[Paper Review]
CogLTX: Applying BERT to Long Texts Ding et al, NeurIPS 2020
CogLTX는 서두에 이런 질문을 던진다.
How do human beings Cognize Long TeXts?
어떻게 인간은 긴 텍스트를 인지하는가?
CogLTX 는 이런 질문을 던지면서 시작을 하는데, 던지는 질문에서 짐작할 수 있듯이, 이 논문은 인간이 긴 텍스트를 받아들이는 그 인지 과정 자체를 모사해서 머신에 이를 적용하려는 시도를 하고 있다. 그래서 너무나 매력적이게도, 인간의 cognitive process에 대해서 간단하게 소개를 하면서 그 서문을 연다.
먼저 인간의 cognitive system에는 working memory라는 것이 존재하고, 이 working memory를 통해서 logical reasoning이나 decision making이 가능하게 된다고 한다. 보통의 경우에, 책을 한 권 읽었을 때 책 안의 모든 내용을 전부 다 기억하기는 힘들고, 중요한 부분만 기억에 남아있을 겁니다. 또, 읽는 도중에는, 한번에 기억할 수 있는 working memory의 용량이 한 번에 단어가 5~9개 정도이다.
그렇다면, 사람은 긴 텍스트를 어떻게 이해했다 라고 말을 할 수 있는건지에 대한 질문을 던지는데,
“The central executive – the core of the (working memory) system that is responsible for coordinating (multi-modal) information”, and “functions like a limited-capacity attentional system capable of selecting and operating control processes and strategies”, as Baddeley [2] pointed out in his 1992 classic.
Later research detailed that the contents in the working memory decay over time [5], unless are kept via rehearsal [3], i.e. paying attention to and refreshing the information in the mind. Then the overlooked information is constantly updated with relevant items from long-term memory by retrieval competition [52], collecting sufficient information for reasoning in the working memory.
cognitive science 연구들에 따르면, 인간의 working memory에는 앞서 말씀 드렸듯이 한계가 있고, 중요한 정보를 selecting 하고, 여러가지 정보를 coordinating 하는 core system이 working memory 안에 존재한다. 이 안에서는, 아무리 머릿 속으로 복기(rehearsal)를 한다고 해도 잊어버리는 (decay) 정보들이 존재하고, long term memory로 유지하기 위해선 relevant 한 정보들을 retrieval competition을 통해서 계속 분별해낼 줄 알아야하고, 이를 통해서 충분한 정보를 기반으로 reasoning을 해야 한다 라고 주장한다. 이 논문에서는 machine도 이와 비슷하다 라고 주장한다. 예를 들어 large size pretrained language model, 특히 BERT 기반 모델에 집중을 해서 말을 하고 있다. BERT에서 예를 들면, BERT base 모델을 예시로 들자면, input size가 512 token으로 제한이 되어있다. 이 논문에선 BERT의 이런 길이 제한이, working memory 의 capacity에 한계가 있는 것과 비슷하다 라는 것에서 시작한다. 인간 조차도 기억할 수 있는 양에 한계가 있는 것처럼, machine도 마찬가지다 라고 주장하는 것이다.
Challenge of Long Text
- Sliding Window, Simplifying transformers
1) Lack of long-distance attention
2) Memory consumption

일반적으로 BERT 같은 large scale LM을 사용하면서 long text를 처리하는 방법은 보통 sliding window 방식이 가장 흔히 사용되고 있는 방법이다. 예를들어, 전체 text 를 512 토큰만큼 여러개의 블록으로 나누고, 각각에서 얻은 정보를 pooling을 해서 이 전체 text에 대한 최종적인 표현을 얻는 방식인데, 여기 예시에서 보면,
어떤 question과 text가 주어졋을 때, 이 question에 대한 정답 span이 어딨는지를 맞추려면
이 빨간색 Quality Cafe와 Todd Phillips가 연관이 있다는 사실을 인지해야 한다. 근데 이렇게, key sentneces들이 text 처음과 끝에, 멀리 떨어져있는 경우에는 앞서 언급한 sliding window 방식으로는 각 단어 사이에 attention을 구할 수가 없어서, 문제를 해결하는데 조금 어려움이 있을 수 있다. (각 블록 별로 latent 표현을 얻고, 그걸 aggregation해서 pooling하는 방식이기 때문에) 그래서 이런 문제를 해결하면서 Long text를 잘 처리해서 주어진 task 를 잘 해결하자 라는 목적에서 CogLTX 가 등장했다.
CogLTX
Basic Idea
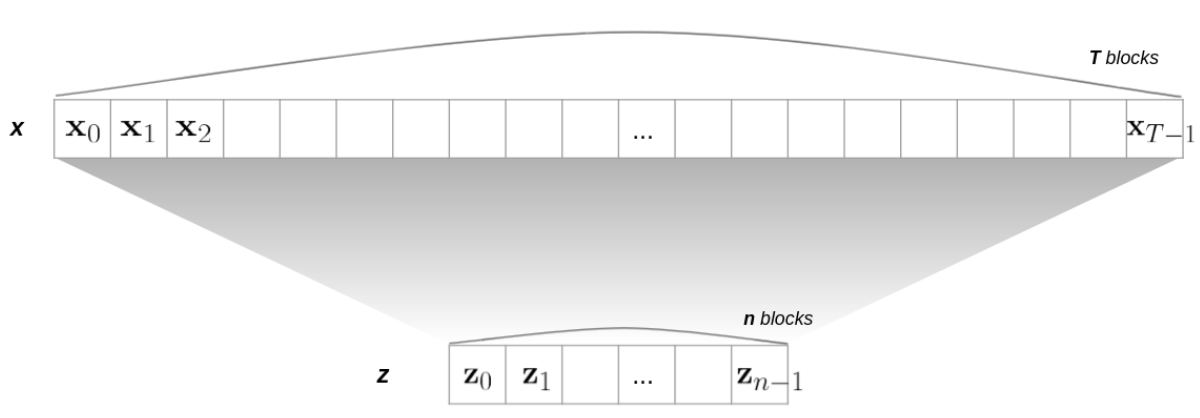
- for most NLP tasks, a few key sentences in the text store sufficient and necessary information to fulfill the task
- short text z composed by some sentences from the long text x
where and are inputs for the reasoner BERT
CogLTX의 basic idea는 ,
task를 수행하기 위해서, 정말 중요한 , task를 푸는데 도움이 되는 key sentences를 잘 골라낼 수 있다면 주어진 task를 충분히 잘 풀 수 있다는 가정이 깔려있다. 이 가정 같은 경우에는, LSTM 계열에서 long text를 다루는 selctive rnn 연구들에서 흔히 사용되는 가설이기도 하고, 여러 실험을 통해 그 효과에 대해서도 실험적으로 증명되기도 한 그런 가설이다. 그리고 이 CogLTX 논문에서도 실험을 통해서 이 가정이 가능한 가설인지를 판단한다. 전체 long text를 x라고 하고, task를 풀 때 진짜 필요한 key sentences들을 z라고 할 때, x를 대변할 수 있는 z가 존재한다. 는 것이다.
+기호가 붙은 것은 뒷부분에서 좀 더 자세히 설명을 드리겠지만, 이 논문에서는 BERT input의 형태, cls토큰과 seperator 토큰까지 포함된, BERT input 폼대로 맞춰진 상태, 그 상태를 +기호를 붙여서 나타내고 있습니다.
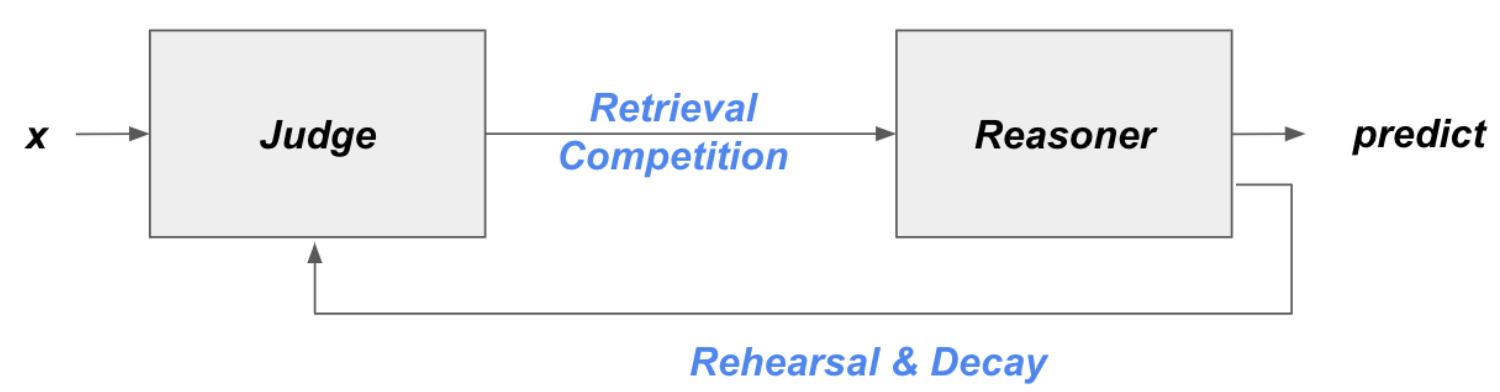
Judge & Reasoner
-
Judge Model : To score the relevance of blocks
-
Reasoner Model : Multi-step Reasoning
지금부터는 좀 더 본격적으로 method에 대한 설명을 하려고 한다. CogLTX는 judge와 Reasoner, 이렇게 크게 두가지 모듈로 나눠져 있고, 기본적으로 이 judge와 reasoner는 BERT 기반 모델이고, jointly training을 한다. judge model은 각 블록에 대해 scoring을 할 목적으로 학습이 되고, reasoner model은 main task를 수행하는 모델이다.
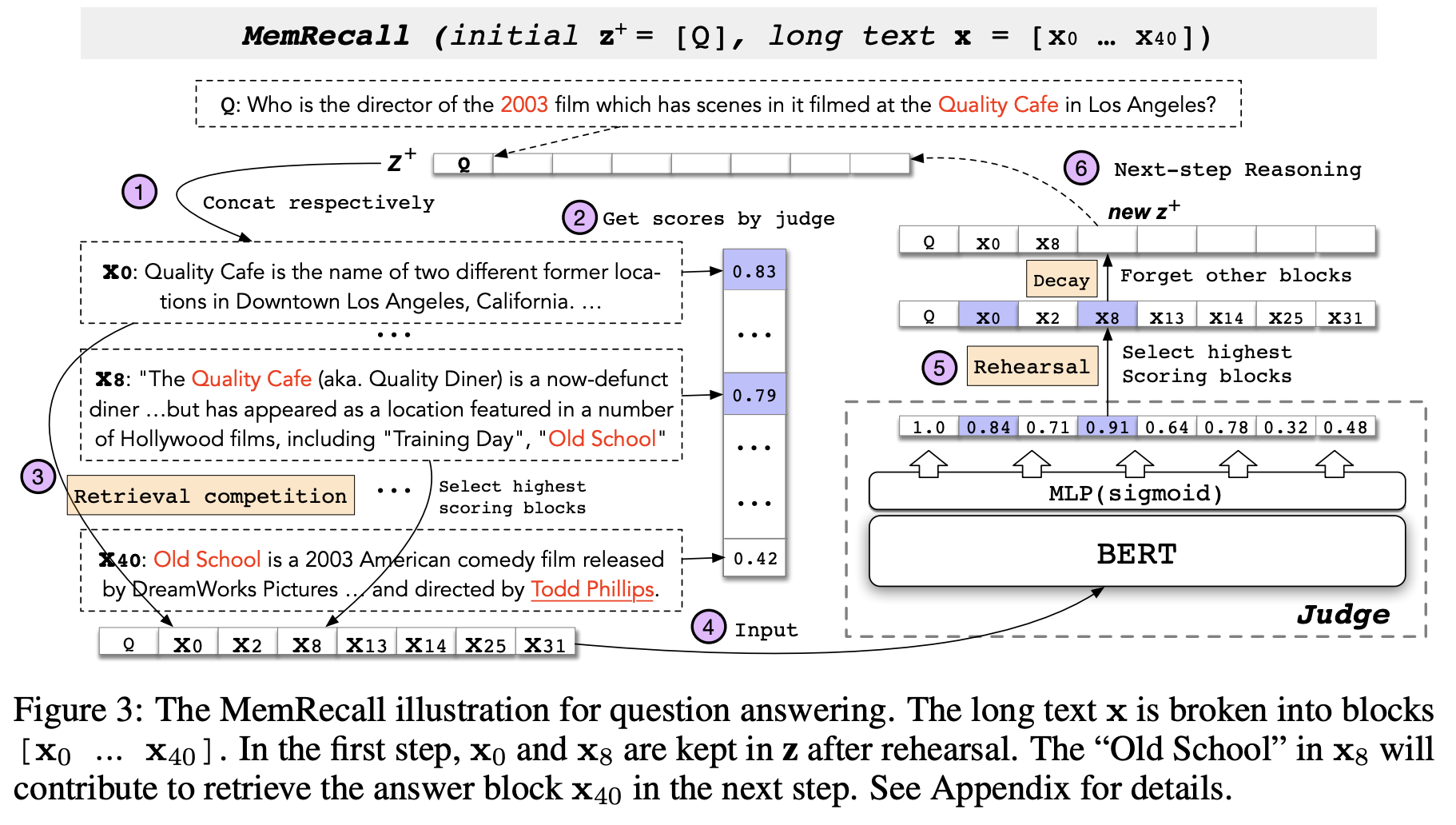
MemRecall
- The process to identify relevant text blocks by treating the blocks as episodic memories
- MemRecall imitates the working memory on retrieval competition, rehearsal and decay, facilitating multi-step reasoning.
그리고 MemRecall이라는 process가 있는데, 학습된 judge모델을 활용해서 전체 텍스트로부터 key sentence들을 잘 구성하려는 과정이다. 앞에서 cognitive system 부분에서 언급됐던 retrieval competition과 rehearsal & decay를 CogLTX에서도 반영을 하는 부분이다.
구체적으로는 아래와 같이 크게 Retrieval Competition과 rehearsal & decay가 있다.
Retrieval Competition
- coarse relevance score for each block
- winner blocks with highest scores are inserted into
Retrieval Competition 같은 경우에는 전체 long text x에서 z를 만드는 과정으로,
1. 전체 text $\textbf{x}$를 여러 블록 $x_i$ 단위로 쪼개고,
2. 각 블록 별로 scoring을 해서 (task에 얼마나 relevant 할지를 측정)
3. 점수가 높은 것부터 차례로 선택해서 $\textbf{z}$를 구성하게 된다.
4. 그리고 이 $\textbf{z}$를 갖고서 reasoner는 task를 수행을 하게 되는 것이다.Rehearsal & Decay
- fine relevance score for each
- only the highest scored blocks are kept in
rehearsal & decay는,
1. 이 $\textbf{z}$에 대해서 좀 더 자세히 다시 확인을 해보고, 다음 에폭 때는 더 개선된 z를 잘 만들어보자 라는 것이다.
2. 아까는 전체 text x를 여러개의 블록으로 쪼갰다면, 이번에는 $\textbf{z}$ 안에서만, 여러 블록들에 대해서
3. 스코어를 다시 계산해서 필요 없는 블록들은 버리고,
4. 다음 에폭 때는, 좀 더 task 랑 relevant한 블록들을 새로 뽑을 수 있도록 해보자 라는 아이디어이다.