시퀀스(Sequence)
나열된 데이터를 의미. 각 요소들이 동일한 속성을 띌 필요가 없으며, 어떤 기준에 따라 정렬되어 있지 않아도 됨.
각 요소들의 연관성을 의미하는 것은 아니지만, 인공지능이 예측을 하려면 어느 정도는 연관성이 있어줘야 한다.
ex) [ 18.01.01, 18.01.02, 18.01.03, ? ] 의 "?" 부분을 맞추기 위해선 정답이 18.01.04 여야만 함. 정답이 "오리"라면 난감
순환신경망(RNN)
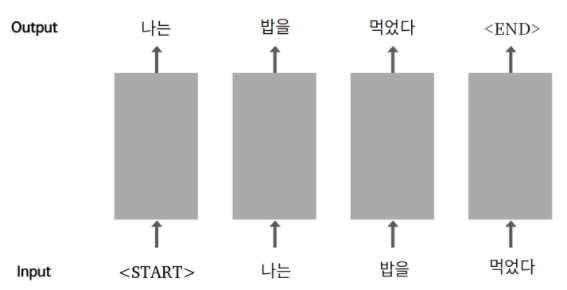
'start'를 입력으로 받은 순환신경망은 다음 단어로 '나는'을 생성하고, 생성한 단어를 다시 입력으로 사용함
'밥을' '먹었다' 까지 생성하고 나면, 다 만들었다는 의미로 'end' 라는 특수한 토큰 생성
'start'가 문장의 시작에 더해진 입력 데이터(문제지)와, 'end' 가 문장의 끝에 더해진 출력 데이터(답안지)가 필요하며, 이는 문장 데이터만 있으면 만들어낼 수 있음
sentence = " 나는 밥을 먹었다 "
source_sentence = "<start>" + sentence
target_sentence = sentence + "<end>"
print("Source 문장:", source_sentence)
print("Target 문장:", target_sentence)
>> Source 문장: <start> 나는 밥을 먹었다
Target 문장: 나는 밥을 먹었다 <end>언어 모델 (Language Model)
n−1개의 단어 시퀀스 w1,... ,wn-1이 주어졌을 때, n번째 단어 wn으로 무엇이 올지 예측하는 확률 모델
'나는 밥을 먹었다' 라는 문장 중 밥을 뒤에는 먹었다가 연상되지만, 나는 뒤에 밥을이 나올 것이라는 것은 억지처럼 느껴짐
'나는 밥을' 다음에 '먹었다' 가 나올 확률이 p(먹었다 | 나는, 밥을)라면, '나는' 뒤에 '밥이' 가 나올 확률인 p(밥을 | 나는) 보다는 높게 나올 것
연극 대사를 학습해서 스스로 연극 대사 문장을 생성해내는 인공지능 실습
텐서플로우 데이터 전처리
#실습에 사용할 라이브러리 불러오기
import os, re
import numpy as np
import tensorflow as tf
# 파일을 읽기모드로 열고
# 라인 단위로 끊어서 list 형태로 읽어옵니다.
file_path = os.getenv('HOME') + '/aiffel/lyricist/data/shakespeare.txt'
with open(file_path, "r") as f:
raw_corpus = f.read().splitlines()
# 앞에서부터 10라인만 화면에 출력해 볼까요?
print(raw_corpus[:9])
>>['First Citizen:', 'Before we proceed any further, hear me speak.', '', 'All:', 'Speak, speak.', '', 'First Citizen:', 'You are all resolved rather to die than to famish?', '']문장(대사)만 필요하고, 화자와 공백은 필요 없는 정보
- 화자가 표기된 문장인 'First Citizen:'은 문장의 끝이 :로 끝나기 때문에, :기준 문장 제외
- 공백인 문장은 길이를 검사하여 길이가 0이라면 제외
for idx, sentence in enumerate(raw_corpus):
if len(sentence) == 0: continue # 길이가 0인 문장은 건너뜁니다.
if sentence[-1] == ":": continue # 문장의 끝이 : 인 문장은 건너뜁니다.
if idx > 9: break # 일단 문장 10개만 확인해 볼 겁니다.
print(sentence)
>> Before we proceed any further, hear me speak.
Speak, speak.
You are all resolved rather to die than to famish?토큰화(Tokenize) : 문장을 일정한 기준으로 쪼개기
토큰화 과정에서 일어날 수 있는 문제점
-
Hi, my name is John. *("Hi," "my", ..., "john." 으로 분리됨) - 문장부호
-> 문장 부호 양쪽에 공백을 추가 -
First, open the first chapter. *(First와 first를 다른 단어로 인식) - 대소문자
-> 모든 문자들을 소문자로 변환 -
He is a ten-year-old boy. *(ten-year-old를 한 단어로 인식) - 특수문자
-> 특수문자들은 모두 제거
# 정제함수를 통해 문제가 되는 상황 방지
def preprocess_sentence(sentence):
sentence = sentence.lower().strip() # 소문자로 바꾸고, 양쪽 공백을 지웁니다
sentence = re.sub(r"([?.!,¿])", r" \1 ", sentence) # 특수문자 양쪽에 공백을 넣고
sentence = re.sub(r'[" "]+', " ", sentence) # 여러개의 공백은 하나의 공백으로 바꿉니다
sentence = re.sub(r"[^a-zA-Z?.!,¿]+", " ", sentence) # a-zA-Z?.!,¿가 아닌 모든 문자를 하나의 공백으로 바꿉니다
sentence = sentence.strip() # 다시 양쪽 공백을 지웁니다
sentence = '<start> ' + sentence + ' <end>' # 문장 시작에는 <start>, 끝에는 <end>를 추가합니다
return sentence
# 이 문장이 어떻게 필터링되는지 확인해 보세요.
print(preprocess_sentence("This @_is ;;;sample sentence."))
>> <start> this is sample sentence . <end>소스 문장(Source Sentence) : 모델의 입력이 되는 문장, X_train < start >
타겟 문장(Target Sentence) : 정답 역할을 하게 될 모델의 출력 문장, y_train < end >
#정제 데이터 구축하기
# 여기에 정제된 문장을 모을겁니다
corpus = []
for sentence in raw_corpus:
# 우리가 원하지 않는 문장은 건너뜁니다
if len(sentence) == 0: continue
if sentence[-1] == ":": continue
# 정제를 하고 담아주세요
preprocessed_sentence = preprocess_sentence(sentence)
corpus.append(preprocessed_sentence)
# 정제된 결과를 10개만 확인해보죠
corpus[:10]
>>['<start> before we proceed any further , hear me speak . <end>',
'<start> speak , speak . <end>',
'<start> you are all resolved rather to die than to famish ? <end>',
'<start> resolved . resolved . <end>',
'<start> first , you know caius marcius is chief enemy to the people . <end>',
'<start> we know t , we know t . <end>',
'<start> let us kill him , and we ll have corn at our own price . <end>',
'<start> is t a verdict ? <end>',
'<start> no more talking on t let it be done away , away ! <end>',
'<start> one word , good citizens . <end>']
#데이터 정제 완료벡터화(vectorize) : 정제된 데이터를 토큰화하고, 단어 사전(vocabulary 또는 dictionary라고 칭함)을 만들어주며, 데이터를 숫자로 변환 하는 과정
텐서(tensor) : 숫자로 변환된 데이터(정수)
#텐서 데이터 생성
# 토큰화 할 때 텐서플로우의 Tokenizer와 pad_sequences를 사용
def tokenize(corpus):
# 7000단어를 기억할 수 있는 tokenizer를 만들겁니다
# 우리는 이미 문장을 정제했으니 filters가 필요없어요
# 7000단어에 포함되지 못한 단어는 '<unk>'로 바꿀거에요
tokenizer = tf.keras.preprocessing.text.Tokenizer(
num_words=7000,
filters=' ',
oov_token="<unk>"
)
# corpus를 이용해 tokenizer 내부의 단어장을 완성합니다
tokenizer.fit_on_texts(corpus)
# 준비한 tokenizer를 이용해 corpus를 Tensor로 변환합니다
tensor = tokenizer.texts_to_sequences(corpus)
# 입력 데이터의 시퀀스 길이를 일정하게 맞춰줍니다
# 만약 시퀀스가 짧다면 문장 뒤에 패딩을 붙여 길이를 맞춰줍니다.
# 문장 앞에 패딩을 붙여 길이를 맞추고 싶다면 padding='pre'를 사용합니다
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor, padding='post')
print(tensor,tokenizer)
return tensor, tokenizer
tensor, tokenizer = tokenize(corpus)
#3번째 행, 10번째 열까지만 출력하기
print(tensor[:3, :10])
#단어사전 구축 인덱스 확인
for idx in tokenizer.index_word:
print(idx, ":", tokenizer.index_word[idx])
if idx >= 10: break
#생성된 텐서를 소스와 타겟으로 분리해 모델 학습
# tensor에서 마지막 토큰을 잘라내서 소스 문장을 생성합니다
# 마지막 토큰은 <end>가 아니라 <pad>일 가능성이 높습니다.
src_input = tensor[:, :-1]
# tensor에서 <start>를 잘라내서 타겟 문장을 생성합니다.
tgt_input = tensor[:, 1:]
print(src_input[0])
print(tgt_input[0])
#데이터셋 객체 생성
BUFFER_SIZE = len(src_input)
BATCH_SIZE = 256
steps_per_epoch = len(src_input) // BATCH_SIZE
# tokenizer가 구축한 단어사전 내 7000개와, 여기 포함되지 않은 0:<pad>를 포함하여 7001개
VOCAB_SIZE = tokenizer.num_words + 1
# 준비한 데이터 소스로부터 데이터셋을 만듭니다
# 데이터셋에 대해서는 아래 문서를 참고하세요
# 자세히 알아둘수록 도움이 많이 되는 중요한 문서입니다
# https://www.tensorflow.org/api_docs/python/tf/data/Dataset
dataset = tf.data.Dataset.from_tensor_slices((src_input, tgt_input))
dataset = dataset.shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
dataset데이터셋 생성 과정
- 정규표현식을 이용한 corpus 생성
- tf.keras.preprocessing.text.Tokenizer를 이용해 corpus를 텐서로 변환
- tf.data.Dataset.from_tensor_slices()를 이용해 corpus 텐서를 tf.data.Dataset객체로 변환
인공지능 학습
class TextGenerator(tf.keras.Model):
def __init__(self, vocab_size, embedding_size, hidden_size):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_size)
self.rnn_1 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.rnn_2 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.linear = tf.keras.layers.Dense(vocab_size)
def call(self, x):
out = self.embedding(x)
out = self.rnn_1(out)
out = self.rnn_2(out)
out = self.linear(out)
return out
embedding_size = 256 # 워드 벡터의 차원수, 즉 단어가 추상적으로 표현되는 크기
hidden_size = 1024 #모델에 얼마나 많은 일꾼을 둘 것인가
model = TextGenerator(tokenizer.num_words + 1, embedding_size , hidden_size)embedding size : 값이 커질수록 단어의 추상적인 특징들을 더 잡아낼 수 있지만, 그만큼 충분한 데이터가 주어지지 않으면 오히려 혼란만을 야기할 수 있다.
hidden size : 일꾼들은 모두 같은 데이터를 보고 각자의 생각을 가지는데, 역시 충분한 데이터가 주어지면 올바른 결정을 내리겠지만 그렇지 않으면 배가 산으로 갈 뿐임
# 데이터셋에서 데이터 한 배치만 불러오는 방법입니다.
# 지금은 동작 원리에 너무 빠져들지 마세요~
for src_sample, tgt_sample in dataset.take(1): break
# 한 배치만 불러온 데이터를 모델에 넣어봅니다
model(src_sample)
>> <tf.Tensor: shape=(256, 20, 7001), dtype=float32, numpy=
array([[[ 5.83257679e-05, -1.68639715e-04, -1.45609301e-05, ...,
1.53794041e-04, -2.68195232e-04, -5.49237157e-05],
[-7.37701703e-05, -1.11784342e-04, -1.62877259e-05, ...,
8.51511722e-05, -4.83886542e-04, 1.25712497e-04],
[ 1.08889049e-04, 3.64355365e-05, 1.33626367e-04, ...,
1.04474260e-04, -1.98515001e-04, 4.14576760e-04],
#생략
dtype=float32)> shape=(256, 20, 7001)
- 256 : 이전 스텝에서 지정한 배치 사이즈, dataset.take(1)를 통해서 1개의 배치, 즉 256개의 문장 데이터를 가져온 것
- 20 : 데이터셋의 max_len이 20으로 맞춰져 있었음
- 7001 : Dense 레이어의 출력 차원수. 7001개의 단어 중 어느 단어의 확률이 가장 높을지를 모델링해야 하기 때문
model.summary()
>>Model: "text_generator"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) multiple 1792256
_________________________________________________________________
lstm (LSTM) multiple 5246976
_________________________________________________________________
lstm_1 (LSTM) multiple 8392704
_________________________________________________________________
dense (Dense) multiple 7176025
=================================================================
Total params: 22,607,961 #모델의 파라미터 사이즈
Trainable params: 22,607,961
Non-trainable params: 0
_________________________________________________________________우리의 모델은 입력 시퀀스의 길이를 모르기 때문에 Output Shape를 특정할 수 없음
#모델 학습하기
# optimizer와 loss등은 차차 배웁니다
# 혹시 미리 알고 싶다면 아래 문서를 참고하세요
# https://www.tensorflow.org/api_docs/python/tf/keras/optimizers
# https://www.tensorflow.org/api_docs/python/tf/keras/losses
# 양이 상당히 많은 편이니 지금 보는 것은 추천하지 않습니다
optimizer = tf.keras.optimizers.Adam()
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction='none'
)
model.compile(loss=loss, optimizer=optimizer)
model.fit(dataset, epochs=30)평가하기
def generate_text(model, tokenizer, init_sentence="<start>", max_len=20):
# 테스트를 위해서 입력받은 init_sentence도 텐서로 변환합니다
test_input = tokenizer.texts_to_sequences([init_sentence])
test_tensor = tf.convert_to_tensor(test_input, dtype=tf.int64)
end_token = tokenizer.word_index["<end>"]
# 단어 하나씩 예측해 문장을 만듭니다
# 1. 입력받은 문장의 텐서를 입력합니다
# 2. 예측된 값 중 가장 높은 확률인 word index를 뽑아냅니다
# 3. 2에서 예측된 word index를 문장 뒤에 붙입니다
# 4. 모델이 <end>를 예측했거나, max_len에 도달했다면 문장 생성을 마칩니다
while True:
# 1
predict = model(test_tensor)
# 2
predict_word = tf.argmax(tf.nn.softmax(predict, axis=-1), axis=-1)[:, -1]
# 3
test_tensor = tf.concat([test_tensor, tf.expand_dims(predict_word, axis=0)], axis=-1)
# 4
if predict_word.numpy()[0] == end_token: break
if test_tensor.shape[1] >= max_len: break
generated = ""
# tokenizer를 이용해 word index를 단어로 하나씩 변환합니다
for word_index in test_tensor[0].numpy():
generated += tokenizer.index_word[word_index] + " "
return generatedgenerate_text : 모델에게 시작 문장을 전달하면 모델이 시작 문장을 바탕으로 작문을 진행
#문장 생성 함수 실행
generate_text(model, tokenizer, init_sentence="<start> he")
안녕하세요! 혹시 마지막 코드가 정상적으로 출력되시나요? 따라 작성해 봤는데 keyerror가 떠서요...