BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019
BERT
Goal :
Propose powerful pretrained LM for general language representation
Challenge :
- unidirectional LM restrict the power of pre-trained representations
conditional objectives are not for bidirectional approach
Solutions:
bidirectional LM
Method
- transformer encoder as LM
- pre-train by MLM, NSP
Evaluation:
- performance evaluation on GLUE(General Language Understanding Evaluation), SQuAD(Stanford Question Answering Dataset) and SWAG(Situations With Adversarial Generations)
- Effect of Pre-training tasks (~ Ablation) , Model Size
- Compare with feature-based approach on NER task
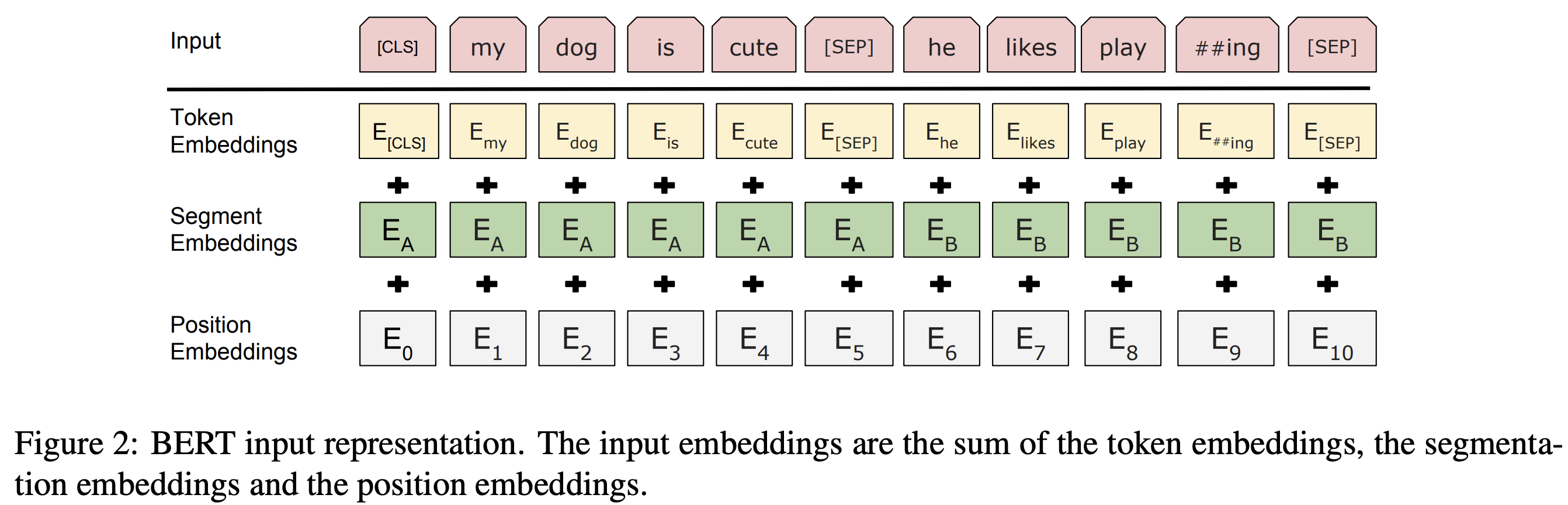
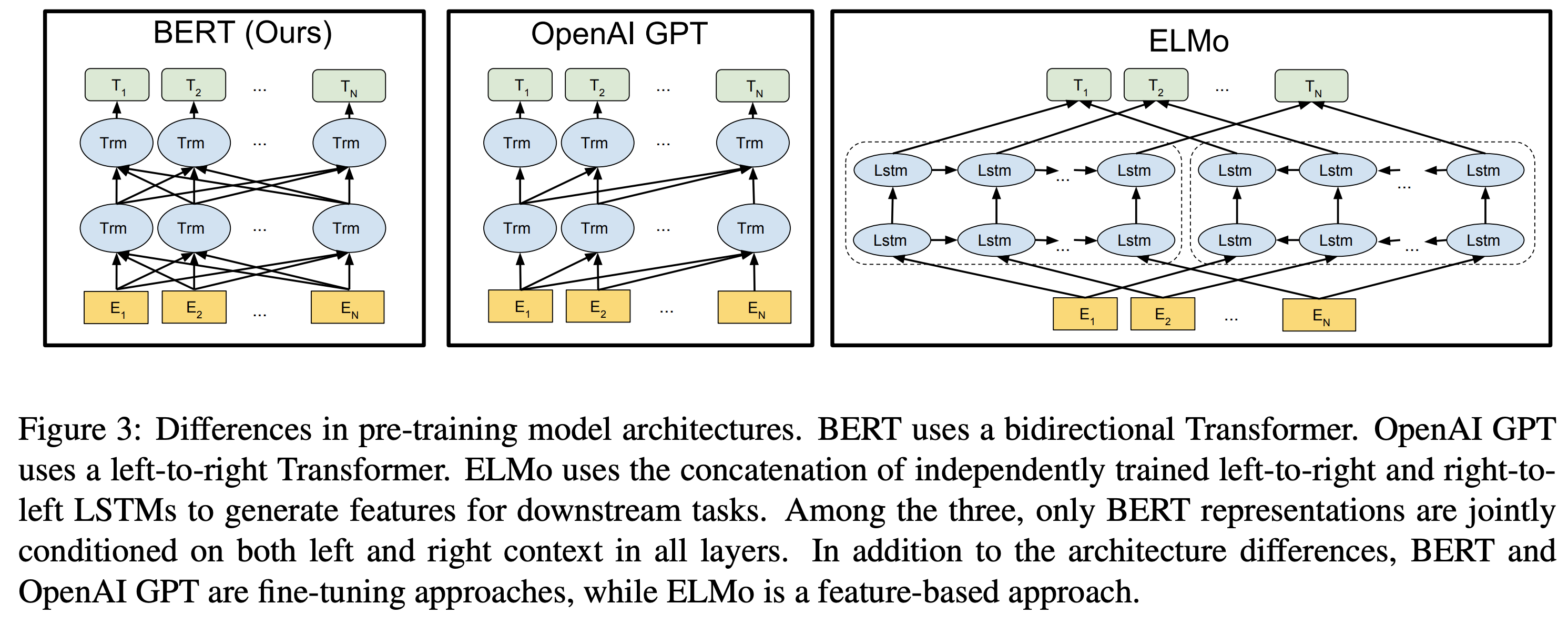
Etc.
- decoder는 내부에 masked attention(subsequent positions을 attenting 할 수 없도록 masking ex. t스텝에 t+1스텝 이후의 포지션들을 못 보도록 masking)을 해서 BERT가 원하는 방식대로 MLM을 할 수 없어서 encoder를 사용한 것 같다

신비한 AI 나라의 소시민