머신러닝 알고리즘 종류
1. 지도학습 (Supervised Learning)
한 세트의 사례들을(examples) 기반으로 예측을 수행
- 분류(Classification) : 예측해야할 데이터가 범주형(categorical) 변수일때 분류 라고 함
- 회귀(Regression) : 예측해야할 데이터가 연속적인 값 일때 회귀 라고 함
- 예측(Forecasting) : 과거 및 현재 데이터를 기반으로 미래를 예측하는 과정 예를 들어 올해와 전년도 매출을 기반으로 내년도 매출을 추산하는 것.
2. 비지도학습 (Unsupervised Learning)
비지도 학습을 수행할 때 기계는 미분류 데이터만을 제공 받음
- 클러스터링 : 특정 기준에 따라 유사한 데이터끼리 그룹화함
- 차원축소 : 고려해야할 변수를 줄이는 작업, 변수와 대상간 진정한 관계를 도출하기 용이
3. 강화학습 (Reinforcement Learning)
학습하는 시스템을 에이전트라고 하고, 환경을 관찰해서 에이전트가 스스로 행동하게 함. 모델은 그 결과로 특정 보상을 받아 이 보상을 최대화하도록 학습
- Monte Carlo methods
- Q-Learning
- Policy Gradient methods
-> 라벨(정답)의 존재 유무에 따라 머신러닝을 지도학습과 비지도학습으로 나눈다
-> 구현하고자 하는 Application에 따라 합쳐서 사용될 수도 있다.
특정 알고리즘
- 선형회귀
- 로지스틱 회귀
- 트리
- 앙상블트리 (랜덤포레스트, 그래디언트 부스팅)
- 신경망 & 딥러닝을 사용하는 알고리즘
- K평균
- K모드
- 가우시안혼합모델 클러스터링
- DBSCAN
- 계층적 군집화
- PCA
- SVD
- LDA
Scikit-learn
알고리즘은 파이썬 클래스로 구현되어 있고, 데이터셋은 NumPy의 ndarray, Pandas의 DataFrame, SciPy의 Sparse Matrix를 이용해 나타낼 수 있다. 훈련과 예측 등 머신러닝 모델을 다룰 때는 CoreAPI라고 불리는 fit(), transfomer(), predict()과 같은 함수들을 이용한다.
Scikit-learn 알고리즘 Task
Classification, Regression, Clustering, Dimensionality Reduction
알고리즘을 나눈 기준
데이터 수량
라벨의 유무(정답의 유무)
데이터의 종류 (수치형 데이터(quantity), 범주형 데이터(category) 등)
주요 사용 모듈(API)
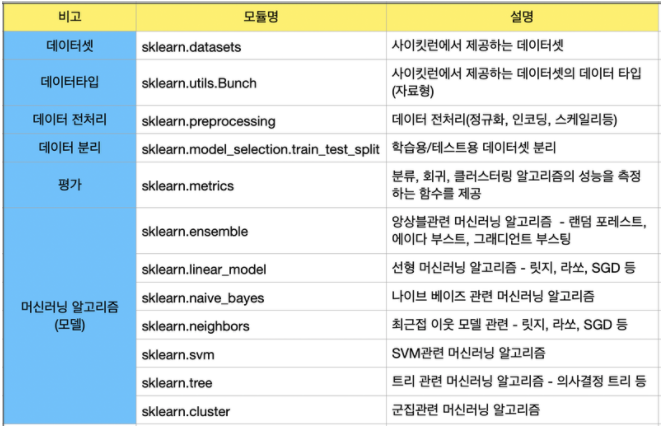
데이터 표현법
특성 행렬(Feature Matrix)
- 입력 데이터를 의미합니다.
- 특성(feature): 데이터에서 수치 값, 이산 값, 불리언 값으로 표현되는 개별 관측치를 의미합니다. 특성 행렬에서는 열에 해당하는 값입니다.
- 표본(sample): 각 입력 데이터, 특성 행렬에서는 행에 해당하는 값입니다.
- n_samples: 행의 개수(표본의 개수)
- n_features: 열의 개수(특성의 개수)
- X: 통상 특성 행렬은 변수명 X로 표기합니다.
- [n_samples, n_features]은 [행, 열] 형태의 2차원 배열 구조를 사용하며 이는 - NumPy의 ndarray, Pandas의 DataFrame, SciPy의 Sparse Matrix를 사용하여 나타낼 수 있습니다.
타겟 벡터(Target Vector)
- 입력 데이터의 라벨(정답) 을 의미합니다.
- 목표(Target): 라벨, 타겟값, 목표값이라고도 부르며 특성 행렬(Feature Matrix)로부터 예측하고자 하는 것을 말합니다.
- n_samples: 벡터의 길이(라벨의 개수)
- 타겟 벡터에서 n_features는 없습니다.
- y: 통상 타겟 벡터는 변수명 y로 표기합니다.
- 타겟 벡터는 보통 1차원 벡터로 나타내며, 이는 NumPy의 ndarray, Pandas의 Series를 사용하여 나타낼 수 있습니다.
(단, 타겟 벡터는 경우에 따라 1차원으로 나타내지 않을 수도 있습니다. 이 노드에서 사용되는 예제는 모두 1차원 벡터입니다.)
-> 특성 행렬 X의 n_samples와 타겟 벡터 y의 n_samples는 동일해야함.
회귀 모델 실습
머신러닝의 회귀 모델을 이용해 데이터를 예측하는 모델
#데이터 모양 확인
import numpy as np
import matplotlib.pyplot as plt
r = np.random.RandomState(10)
x = 10 * r.rand(100)
y = 2 * x - 3 * r.rand(100)
plt.scatter(x,y)
x.shape #입력데이터 x모양 확인
>(100.0) #1차원 벡터
y.shape #정답데이터 y모양 확인
>(100.) #1차원 벡터#모델 객체 생성 및 훈련
from sklearn.linear_model import LinearRegression #sklearn.linear_model 안에 LinearRegression 모델 객체 생성
model = LinearRegression()
model
X = x.reshape(100,1) #reshape()사용해 x를 행렬로 바꿔야함. 변수 X에 특성행렬 넣기
model.fit(X,y) #fit()메서드로 훈련. fit()메서드에 인자로 특성행렬화 타겟벡터를 넣어줌(행렬형태의 입력데이터, 1차원 벡터 형태의 정답(라벨))#새로운 데이터 넣어 예측하기
x_new = np.linspace(-1, 11, 100) #새로운 데이터 np.linspace()로 생성
X_new = x_new.reshape(100,1)
y_new = model.predict(X_new) #예측 predict() 인자 행렬x넣기#모델 성능 평가
from sklearn.metrics import mean_squared_error
error = np.sqrt(mean_squared_error(y,y_new))
print(error)데이터 뜯어보기
#와인분류 데이터 import
from sklearn.datasets import load_wine
data = load_wine()
type(data)
data.keys()
>dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names']) #data key값들data key값 의미
1. data
data.data #특성행렬
data.data.shape #모양 확인
> (178, 13) #특성이 13개, 데이터가 178개인 특성행렬
data.data.ndim #차원 확인
>2 #2차원2. target
data.target #타겟벡터
data.target.shape
>(178.0) #특성행렬(data) 데이터수와 일치함3. feature_names (특성)
data.feature_names #data에서 알아낸 13개의 특성 이름 확인
len(data.feature_names) #len()내장함수 사용해서 feature개수세기4. target_names
data.target_names #분류하고자 하는 대상
>array(['class_0', 'class_1', 'class_2'], dtype='<U7') #데이터를 각각 class_0, class_1, class_2로 분류한다.5. DESCR
print(data.DESCR) #describe특성 행렬을 Pandas의 DataFrame으로 나타내기
import pandas as pd
pd.DataFrame(data.data, columns=data.feature_names)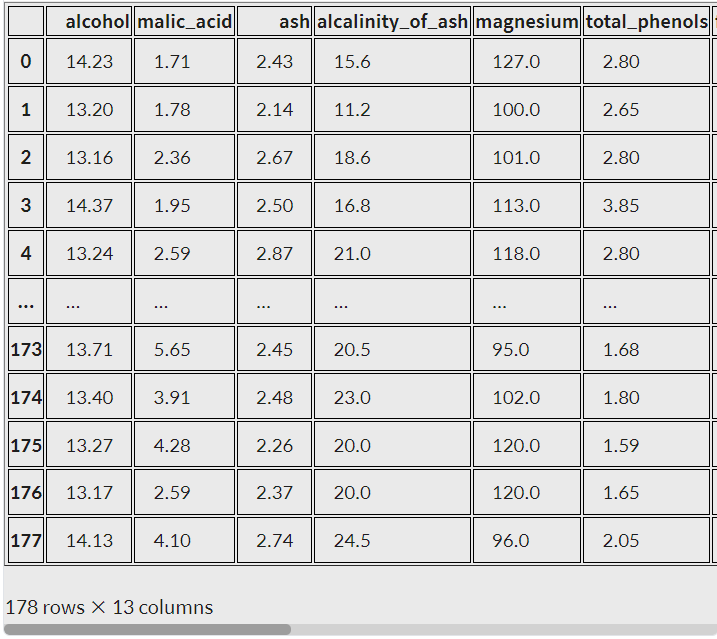
머신러닝 모델 예측
X = data.data #특성행렬data 변수X에 저장
y = data.target #타겟벡터target y에 저장from sklearn.ensemble import RandomForestClassifier #(1)랜덤포레스트분류모델 import
model = RandomForestClassifier()
model.fit(X, y) #(2)훈련
y_pred = model.predict(X) #(3)예측
#($)성능평가
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
#타겟 벡터 즉 라벨인 변수명 y와 예측값 y_pred을 각각 인자로 넣습니다.
print(classification_report(y, y_pred))
#정확도를 출력합니다.
print("accuracy = ", accuracy_score(y, y_pred))train_test_split()
model_selection의 train_test_split() 함수 사용해 훈련데이터 테스트데이터 분리
from sklearn.model_selection import train_test_split
result = train_test_split(X, #인자로 특성행렬X
y, #인자로 타겟벡터y
test_size=0.2, #테스트데이터비율20%인 0.2
random_state=42) #임의 랜덤번호
print(type(result))
print(len(result))
><class 'list'>
4 #4개의 원소로 이루어진 list반환#4개의 list
result[0].shape #훈련 데이터용 특성 행렬
result[1].shape #테스트 데이터용 특성 행렬
result[2].shape #훈련 데이터용 타겟 벡터
result[3].shape #테스트 데이터용 타겟 벡터
#위 함수를 다시 unpacking
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2,
random_state=42)정리
# 데이터셋 로드하기
# data = load_wine()
# 훈련용 데이터셋 나누기
X_train, X_test, y_train, y_test = train_test_split(data.data,
data.target,
test_size=0.2)
# 훈련하기
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 예측하기
y_pred = model.predict(X_test)
# 정답률 출력하기
print("정답률=", accuracy_score(y_test, y_pred))