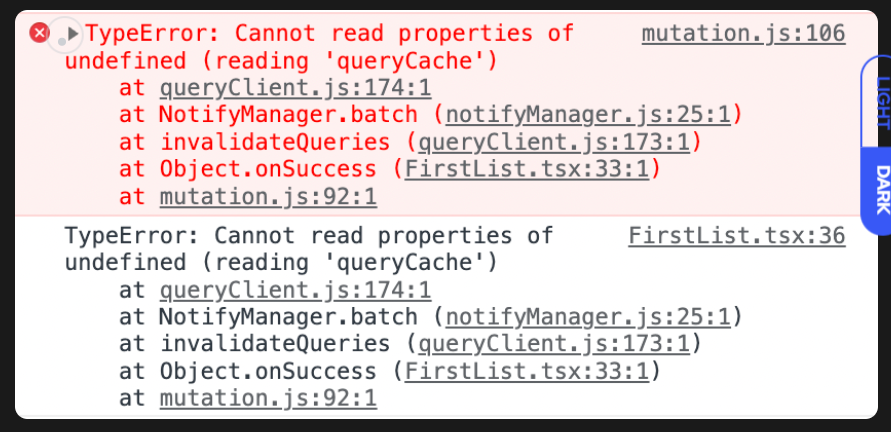
원인: invalidateQueries를 Destructured 구조로 꺼내서 사용했기 때문이었다
// 에러가 났던 코드
const { invalidateQueries } = useQueryClient();
const { mutate } = useMutation(postPersonInList, {
onSuccess: () => {
invalidateQueries(KEY_LIST);
},
onError: (error) => {
console.log(error);
},
});// 수정 후 코드
const queryCache = useQueryClient();
const { mutate } = useMutation(postPersonInList, {
onSuccess: () => {
queryCache.invalidateQueries(KEY_LIST);
},
onError: (error) => {
console.log(error);
},
});destructure 구문을 쓰지 않고 작성하니 문제가 해결되었다.
가끔 틀리지 않은 것 같은 코드에서 에러가 난다면 destructure를 하지 말고 작성해보자.
(destructure를 하면 위의 경우처럼 다른 콜백 함수 안에서 사용 못하게 되는 상황이 발생할 수 있다)
react-query의 가벼운 문제점
react-query가 가진 조그만 문제점은 기존에 Redux와 Redux-saga를 통해서 다뤘던 코드들이 '컴포넌트 안'으로 들어옴으로써 기존 코드에 비해서 컴포넌트가 무거워질 수 있다는 점이다.
이 코드를 잘 분리해서 사용할 방법을 찾아야 할 것이다.
